By Mike Schroepfer, Chief Technology Officer
Facebook’s long-term roadmap is focused on building foundational technologies in three areas: connectivity, artificial intelligence and virtual reality. We believe that major research and engineering breakthroughs in each of these areas will help us make more progress toward opening the world to everyone over the next decade.
Our work in AI is helping us move all these projects forward. We’re conducting industry-leading research to help drive advancements in AI disciplines like computer vision, language understanding and machine learning. We then use this research to build infrastructure that anyone at Facebook can use to build new products and services. We’re also applying AI to help solve longer-term challenges as we push forward in the fields of connectivity and VR. And to accelerate the impact of AI, we’re tackling the furthest frontiers of research, such as teaching computers to learn like humans do — by observing the world.
Our Approach: From Research to Platforms to Production
As the field of AI advances quickly, we’re turning the latest research breakthroughs into tools, platforms and infrastructure that make it possible for anyone at Facebook to use AI in the things they build. Examples include:
- FBLearner Flow: The backbone of AI-based product development at Facebook. This platform makes AI available to everyone at Facebook for a wide variety of purposes. FBLearner Flow has helped make AI so accessible within Facebook that nearly 70% of the people using the platform here are not AI experts. With the help of the platform we’re now seeing twice as many AI experiments run per month at Facebook compared with six months ago.
- AutoML: The infrastructure that allows engineers to optimize new AI models using existing AI. Put another way: We’re training and testing more than 300,000 machine learning models each month, and AutoML can automatically apply the results of each test to other machine learning models to make them better. This eliminates work for engineers and helps us improve our AI capabilities faster.
- Lumos: A new self-serve platform that allows teams to harness the power of computer vision for their products and services without the need for prior expertise. For the teams who work to keep people on Facebook safe, this has helped improve our ability to spot content that violates our community standards.
With infrastructure like FBLearnerFlow, AutoML and Lumos, AI research is going into production at Facebook faster than ever.
AI Already Improving Facebook Products and Services
As engineers apply AI at scale, it’s already making an impact on the lives of people who use our products and services every day. AI assists in automatically translating posts for friends who speak different languages, and in ranking News Feed to show people more relevant stories. Over the next three to five years, we’ll see even more new features as AI expands across Facebook.
Even more exciting, AI can enable entirely new tools for creativity and connection. As people increasingly express themselves through video, we’ve been focused on giving people more video-first ways to share across the Facebook family of apps. As part of this, we started working on style transfer, a technology that can learn the artistic style of a painting and then apply that style to every frame of a video. This is a technically difficult trick to pull off, normally requiring that the video content be sent to data centers for the pixels to be analyzed and processed by AI running on big-compute servers. But the time required for data transfer and processing made for a slower experience. Not ideal for letting people share fun content in the moment.
Just three months ago we set out to do something nobody else had done before: ship AI-based style transfer running live, in real time, on mobile devices. This was a major engineering challenge, as we needed to design software that could run high-powered computing operations on a device with unique resource constraints in areas like power, memory and compute capability. The result is Caffe2Go, a new deep learning platform that can capture, analyze and process pixels in real time on a mobile device. We found that by condensing the size of the AI model used to process images and videos by 100x, we’re able to run deep neural networks with high efficiency on both iOS and Android. This is all happening in the palm of your hand, so you can apply styles to videos as you’re taking them. Check out our blog post to read more on how we did this.
Having an industrial-strength deep learning platform on mobile enables other possibilities too. We can create gesture-based controls, where the computer can see where you’re pointing and activate different styles or commands. We can recognize facial expressions and perform related actions, like putting a “yay” filter over your selfie when you smile. With Caffe2Go, AI has opened the door to new ways for people to express themselves.
AI Powers Innovation in VR and Connectivity for the Next Decade
AI is also making a big impact on the new technologies that will shape the next decade.
In VR, image and video processing software powered by computer vision is improving immersive experiences and helping to support hardware advances. Earlier this year we announced a new stabilization technology for 360 videos, powered by computer vision. And computer vision software is enabling inside-out tracking to help usher in a whole new category of VR beyond PC and mobile, as we announced at Oculus Connect 3 last month. This will help make it possible to build high-quality, standalone VR headsets that aren’t tethered to a PC.
Our work on speech recognition is also helping us create more-realistic avatars and new UI tools for VR. You can see a great example from our social VR demo at Oculus Connect 3, when the avatars moved their lips in sync with the speaking voices. This helps to create a feeling of presence with other people in VR. To do this, we built a custom library that maps speech signals into visemes (visual lip movement).
Speech recognition can also make it easier to interact with your environment in VR through hands-free voice commands. Our Applied Machine Learning team is working with teams across Facebook to explore more applications for social VR and the Oculus platform.
AI technologies are also contributing to our connectivity projects, including aerial systems like Aquila and terrestrial systems like Terragraph. With computer vision tools we can perform better analyses of potential deployment plans as we explore different modes of connectivity technology. This has already helped us map the world’s population density in much more accurate detail than ever before, giving us a clearer picture of where specific connectivity technologies would be most effective. And now we’re applying computer vision to 3D city analysis to help plan deployments of millimeter wave technologies like Terragraph in dense urban areas. As wireless networks become denser with increasing bandwidth demand, this automated solution lets us process more radio installation sites at a finer granularity. The system first detects possible installation sites for network equipment by separating poles from other aspects of the urban environment (trees, ground, and wires) using 3D city data. Then the AI algorithm performs line-of-sight analysis to identify radio propagation paths connecting nearby sites with clear line-of-sight. Finally, an optimization framework will use the data to automatically plan a network with optimal site and path selection to serve the bandwidth demand.
The Next Research Challenges in AI
To continue accelerating the impact of AI, we’re also investing in long-term research. In recent years, the state of AI research has advanced very quickly — but there’s still a long way to go before computers can learn, plan and reason like humans. That’s the next frontier of AI research.
Computers are quickly getting better at understanding a visual scene and identifying the objects within each frame. Even in the last few years, computer systems have advanced from basic image segmentation (drawing a box around the area where an object is located) to an ability to segment these objects more precisely and label them with information. Now, we can even apply this to video to calculate human poses in real time.
With the ability to label objects, computers can generate captions about what’s happening in a photo. This is what helps us describe photos to visually impaired people on Facebook today. But at the same time, the technology is still very early and it’s not perfect yet. Below you can see one example of where this technology worked well, followed by one where it went wrong:

And while computers can label objects more or less accurately, they still can’t take it one step further to understand the context surrounding the objects they see. For example, look at the image below this paragraph. Is that a vegetarian pizza?

It’s not. But how did you know? To come up with your answer, you first saw and identified the sausage on the pizza. Then you applied context in the form of facts and concepts that you know about the world — like, “sausage is meat” and “vegetarian means that there is no meat.” Computers can’t do this, because they don’t have contextual understanding of the world.
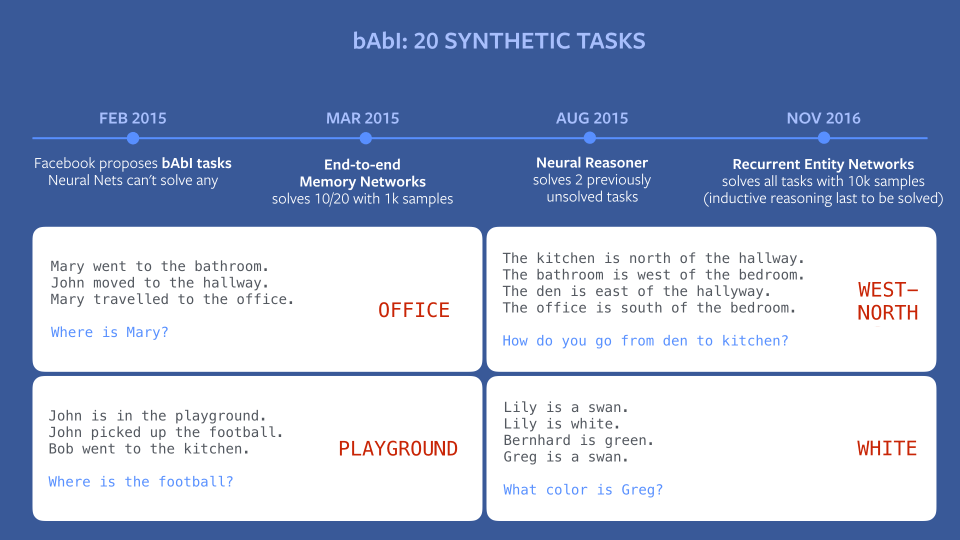
Some of our research has focused on giving computers this contextual understanding. To do this, we need to give them a model by which they can understand the world — a set of facts and concepts they can draw from in order to answer questions like the one about the pizza. We also need computers to remember multiple facts at once. In the example below, our team trained computers with structured data and Memory Networks to enable simple reasoning. A year ago, no AI system could complete tasks like the ones you see below. But progress is moving very quickly. A few months ago, we published research in which we trained computers to perform 19 out of 20 tasks correctly. And just last week, we submitted a paper for academic review that presents a new type of system, Recurrent Entity Network, that can solve all 20 tasks.
The problem is, most data is not neatly structured in the real world. So to reason more like humans, computers must be able to pick relevant facts from an unstructured source, like a Wikipedia article, and apply those facts to answering a question. It’s early, but we’re working on this with research on key value memory networks. Below is a project called WikiQ&A where we’ve trained computers to answer questions that require identifying and combining a few facts from unstructured text.
Despite this progress, there’s a lot more work required to make computer systems truly intelligent. Prediction is one important component of intelligence that humans learn naturally but computers can’t yet do. To understand this, think of holding a water bottle above the ground and letting go. What happens to the bottle?

You know that the bottle will fall. You learned this through a process called predictive learning — by forming hypotheses and testing them. As a toddler, you threw food off table, and quickly you realized that it would fall. But looking at this scenario, a computer has no ability to tell what will happen next. We’re coming up with methods that allow computers to learn by observing the world. In this example, the computer attempts to predict what will happen next in the video by observing the previous frames. This is the state-of-the-art in AI today. It’s the best prediction we’ve been able to achieve, but it’s not perfect yet. You can see that the image gets fuzzier as we advance forward in time, indicating the computer is less sure about what will happen. This area of research is very early, and there’s a long way to go, but computers can eventually learn the ability to predict the future by observing, modeling and reasoning.

It’s exciting to see how AI has progressed over such a short time, and it’s exciting to think about what’s next. When our research succeeds in teaching computers all the abilities I outlined above — context, knowledge about the world, reasoning and predicting — these will add up to something like what we call common sense. And when computers have common sense they can interact with us in better, more natural ways, from surfacing the most relevant information for us and assisting us with tasks to enabling whole new ways for people to connect. We’re off to a good start, and I can’t wait to see what tomorrow brings.
Update on December 5, 2016: Photos in blog have been updated.


