A pandemia do COVID-19 é uma emergência de saúde pública global incrivelmente complexa e em rápida evolução. O Facebook está comprometido em impedir a disseminação de informações falsas e enganosas em nossas plataformas. A desinformação sobre a doença pode evoluir tão rapidamente quanto as manchetes das notícias e pode ser difícil de distinguir de reportagens legítimas. A mesma informação incorreta pode aparecer em formas ligeiramente diferentes, como uma imagem modificada com alguns pixels cortados ou aumentados com um filtro. E essas variações podem ser não intencionais ou resultado da tentativa deliberada de alguém para evitar a detecção. Além disso, também é importante evitar a categorização incorreta de um conteúdo legítimo como desinformação, pois isso poderia impedir as pessoas de se expressarem em nossas plataformas.
A Inteligência Artificial (IA) é uma ferramenta crucial para enfrentar esses desafios e impedir a disseminação de desinformação, porque nos permite alavancar e escalar o trabalho dos verificadores de fatos independentes que revisam o conteúdo de nossos serviços. Trabalhamos com mais de 60 organizações de verificação de fatos em todo o mundo, que revisam conteúdos em mais de 50 idiomas. Desde que a pandemia começou, usamos nossos sistemas de IA atuais e implementamos novos para identificar material relacionado ao COVID-19 que nossos parceiros de verificação de fatos sinalizaram como desinformação e para depois detectar cópias quando alguém tenta compartilhá-las.
Além de detectar desinformação, nossos sistemas de IA estão nos ajudando com outros desafios relacionados à pandemia. Criamos novos classificadores de visão computacional para ajudar a implementar nossa proibição temporária de anúncios e comércio de máscaras faciais médicas, entre outros produtos. Como às vezes as pessoas modificam seus anúncios desses produtos para tentar burlar nossos sistemas, também usamos tecnologia de correspondência de conteúdo para encontrar esse tipo de mídia manipulada em escala. Em muitos casos, agimos proativamente — antes mesmo que alguém reporte a nós.
Durante o mês de abril, colocamos avisos em cerca de 50 milhões de conteúdos relacionados ao COVID-19 no Facebook, com base em cerca de 7.500 artigos de nossos parceiros independentes de verificação de fatos. Desde 1º de março, removemos mais de 2,5 milhões de conteúdos para a venda de máscaras, desinfetantes para as mãos, lenços desinfetantes e kits de teste do COVID-19. Mas esses são desafios difíceis e nossas ferramentas estão longe de serem perfeitas. Além disso, a natureza contraditória desses desafios significa que o trabalho nunca estará concluído. Neste blogpost, estamos focando na parte do nosso trabalho envolvendo visão computacional, mas solucionar esses problemas requer um extenso conjunto de ferramentas de tecnologia de IA, como compreensão de conteúdo multimodal. Temos muito mais trabalho a fazer, mas estamos confiantes de que podemos continuar desenvolvendo nossas ferramentas criadas até agora, melhorar ainda mais nossos sistemas e fazer mais para proteger as pessoas de conteúdos nocivos relacionado à pandemia.
Usando IA para maximizar o trabalho dos verificadores de fatos contra desinformação


Esses exemplos mostram cópias quase iguais de uma informação falsa, sendo a última uma captura de tela da primeira.
Qualquer pessoa pode facilmente achar que essas imagens são quase idênticas. Na verdade, de relance pode ser difícil identificar as diferenças. Os sistemas de visão computacional também podem precisar de esforço para detectar com alto grau de certeza essas correspondências, porque embora o conteúdo seja idêntico, os pixels não são. É extremamente importante que esses sistemas de similaridade sejam da maior precisão possível, porque um erro pode significar aplicar uma sanção a conteúdo que não viola nossas políticas. O exemplo abaixo mostra uma versão muito semelhante que não deve ser classificada como desinformação.

Esta imagem é muito semelhante às outras acima, mas sua legenda não contém desinformação sobre o vírus.
Quando um conteúdo é classificado como falso por nossos parceiros independentes de verificação de fatos, reduzimos sua distribuição e exibimos avisos com mais contexto (mais detalhes estão disponíveis aqui.) Como observamos anteriormente, essas etiquetas são uma ferramenta extremamente eficaz para lidar com a desinformação. Quando avisos de que uma parte do conteúdo continha informações erradas foram mostrados para as pessoas, em 95% das vezes elas não visualizaram esse conteúdo.
O SimSearchNet, um modelo baseado em rede neural convolucional, construído especificamente para detectar duplicatas quase exatas, agora está nos ajudando a fazer esse trabalho com mais eficiência. Depois que os verificadores de fatos independentes determinam que uma imagem contém alegações enganosas ou falsas sobre o coronavírus, o SimSearchNet, como parte de nosso sistema de indexação de ponta a ponta e correspondência de imagens, é capaz de reconhecer correspondências quase duplicadas para que possamos aplicar as marcações de aviso.
Isso é particularmente importante porque, para cada conteúdo de desinformação identificado pelos verificadores de fatos, pode haver milhares ou milhões de cópias. O uso de IA para detectar essas correspondências também permite que nossos parceiros de verificação de fatos se concentrem em identificar novos conteúdos com desinformação, em vez de variações quase idênticas de conteúdos que eles já viram.
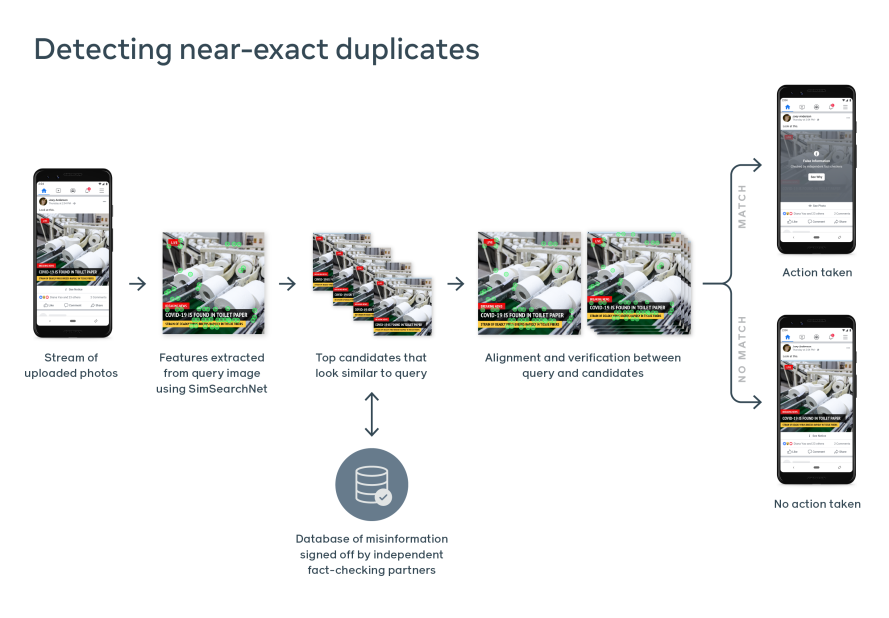
O ciclo de vida das imagens à medida que são encontradas em um banco de dados de desinformação certificada
O SimSearchNet é baseado em uma colaboração de vários anos entre pesquisadores e engenheiros do Facebook AI, e muitas outras pessoas da empresa. Foi desenvolvido após anos de pesquisa em visão computacional no Facebook – em particular, na construção de representações compactas que nos permitem indexar e pesquisar rapidamente fotos em grande escala.
O SimSearchNet também aproveita a mesma infraestrutura de correspondência em larga escala usada para detectar outros tipos de conteúdos nocivos. Esse sistema é executado em todas as imagens carregadas no Instagram e no Facebook e verifica os bancos de dados específicos feitos por curadoria humana. Isso representa bilhões de imagens sendo verificadas por dia, inclusive em bancos de dados configurados para detectar desinformação sobre o COVID-19.
Interrompendo a venda dos produtos relacionados ao COVID-19, mesmo quando as pessoas tentam evitar a detecção
Desde o início da crise, trabalhamos para proteger as pessoas daqueles que tentam explorar essa emergência para obter ganhos financeiros. Para nos ajudar a detectar e remover com mais eficiência anúncios de produtos como máscaras médicas, desinfetante para as mãos, lenços desinfetantes de superfícies e kits de teste COVID-19, implementamos um sistema que aproveita os recursos de detecção de imagem para encontrar anúncios alterados. Isso nos ajuda a impedir proativamente os anunciantes que estão tentando burlar nossa fiscalização ao enganar nosso sistema de inteligência artificial.
Esses exemplos mostram como as pessoas editam suas imagens para tentar evitar a detecção. Mantemos um banco de dados sobre o objeto extraído de anúncios relacionados ao COVID-19 que violaram nossas políticas e, em seguida, aplicamos o sistema de correspondência para verificar imagens em novos anúncios. Esta solução nos permite melhor detectar anúncios manipulados com imagens de itens emendados, tornando o sistema mais robusto contra táticas comuns de modificação, como corte, rotação, oclusão e ruídos. O sistema baseado na comparação de imagens agora está rejeitando esses anúncios automaticamente.
Também usamos correspondência de contexto para a tecnologia de data augmentation nas aplicações de políticas relacionadas ao COVID-19 em outros sistemas de integridade de anúncios. Por exemplo, ao capturar imagens cortadas de máscaras faciais que detectamos em anúncios, usamos o sistema de correspondência para identificar diversas amostras de outras imagens de máscaras médicas. Esse conjunto de dados aprimorado foi usado para treinar nosso classificador de anúncios e torná-lo mais sensível para alterações. Ao utilizar exemplos detectados pelo classificador de anúncios, podemos impedir em mais de 10 vezes a distribuição de anúncios que violam políticas para máscaras do que usando apenas a solução de correspondência.
Treinando rapidamente os modelos de visão para o Marketplace
Quando as pessoas vendem coisas pelo Marketplace, elas usam imagens com fundos, ângulos de câmera, detalhes e qualidade em geral muito diferentes. Isso pode tornar mais difícil para os sistemas de visão reconhecerem do que imagens de catálogos tiradas por um fotógrafo profissional usando fundos simples, por exemplo.
Ao longo dos anos, aproveitamos várias técnicas de adaptação de domínio para implementar centenas de modelos de classificação e detecção de objetos que têm um bom desempenho nas condições desafiadoras do mundo real. As lições desses esforços nos levaram a investir na construção de uma plataforma a partir do PyTorch que nos permite treinar e implementar rapidamente classificadores/detectores sob demanda para novas classes de imagens e vídeos. Essa plataforma utiliza o trabalho inovador em inteligência artificial do Facebook para treinar os sistemas com o DNA de bilhões de fotos com hashtags. Também emprega técnicas de data augmentation que permitem criar modelos com quantidades limitadas de dados, enquanto ainda atendem à diversidade vista nas fotos dos produtos do Marketplace.
Após o início da crise do coronavírus, utilizamos essa plataforma para treinar e implementar classificadores para máscaras faciais médicas, desinfetantes para as mãos e lenços desinfetantes. Primeiro coletamos fotos públicas desses produtos, depois ajustamos e aumentamos esse conjunto de dados. Para aumentar a precisão, também adicionamos milhares de imagens “negativas” de itens que o sistema pode confundir com uma máscara facial. Após o treinamento online e uma avaliação offline, implementamos o conceito em nossa plataforma de inferência de produção e o aplicamos retroativamente às imagens do Marketplace. Agora, esses modelos estão sendo executados globalmente em novos produtos do Marketplace.
Planejamos continuar investindo na plataforma e trabalhando para melhorar os sistemas acima, principalmente porque o ciclo de feedback nos retorna mais dados. Esses sinais também serão usados por classificadores multimodais subsequentes, que visam olhar as publicações do Marketplace de uma maneira mais holística.
Trabalhando para detectar desinformação e conteúdos nocivos
Os problemas de desinformação e as tentativas de venda de itens proibidos não começaram com a pandemia do COVID-19. Para enfrentar esses e outros desafios, o Facebook fez investimentos de longo prazo na pesquisa de sistemas de reconhecimento visual e entendimento multimodal, desenvolvendo novas técnicas de aprendizado auto-supervisionadas e construindo plataformas de deep learning que nos permitem passar rapidamente da etapa de pesquisa para a produção em escala.
Vimos como as pesquisas de ponta de alguns anos atrás já estão nos ajudando a melhorar a produção hoje. Estamos confiantes de que podemos usar novas técnicas e ferramentas de pesquisa para proteger melhor as pessoas em nossas plataformas.