

Meta has been a pioneer in AI for more than a decade. We’ve released more than 1,000 AI models, libraries, and data sets for researchers – including the latest version of our large language model, Llama 2, available in partnership with Microsoft.
At Connect 2023, we announced several new generative AI features that people can use to make the experiences they have on our platforms even more social and immersive. Our hope is that generative AI tools like these can help people in a variety of ways. Imagine a group of friends planning a trip together: In a group chat, they can ask an AI assistant for activity and restaurant suggestions. In another case, a teacher could use an AI to help create lesson plans that are customized for different learning styles of individual students.
Building this technology comes with the responsibility to develop best practices and policies. While there are many exciting and creative use cases for generative AI, it won’t always be perfect. The underlying models, for example, have the potential to generate fictional responses or exacerbate stereotypes it may learn from its training data. We’ve incorporated lessons we’ve learned over the last decade into our new features – like notices so people understand the limits of generative AI, and integrity classifiers that help us catch and remove dangerous responses. These are being done in line with industry best practices outlined in the Llama 2 Responsible Use Guide.
In keeping with our commitment to responsible AI, we also stress test our products to improve safety performance and regularly collaborate with policymakers, experts in academia and civil society, and others in our industry to advance the responsible use of this technology. We’ll be rolling these features out step by step, and launching the AIs in beta. We’ll continue to iterate on and improve these features as the technologies evolve and we see how people use them in their daily lives.
How are we building responsibly and prioritizing people’s safety?
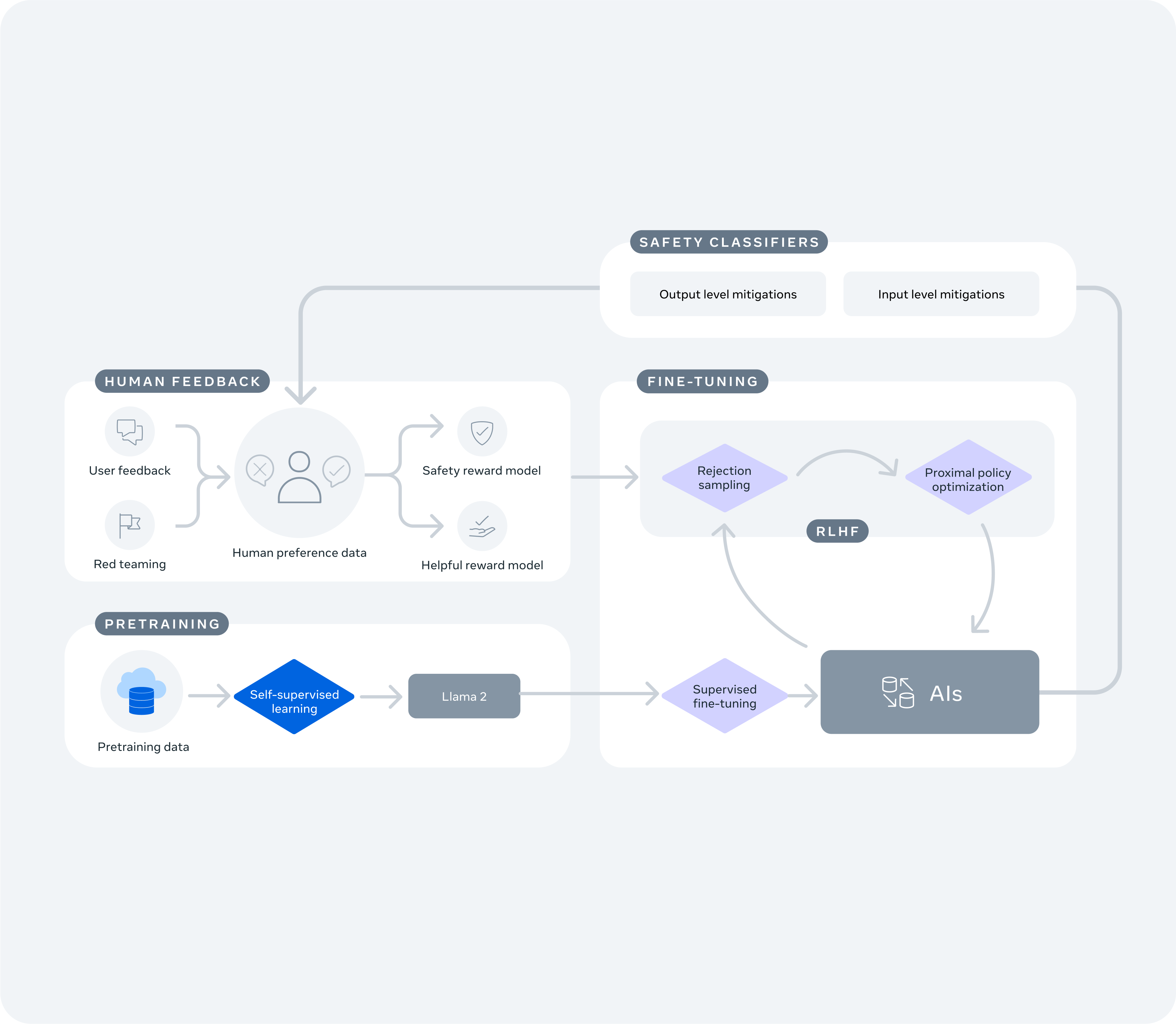
The custom AI models that power new text-based experiences like Meta AI, our large language model-powered assistant, are built on the foundation of Llama 2 and leverage its safety and responsibility training. We’ve also been investing in specific measures for the features we announced today.
We’re sharing a resource that explains in more detail the steps we’re taking to identify potential vulnerabilities, reduce risks, enhance safety, and bolster reliability. For example:
- We’re evaluating and improving our conversational AIs with external and internal experts through red teaming exercises. Dedicated teams of experts have spent thousands of hours stress-testing these models, looking for unexpected ways they might be used along with identifying and fixing vulnerabilities.
- We’re fine-tuning the models. This includes training the models to perform specific tasks, such as generating high-quality images, with instructions that can increase the likelihood of providing helpful responses. We’re also training them to provide expert-backed resources in response to safety issues. For example, the AIs will suggest local suicide and eating disorder organizations in response to certain queries, while making it clear that it cannot provide medical advice.
- We’re training our models on safety and responsibility guidelines. Teaching the models guidelines means they are less likely to share responses that are potentially harmful or inappropriate for all ages on our apps.
- We’re taking steps to reduce bias. Addressing potential bias in generative AI systems is a new area of research. As with other AI models, having more people use the features and share feedback can help us refine our approach.
- We’ve developed new technology to catch and take action on content that violates our policies. Our teams have built algorithms that scan and filter out harmful responses before they’re shared back to people.
- We’ve built feedback tools within these features. No AI model is perfect. We’ll use the feedback we receive to keep training the models to improve safety performance and automatic detection of policy violations. We’re also making our new generative AI features available to security researchers through Meta’s long-running bug bounty program.
How are we protecting people’s privacy?
We’re held accountable for protecting people’s privacy by regulators, policymakers, and experts. We work with them to ensure that what we build follows best practices and meets high standards for data protection.
We believe it’s important that people understand the types of data we use to train the models that power our generative AI products. For example, we do not use your private messages with friends and family to train our AIs. We may use the data from your use of AI stickers, such as your searches for a sticker to use in a chat, to improve our AI sticker models. You can find out more about the types of data we use in our Privacy Matters post on generative AI.
How are we making sure people know how to use the new features and understand their limitations?
We provide information within the features to help people understand when they’re interacting with AI and how this new technology works. We denote in the product experience that they might return inaccurate or inappropriate outputs.

This past year, we published 22 ‘System Cards’ to give people understandable information about how our AI systems make decisions that affect them. Today, we’re sharing new generative AI System Cards on Meta’s AI website – one for AI systems that generate text that powers Meta AI and another for AI systems that generate images for AI stickers, Meta AI, restyle, and backdrop. These include an interactive demo so people can see how refining their prompt affects the output from the models.
How are we helping people to know when images are created with our AI features?
We’re following industry best practices so it’s harder for people to spread misinformation with our tools. Images created or edited by Meta AI, restyle, and backdrop will have visible markers so people know the content was created by AI. We’re also developing additional techniques to include information within image files that were created by Meta AI, and we intend to expand this to other experiences as the technology improves. We’re not planning to add these features to AI stickers, since they are not photorealistic and are therefore unlikely to mislead people into thinking they are real.
Currently, there aren’t any common standards for identifying and labeling AI-generated content across the industry. We think there should be, so we are working with other companies through forums like the Partnership on AI in the hope of developing them.

What steps are we taking to stop people from spreading misinformation using generative AI?
AI is a key part of how we tackle misinformation and other harmful content. For example, we developed AI technologies to match near-duplications of previously fact-checked content. We also have a tool called Few-Shot Learner that can adapt more easily to take action on new or evolving types of harmful content quickly, working across more than 100 languages. Previously, we would have needed to gather thousands or sometimes even millions of examples to build a data set large enough to train an AI model, and then do the fine tuning to make it work properly. Few-Shot Learner can train an AI model based on only a handful of examples.
Generative AI could help us take down harmful content faster and more accurately than existing AI tools. We’ve started testing large language models (LLMs) by training them on our Community Standards to help determine whether a piece of content violates our policies or not. These initial tests suggest the LLMs can perform better than existing machine learning models, or at least enhance ones like Few-Shot Learner, and we’re optimistic generative AI can help us enforce our policies in the future.