

Machine translation helps bridge the language barriers between people and information — but historically, research has focused on creating and evaluating translation systems for only a handful of languages, usually the few most spoken languages in the world. This excludes the billions of people worldwide who don’t happen to be fluent in languages such as English, Spanish, Russian, and Mandarin.
We’ve recently made progress with machine translation systems like M2M-100, our open source model that can translate a hundred different languages. Further advances necessitate tools with which to test and compare these translation systems with one another, though.
Today, we are open-sourcing FLORES-101, a first-of-its-kind, many-to-many evaluation data set covering 101 languages from all over the world. FLORES-101 is the missing piece, the tool that enables researchers to rapidly test and improve upon multilingual translation models like M2M-100. We’re making FLORES-101 publicly available because we believe in breaking down language barriers, and that means helping empower researchers to create more diverse (and locally relevant) translation tools — ones that may make it as easy to translate from, say, Bengali to Marathi as it is to translate from English to Spanish today.
Why Evaluation Matters
Imagine trying to bake a cake — but not being able to taste it. It’s near-impossible to know whether it’s any good, and even harder to know how to improve the recipe for future attempts.
Evaluating how well translation systems perform has been a major challenge for AI researchers — and that knowledge gap has impeded progress. If researchers cannot measure or compare their results, they can’t develop better translation systems. The AI research community needed an open and easily accessible way to perform high-quality, reliable measurement of many-to-many translation model performance and then compare results with others.
Previous work on this problem relied heavily on translating in and out of English, often using proprietary data sets. But while this benefited English speakers, it was and is insufficient for many parts of the world where people need fast and accurate translation between regional languages — for instance, in India, where the constitution recognizes over 20 official languages.
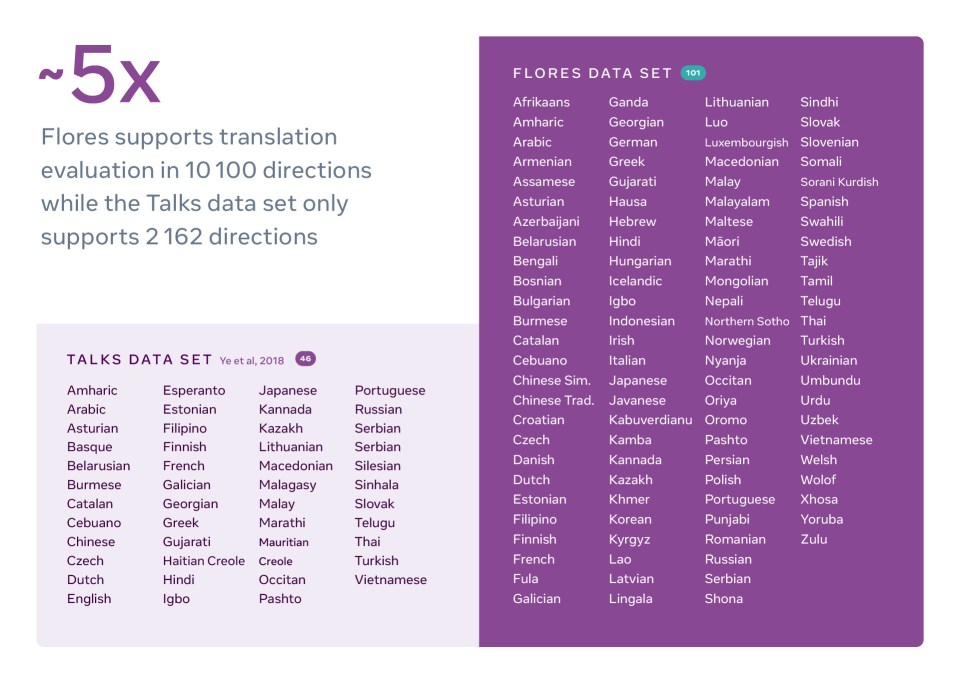
FLORES-101 focuses on what are known as low-resource languages, such as Amharic, Mongolian, and Urdu, which do not currently have extensive data sets for natural language processing research. For the first time, researchers will be able to reliably measure the quality of translations through 10,100 different translation directions — for example, directly from Hindi to Thai or Swahili. For context, evaluating in and out of English would provide merely 200 translation directions.
The flexibility exhibited by FLORES is possible because we designed around many-to-many translation from the start. The data set contains the same set of sentences across all languages, enabling researchers to evaluate the performance of any and all translation directions.
Building a Benchmark
Good benchmarks are difficult to construct. They need to be able to accurately reflect meaningful differences between models so they can be used by researchers to make decisions. Translation benchmarks can be particularly difficult because the same quality standard must be met across all languages, not just a select few for which translators are more readily available.
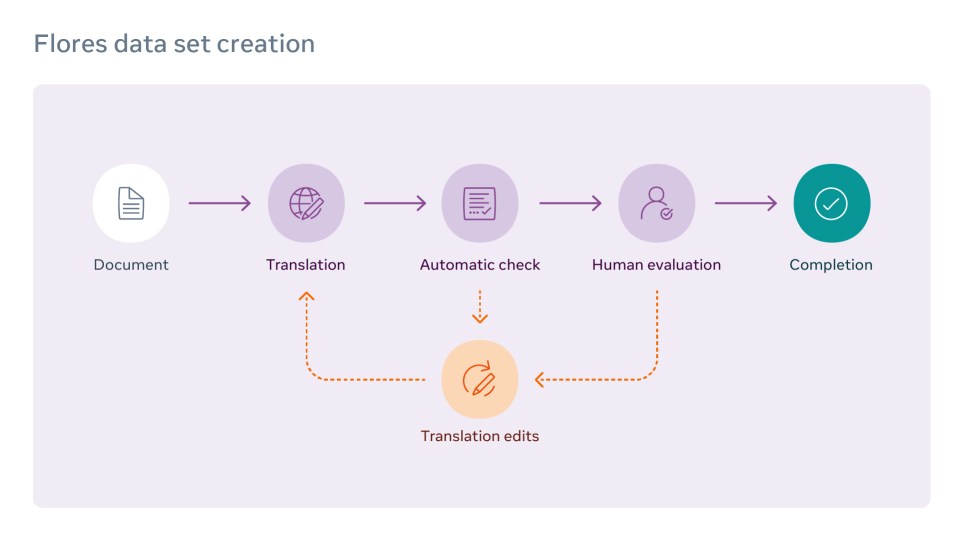
To create FLORES, each document was first translated by a professional translator, and then verified by a human editor. Next, it proceeded to the quality-control phase, including checks for spelling, grammar, punctuation, and formatting, and comparison with translations from commercial engines. After that, a different set of translators performed human evaluation, identifying errors across numerous categories including unnatural translation, register, and grammar. Based on the number and severity of the identified errors, the translations were either sent back for retranslation or — if they met quality standards — the translations were considered complete.
What’s Next
For billions of people, especially non-English speakers, language remains a fundamental barrier to accessing information and communicating freely with other people. While there have been major advances in machine translation over the past few years, both at Facebook AI Research (FAIR) and elsewhere, a handful of languages have benefited most from these efforts. If the aim is to break down these language barriers and bring people closer together, then we must broaden our horizons.
“I think [FLORES] is a really exciting resource to help improve the representation of many languages within the machine translation community,” said Graham Neubig, Professor at the Carnegie Mellon University Language Technology Institute in the School of Computer Science. “It is certainly one of the most extensive resources that I know of that covers so many languages from all over the world, in a domain of such relevance to information access as Wikipedia text.”
The release of FLORES-101 enables accurate evaluation of many-to-many models. But that’s just the start, and by making the FLORES-101 data set available, we hope researchers will be able to accelerate work on multilingual translation models like M2M-100 and develop translation models in more languages, particularly in cases that do not necessarily involve English. Together, we believe the community can make rapid progress on low-resource machine translation that will benefit people around the world.