Uno de los principales objetivos de Facebook en lo que respecta a la Inteligencia Artificial (IA) es implementar tecnología innovadora de aprendizaje automático que proteja a las personas del contenido dañino. Miles de millones de usuarios usan nuestras plataformas, motivo por el que confiamos en la IA para ampliar nuestra capacidad de revisión de contenido y automatizar las decisiones cuando sea posible. Nuestro objetivo es detectar de forma rápida y precisa el lenguaje que incita al odio, la información errónea y todas las demás formas de contenido que infringen nuestras políticas en todos los idiomas y comunidades del mundo.
Para alcanzar nuestro objetivo, necesitaremos muchos más avances técnicos en materia de IA. A pesar de esto, hemos conseguido mejoras reales y actualmente nuestros sistemas automatizados se usan como primera opción para revisar más contenido por cualquier tipo de infracción. Nuestra inversión y mejora continua se ven reflejadas en el Informe de Cumplimiento de nuestras Normas Comunitarias que hemos publicado hoy.
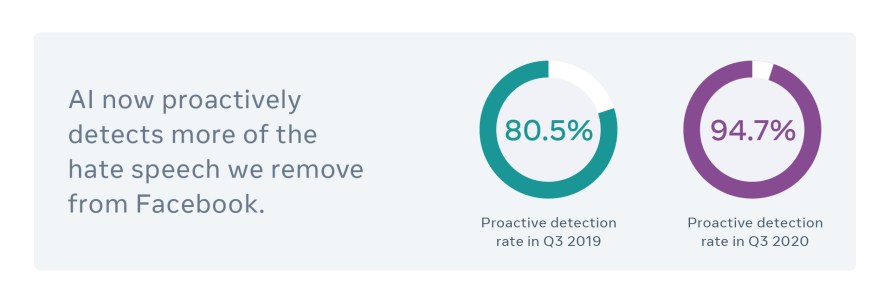
La IA ya detecta de forma proactiva 94,7% del lenguaje que incita al odio y que eliminamos de Facebook, una mejora en comparación con 80,5% de hace un año y con el 24% de 2017.
Esto ha sido posible gracias a los avances en nuestras herramientas de detección automatizadas, como la implementación de XLM, el método de Facebook AI para entrenar sistemas de lenguaje en varios idiomas sin depender de conjuntos de datos etiquetados de forma manual. Recientemente, hemos incorporado nuevos sistemas que han mejorado nuestra capacidad para detectar lenguaje que incita al odio. Entre ellos se encuentra el optimizador de integridad reforzada, un sistema que aprende de ejemplos y resultados del mundo real y nuestra arquitectura de IA de Linformer, que nos permite usar modelos innovadores de comprensión del lenguaje que antes eran demasiado grandes y difíciles de gestionar para funcionar a gran escala.
Por supuesto, el lenguaje que incita al odio no es el único contenido que tenemos que detectar. También, contamos con nuestra nueva tecnología de IA para combatir información falsa, como lo es SimSearchNet, un instrumento de comparación de imágenes que analizamos a profundidad hace unos meses para la detección de ultra falsificaciones que puede aprender y adaptarse con el tiempo.
En conjunto, todas estas innovaciones permiten que nuestros sistemas de IA puedan comprender mucho mejor el contenido que procesan. Ahora mismo, están más sensibilizadas con el contenido que las personas comparten en nuestras plataforma, de forma que se puedan adaptar rápidamente cuando aparezca un nuevo meme o foto y estos se viralicen.
Estos retos son complejos, tienen muchos matices y están en constante evolución. Es crucial no solo detectar los problemas, sino también evitar los errores, ya que clasificar contenido por equivocación, como la información errónea o el lenguaje que incita al odio, puede coartar la capacidad de las personas de expresarse en nuestra plataforma. La mejora continua necesitará no solo una mejor tecnología, sino también excelencia operativa y colaboraciones eficaces con expertos externos.
Aunque constantemente mejoramos nuestras herramientas de IA, están lejos de ser perfectas. Sabemos que queda trabajo por hacer y estamos diseñando y probando nuevos sistemas que nos ayudarán a proteger mejor a las personas que usan nuestras plataformas.
Aprendizaje integral y nuevos modelos eficaces para detectar el lenguaje que incita al odio
La detección de cierto lenguaje que incita al odio no tiene demasiada complicación para la IA ni para los humanos. Los insultos y los símbolos que incitan al odio representan ataques obvios a la raza o la religión de una persona. Sin embargo, a menudo el lenguaje que incita al odio es más complejo. La combinación de texto e imágenes dificulta la tarea de la IA para determinar si existe una intención de ofender, incluso en los casos en los que resultaría obvio para un humano. El lenguaje que incita al odio también puede disfrazarse con sarcasmo o argot, o con imágenes aparentemente inofensivas que se perciben de forma diferente según la cultura, la región o el idioma.
Para manejar mejor estos retos, hemos diseñado e implementado un nuevo marco de aprendizaje reforzado que conocemos como “Optimizador de Integridad Reforzada” (RIO, por sus siglas en inglés). En lugar de depender de un conjunto de datos estático (y, por lo tanto, limitado) fuera de la Internet, RIO usa datos de Internet, del mundo real, de nuestros sistemas de producción para optimizar los modelos de IA que detectan el lenguaje que incita al odio. RIO funciona durante todo el ciclo de vida de desarrollo del aprendizaje automático, desde el muestreo de datos hasta las pruebas A/B.
En los sistemas de IA tradicionales, los ingenieros optimizan estos pasos en dos procedimientos independientes: la optimización fuera de Internet y la experimentación en Internet. Fuera de Internet, los ingenieros pueden usar diversas herramientas que les ayudarán a elegir la combinación perfecta entre entrenamiento y pruebas, así como la neuroarquitectura adecuada. Sin embargo, se basan únicamente en resultados fuera de Internet, como la precisión y el recuerdo. El modelo se sigue optimizando fuera de Internet mediante pruebas A/B que permiten determinar la repercusión del modelo en resultados sobre usuarios y empresas en Internet.
El enfoque de RIO es completamente diferente. Optimiza todos los pasos de este proceso en conjunto y usa resultados reales de rendimiento de producción para perfeccionar los componentes fuera de Internet. Este nivel de optimización integral nos permite obtener un rendimiento significativamente mejor y realizar cambios a partir de las pruebas de forma más rápida. En lugar de tener que hacer el trabajo fuera de Internet y, a continuación, aplicarlo a la producción para comprobar que todo funciona como estaba previsto, el sistema en Internet atiende el reto real.
RIO nos permite centrar nuestro modelo de aprendizaje en infracciones de nuestra política sobre lenguaje que incita al odio que nuestros modelos de producción anteriores no llegaban a detectar.
Mediante los datos de entrenamiento adecuados de RIO, podemos usar modelos innovadores de comprensión del contenido para crear clasificadores eficaces. En los últimos años, los investigadores han mejorado de forma radical el rendimiento de los modelos de lenguaje usando Transformer, un mecanismo para enseñar a la IA sobre qué partes del texto tiene que prestar atención. Sin embargo, los modelos de Transformer más avanzados e innovadores pueden tener miles de millones de parámetros. Su gran complejidad computacional, que se suele expresar normalmente como O(N^2), implica que no son suficientemente eficaces para implementarse en la producción a escala y funcionar casi en tiempo real para detectar el lenguaje que incita al odio.
Para aumentar la eficacia de los modelos de Transformer, los investigadores de Facebook AI han desarrollado una nueva arquitectura llamada Linformer. La misma proporciona una forma mucho más eficaz de usar modelos innovadores masivos para entender el contenido. Ahora usamos RIO y Linformer en producción para analizar miles de millones de elementos de contenido de Facebook e Instagram en diferentes regiones de todo el mundo. Hemos compartido nuestro trabajo y el código de Linformer con la comunidad de investigación en materia de IA de forma que podamos contar con los avances de las demás partes y acelerar el progreso para todos.
Comprensión autosupervisada, integral y multimodal
RIO y Linformer nos ayudan a entrenar nuestros sistemas de forma más eficaz y a usar modelos avanzados de comprensión del contenido. Sin embargo, el lenguaje que incita al odio o la incitación a la violencia pueden ser algo más complejo que un simple fragmento de texto. En algunos de los ejemplos más difíciles, vemos que una parte del contenido ofensivo se expresa a través de una imagen o un video, mientras que la otra parte se expresa en texto. Si se analizan por separado, es posible que estas partes sean benignas. Sin embargo, juntas es cuando resultan ofensivas.
 Para identificar este meme como lenguaje que incita al odio, la IA debe comprender la imagen y el texto en conjunto.
Para identificar este meme como lenguaje que incita al odio, la IA debe comprender la imagen y el texto en conjunto.
Como se muestra en los ejemplos anteriores, estas situaciones requieren una comprensión integral del contenido en cuestión. A fin de hacerlo posible, hemos creado las Inserciones de Integridad de la Publicación en Conjunto (WPIE, por sus siglas en inglés), una representación universal pre-entrenada del contenido para evitar problemas de integridad. El funcionamiento de las WPIE consiste en entender los distintos tipos de infracción, las modalidades e incluso el momento de publicación del contenido. Nuestra última versión está entrenada con más infracciones y más datos en general. El sistema usa la pérdida focal para mejorar el rendimiento en diferentes modalidades, como texto e imagen. Este enfoque evita que los ejemplos fáciles de clasificar saturen el detector durante el entrenamiento. Además, la fusión de gradientes registra una combinación óptima de modalidades en función de su comportamiento de sobreajuste.
También, usamos aprendizaje autosupervisado de las publicaciones para crear una representación universal pre-entrenada del contenido para evitar problemas de integridad. Asimismo, hemos implementado XLM-R, un modelo que aprovecha nuestra innovadora arquitectura de IA RoBERTa, a fin de mejorar nuestros clasificadores de lenguaje que incita al odio en diversos idiomas tanto en Facebook como en Instagram. XLM-R ahora también forma parte de nuestro sistema para expandir el Centro de Información sobre COVID-19 a nivel internacional.
Tenemos mucho trabajo por delante. El reto de detectar el lenguaje que incita al odio no es solo complicado, sino que no deja de evolucionar. Un elemento nuevo de lenguaje que incita al odio puede no parecerse a los ejemplos anteriores porque hace referencia a una tendencia nueva o a una noticia reciente. Hemos creado herramientas como RIO y las WPIE para que puedan adaptarse tanto a los retos futuros como a los actuales. Con una IA más flexible y adaptativa, estamos seguros de que podremos seguir consiguiendo avances reales.