Jusqu’à présent, les outils de traduction reposant sur de l’intelligence artificielle (IA) étaient principalement dédiés aux langues écrites. Or, près de la moitié des 7000 langues vivantes dans le monde sont principalement orales et n’ont pas de forme écrite standard ou largement utilisée. Il est donc impossible de créer un outil de traduction automatique pour ces langues à l’aide des techniques classiques, qui nécessitent une grande quantité de texte écrit pour l’entraînement du modèle d’IA. Pour relever ce défi, nous avons créé le premier système de traduction reposant sur une IA dédiée à une langue principalement orale, le Hokkien. Le Hokkien est très largement utilisé au sein de la diaspora chinoise, mais il n’a pas de forme écrite standard. Notre technologie permet aux locuteurs du Hokkien de tenir une conversation avec des anglophones.
Ce système de traduction développé en open source fait partie du projet Universal Speech Translator (UST) de Meta. Il a pour objectif de développer de nouvelles méthodes basées sur l’IA qui, nous l’espérons, permettront à terme la traduction directe en temps réel de toutes les langues, même celles qui sont essentiellement des langues parlées (c’est-à-dire non écrites). Nous croyons que la communication orale permet de faire tomber les barrières et de créer du lien entre les personnes, où qu’elles se trouvent, y compris dans le métavers.
Pour mettre au point ce nouveau système de traduction uniquement oral, nos chercheurs en IA ont dû relever de nombreux défis par rapport aux systèmes de traduction automatique traditionnels, notamment en matière de collecte de données, de conception de modèles et d’évaluation. Beaucoup de progrès restent à faire avant de pouvoir étendre l’UST à d’autres langues. Toutefois, la possibilité de parler facilement à des personnes dans n’importe quelle langue est un rêve de longue date, et nous sommes heureux de nous rapprocher de cet objectif. Nous mettons en open source non seulement nos modèles de traduction en Hokkien, mais aussi l’ensemble des données d’évaluation et les documents de recherche, afin que d’autres puissent reproduire et développer notre travail.
Surmonter les défis liés aux données d’entraînement
La collecte de données en quantité suffisante a été un obstacle de taille lors du développement du système de traduction dédié au Hokkien. En effet, le Hokkien est une langue aux ressources peu nombreuses. Elle ne bénéficie donc pas d’une vaste base de données d’entraînement immédiatement accessibles, comme c’est le cas pour l’espagnol ou pour l’anglais par exemple. De plus, les traducteurs de l’anglais vers le Hokkien sont relativement rares, ce qui complique la collecte et l’annotation de données pour l’entraînement du modèle.
Nous avons utilisé le mandarin comme langue intermédiaire pour créer des traductions semi-supervisées et humaines, en traduisant d’abord de l’anglais (ou du Hokkien) vers le mandarin, puis du mandarin vers le Hokkien (ou l’anglais), avant d’ajouter ces traductions aux données d’entraînement. Cette méthode a énormément amélioré les performances du modèle en utilisant les données d’une langue similaire disposant de ressources en grande quantité.
L’analyse vocale est une autre méthode de génération de données d’entraînement. Grâce à un encodeur vocal pré-entraîné, nous avons pu encoder des intégrations vocales en Hokkien dans le même espace sémantique que d’autres langues, sans avoir à faire appel à une forme écrite du Hokkien. Les paroles en Hokkien peuvent être alignées avec les paroles et le texte en anglais dont les intégrations sémantiques sont similaires. Nous avons ensuite synthétisé les paroles en anglais à partir de textes, créant ainsi un alignement de paroles en Hokkien et en anglais.
Une nouvelle approche de modélisation
De nombreux systèmes de traduction vocale reposent sur des transcriptions ou sont des systèmes de conversion du discours oral en texte. Cependant, puisque les langues principalement orales n’ont pas de forme écrite standard, il n’est pas possible de générer une traduction sous la forme d’un texte transcrit. Ainsi, nous nous sommes concentrés sur la traduction de parole à parole.
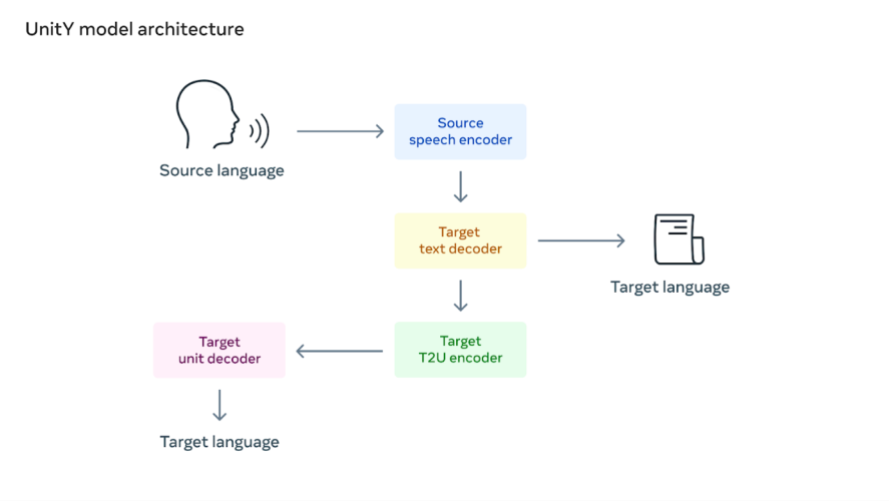
Nous avons utilisé la méthode de traduction parole-unité (S2UT) pour convertir directement les entrées vocales en une séquence d’unités acoustiques selon l’approche toute récente développée par Meta. Nous avons ensuite généré des ondes à partir des unités. De plus, UnitY a été utilisé comme système de décodage en deux étapes. Le premier décodeur génère du texte dans une langue similaire (le mandarin), et le deuxième crée des unités.
Évaluer l’exactitude
Les systèmes de traduction vocale sont généralement évalués à l’aide d’un indicateur appelé ASR-BLEU. Pour cela, la parole traduite est d’abord convertie en texte en utilisant la reconnaissance vocale automatique (ASR), puis des scores BLEU (un indicateur standard en matière de traduction automatique) sont calculés en comparant la transcription avec un texte traduit par un humain. Cependant, l’évaluation des traductions vocales pour une langue parlée comme le Hokkien est difficile, en raison notamment de l’absence de système écrit standard. Pour permettre une évaluation automatique, nous avons développé un système permettant de convertir le discours oral en Hokkien en une notation phonétique standardisée appelée Tâi-lô. Grâce à cette technique, nous avons pu calculer un score BLEU au niveau des syllabes et comparer facilement la qualité de traduction des différentes approches.
En plus de développer une méthode d’évaluation des traductions vocales Hokkien-anglais, nous avons créé le premier ensemble de données de référence en matière de traduction vocale bidirectionnelle Hokkien-anglais sur la base d’un corpus vocal en Hokkien appelé Taiwanese Across Taiwan. Cet ensemble de données de référence sera publié en open source pour encourager la recherche et progresser ensemble dans le domaine de la traduction vocale du Hokkien.
Le futur de la traduction
Dans sa phase actuelle, notre approche permet aux locuteurs du Hokkien de converser avec des anglophones. Notre modèle est toujours en cours d’amélioration et ne permet de traduire qu’une seule phrase à la fois, mais c’est une étape qui nous rapproche d’un futur où la traduction simultanée entre les langues sera possible.
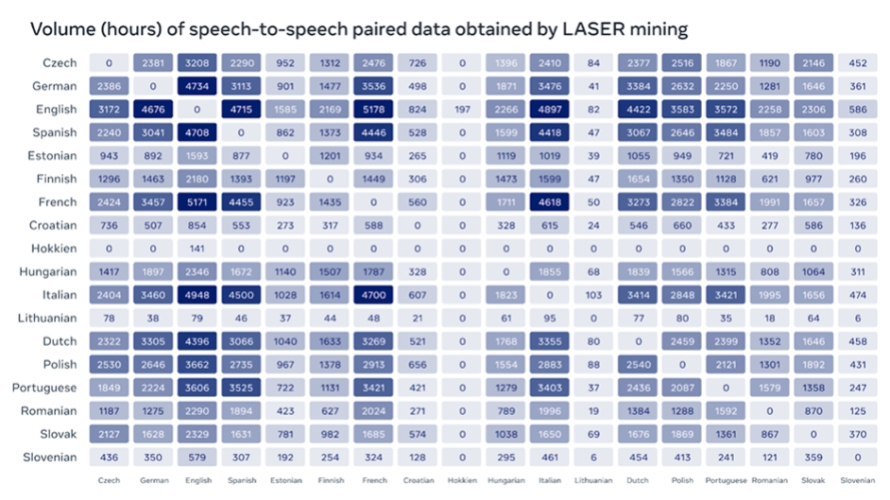
Les techniques que nous avons utilisées pour la première fois avec le Hokkien peuvent être étendues à de nombreuses autres langues, qu’elles aient une forme écrite ou non. C’est pour cette raison que nous publions la matrice vocale, un vaste corpus de traductions de parole à parole rassemblées grâce à la technique innovante d’analyse de données de Meta appelée LASER , qui permettra aux chercheurs de créer leurs propres systèmes de traduction de parole à parole (S2ST) en s’appuyant sur notre travail.
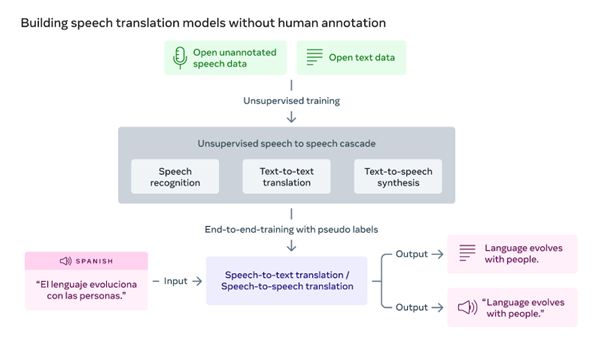
Les récentes avancées de Meta en matière de reconnaissance vocale non supervisée (wav2vec-U) et de traduction automatique non supervisée (mBART) constituent une référence pour les futures recherches dans le domaine de la traduction des langues orales. Nos progrès en matière d’entraînement non supervisé démontrent qu’il est possible de créer des modèles de traduction de parole à parole de grande qualité sans annotations humaines. Le système réduit considérablement les exigences nécessaires à l’élargissement de la prise en charge des langues aux faibles ressources en raison de l’absence de données supervisées pour grand nombre d’entre elles.
La recherche en intelligence artificielle contribue à faire sauter les barrières de la langue, dans le monde réel comme dans le métavers, afin d’encourager la communication et la connaissance de l’autre. Nous sommes enthousiastes à l’idée d’élargir nos recherches et de rendre cette technologie accessible à plus de personnes à l’avenir.
Pour lire les papiers de recherche :
https://research.facebook.com/publications/hokkien-direct-speech-to-speech-translation
https://research.facebook.com/publications/speechmatrix
https://research.facebook.com/publications/unsupervised-direct-speech-to-speech-translation
https://research.facebook.com/publications/unity-direct-speech-to-speech-translation
Ce travail a été réalisé par une équipe pluridisciplinaire, notamment Al Youngblood, Ana Paula Kirschner Mofarrej, Andy Chung, Angela Fan, Ann Lee, Benjamin Peloquin, Benoît Sagot, Brian Bui, Brian O’Horo, Carleigh Wood, Changhan Wang, Chloe Meyere, Chris Summers, Christopher Johnson, David Wu, Diana Otero, Eric Kaplan, Ethan Ye, Gopika Jhala, Gustavo Gandia Rivera, Hirofumi Inaguma, Holger Schwenk, Hongyu Gong, Ilia Kulikov, Iska Saric, Janice Lam, Jeff Wang, Jingfei Du, Juan Pino, Julia Vargas, Justine Kao, Karla Caraballo-Torres, Kevin Tran, Koklioong Loa, Lachlan Mackenzie, Michael Auli, Natalie Hereth, Ning Dong, Oliver Libaw, Orialis Valentin, Paden Tomasello, Paul-Ambroise Duquenne, Peng-Jen Chen, Pengwei Li, Robert Lee, Safiyyah Saleem, Sascha Brodsky, Semarley Jarrett, Sravya Popuri, TJ Krusinski, Vedanuj Goswami, Wei-Ning Hsu, Xutai Ma, Yilin Yang, Yun Tang.