
- Meta AI a mis au point un modèle d’IA unique, NLLB-200, qui est le premier à traduire dans 200 langues différentes avec une qualité de pointe validée par des évaluations poussées pour chacune d’entre elles.
- Nous avons également créé un nouvel ensemble de données d’évaluation, FLORES-200, et mesuré les performances de NLLB-200 dans chaque langue pour confirmer que les traductions sont de qualité. En moyenne, NLLB-200 a réalisé des scores 44 % supérieurs au précédent modèle le plus performant.
- Nous nous appuyons désormais sur des techniques de modélisation et sur les conclusions tirées du projet pour améliorer et étendre les traductions sur Facebook, Instagram et Wikipédia.
- Nous mettons en libre accès les modèles NLLB-200, l’ensemble de données FLORES-200, le code d’apprentissage des modèles et le code permettant de recréer l’ensemble de données d’apprentissage afin d’aider d’autres chercheurs à améliorer leurs outils de traduction et à s’appuyer sur nos travaux.
La langue est notre culture, notre identité et notre lien avec le monde. Mais compte tenu de l’absence d’outils de traduction de qualité pour des centaines de langues, des milliards de personnes ne peuvent pas accéder aux contenus numériques ni participer pleinement aux conversations et aux communautés en ligne dans leur langue de prédilection ou maternelle. Cela est particulièrement vrai pour les centaines de millions de locuteurs des diverses langues d’Afrique et d’Asie.
Pour aider tout un chacun à mieux se connecter aujourd’hui et à prendre part au métavers de demain, les chercheurs de Meta AI ont créé No Language Left Behind (NLLB), une initiative visant à développer des fonctionnalités de traduction automatique de haute qualité pour la plupart des langues du monde. Nous annonçons aujourd’hui une avancée importante concernant NLLB : nous avons développé un modèle d’IA unique appelé NLLB-200, qui traduit 200 langues différentes avec des résultats exceptionnels. Nombre de ces langues, telles que le kamba et le lao, n’étaient pas ou peu prises en charge, même par les meilleurs outils de traduction existants aujourd’hui. Moins de 25 langues africaines sont actuellement prises en charge par les outils de traduction les plus répandus, dont beaucoup sont de mauvaise qualité. En comparaison, NLLB-200 prend en charge 55 langues africaines avec des résultats exceptionnels. Au total, ce modèle unique peut fournir des traductions de qualité pour des langues parlées par des milliards de locuteurs dans le monde. En moyenne, les scores BLEU du modèle NLLB-200 sont supérieurs de 44 % à ceux du précédent modèle le plus performant sur l’ensemble des 10 000 sens de traduction des données de référence FLORES-101. Pour certaines langues africaines et indiennes, cette différence dépasse 70 % par rapport aux systèmes de traduction récents.
Nous mettons désormais le modèle NLLB-200 en libre accès et publions un ensemble d’outils pour aider d’autres chercheurs à étendre nos travaux à de nouvelles langues et à mettre au point des technologies plus inclusives. Meta AI verse également jusqu’à 200 000 $ de subventions à des organisations à but non lucratif afin de les aider à développer des applications concrètes du modèle NLLB-200.
Les avancées scientifiques réalisées grâce à l’initiative NLLB permettront d’améliorer plus de 25 milliards de traductions effectuées chaque jour sur le fil d’actualité de Facebook, Instagram et nos autres plateformes. Imaginez-vous pouvoir consulter votre groupe Facebook favori, trouver une publication en igbo ou luganda et la comprendre dans votre propre langue d’un simple clic. L’amélioration de la précision des traductions dans plusieurs langues pourra également faciliter le repérage des contenus nuisibles et des fausses informations, afin de préserver l’intégrité des élections et lutter contre les phénomènes d’exploitation sexuelle et de traite d’êtres humains en ligne. Les techniques de modélisation et les découvertes de notre recherche NLLB sont désormais utilisées par les systèmes de traduction des éditeurs de Wikipédia.
La traduction est l’une des perspectives les plus intéressantes de l’IA, car elle a beaucoup d’incidence sur le quotidien des internautes. L’initiative NLLB ne vise pas seulement à renforcer l’accessibilité des contenus sur le web. Elle permet aux internautes d’échanger et de partager plus facilement des informations entre plusieurs langues. Nous avons encore du chemin à parcourir, mais ces récents progrès nous remplissent d’espoir et nous aident à mieux accomplir la mission de Meta.
Vous trouverez ici une démonstration du modèle NLLB-200 pour constater sa capacité à traduire des histoires du monde entier. Vous pourrez également lire nos travaux de recherche.
Proposer des outils de traduction à des milliards de locuteurs supplémentaires
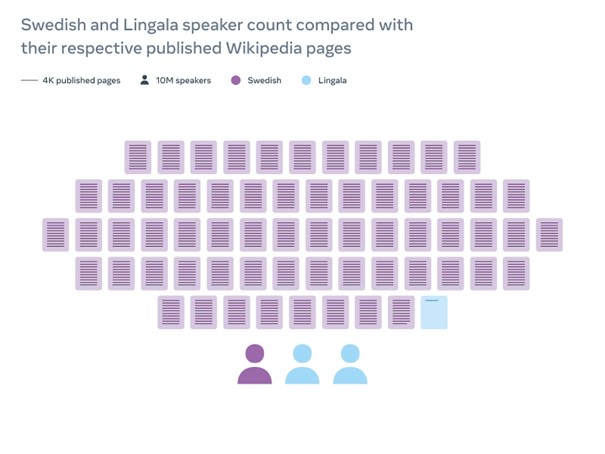
Nous avons travaillé en partenariat avec la fondation Wikimédia, une organisation à but non lucratif qui héberge Wikipédia et d’autres sites d’accès gratuit au savoir, pour aider à améliorer les systèmes de traduction de Wikipédia. Wikipédia possède des versions en plus de 300 langues, mais la plupart des versions sont loin d’approcher les plus de 6 millions d’articles du Wikipédia anglais. Cet écart est particulièrement marqué pour les langues principalement parlées en dehors de l’Europe et de l’Amérique du Nord. Par exemple, il n’existe qu’environ 3 260 articles de Wikipédia en lingala, une langue qui compte 45 millions de locuteurs dans la République démocratique du Congo, la République du Congo, la République Centrafrique et le Soudan du Sud. À titre de comparaison, il existe plus de 2,5 millions d’articles en suédois, alors que cette langue est parlée par 10 millions de locuteurs en Suède et en Finlande.
Les éditeurs de Wikipédia ont désormais accès à la technologie à l’origine du modèle NLLB-200 via l’outil de traduction de contenu de la fondation Wikimédia. Ils peuvent ainsi traduire des articles dans plus de 20 langues pour lesquelles peu de ressources existent (qui manquent d’ensembles de données exhaustifs pour entraîner des systèmes d’IA), dont 10 qui n’étaient pas encore prises en charge par les outils de traduction automatique de la plateforme.
Réussir à construire un seul modèle pour des centaines de langues
Les systèmes de traduction automatique, comme tous les modèles d’IA, sont entraînés sur des données. Dans le cas des systèmes de traduction textuelle, cela représente généralement des millions de phrases soigneusement mises en correspondance dans plusieurs langues. Mais le volume disponible de phrases parallèles n’est simplement pas le même en anglais qu’en peul. Les modèles de traduction actuels essaient de combler cet écart en extrayant des données du web. Mais cela donne souvent des résultats de piètre qualité, car le texte source n’est pas le même pour toutes les langues. De plus, le web contient un grand nombre de fautes et d’incohérences orthographiques. Les accents et les autres signes diacritiques y sont souvent omis.
Un autre défi important à relever consiste à optimiser un seul modèle de façon à le faire fonctionner pour des centaines de langues sans perdre en performances ou en qualité de la traduction. Traditionnellement, le meilleur moyen d’obtenir la plus haute qualité de traduction possible était de créer un modèle distinct pour chaque combinaison de langues. Mais cette approche est peu évolutive : les performances et la qualité de la traduction se dégradent lors de l’ajout de nouvelles langues.
Les modèles de traduction génèrent également des erreurs qui sont difficiles à repérer. Ces systèmes sont basés sur les mêmes réseaux neuronaux que ceux utilisés pour la génération de texte. Ils génèrent donc naturellement les mêmes types d’erreurs : fausses affirmations, inexactitude, contenu dangereux, etc. En règle générale, certaines langues disposent simplement d’un nombre plus réduit d’éléments de référence et d’ensembles de données, ce qui complique drastiquement les processus de test et d’amélioration des modèles.
Innover dans les domaines de l’architecture, de la collecte de données, de l’établissement de références et autres
Au cours des dernières années, nous avons fait d’importants progrès pour franchir tous ces obstacles. En 2020, nous avons présenté notre modèle de traduction en 100 langues, le M2M-100, qui s’appuyait sur de nouvelles méthodes d’acquisition des données d’entraînement, de nouvelles architectures permettant d’ajuster la taille du modèle sans nuire aux performances, ainsi que de nouveaux moyens d’évaluer et d’améliorer les résultats. Pour ajouter 100 langues supplémentaires, nous avons dû progresser sur ces trois derniers points.
Étoffer les ressources d’entraînement
Pour collecter des textes parallèles de grande qualité dans un plus grand nombre de langues, nous avons amélioré LASER, notre boîte à outils de transfert zero-shot pour le traitement naturel du langage. La nouvelle version LASER3, qui remplace les réseaux LSTM (long short-term memory), utilise un modèle Transformer auto-entraîné avec l’objectif MLM (masked language modeling). Nous avons amélioré ses performances en recourant à des procédures d’entraînement professeur-élève, ainsi qu’en créant des encodeurs propres à chaque groupe de langues. Cela nous a permis d’élargir la couverture linguistique du LASER3 et de produire d’importants volumes de phrases parallèles, y compris pour les langues pâtissant d’un manque de ressources. Nous mettons la méthode d’incorporation multilingue du LASER3 à la libre disposition des autres chercheurs. Nous publions également des milliards de phrases parallèles dans plusieurs combinaisons de langues que nous avons extraites et nettoyées à l’aide des techniques décrites ici.
Comme nous avons élargi nos sources de données d’entraînement en plusieurs langues, nous devions impérativement nous assurer que les exemples resteraient de bonne qualité. Nous avons entièrement repensé notre pipeline de nettoyage des données pour pouvoir traiter 200 langues en ajoutant plusieurs étapes de filtrage essentielles . Par exemple, nous commençons par utiliser nos modèles LID-200 pour filtrer les données et réduire le bruit des corpus web avec un haut niveau de précision. Nous avons établi des listes d’expressions dites toxiques pour chacune des 200 langues et les avons utilisées pour évaluer et filtrer les résultats potentiellement nuisibles. Ces étapes nous ont permis de nous assurer que nous disposons d’ensemble de données plus propres et moins offensants avec des langues correctement identifiées. Ce travail est important pour améliorer la qualité de la traduction et réduire le risque d’expressions toxiques (introduction de contenu nuisible par le système lors du processus de traduction).

Ajuster la taille du modèle sans nuire aux performances
Les systèmes de traduction multilingue présentent deux principaux avantages. Ils permettent de partager des données d’entraînement entre des langues qui se ressemblent, comme l’assamais et le bengali qui utilisent tous les deux l’alphasyllabaire bengali. Ils aident ainsi à améliorer considérablement la qualité de la traduction pour les langues disposant d’une faible quantité de ressources quand elles sont entraînées avec des langues plus documentées. Les chercheurs peuvent également reproduire, redimensionner et tester plus facilement un seul modèle multilingue que des centaines ou des milliers de modèles bilingues.
Toutefois, l’élargissement d’un modèle de 100 à 200 langues présente d’autres défis ardus. Lors de l’augmentation du nombre de paires de langues pour lesquelles nous disposons de peu de ressources dans les données d’entraînement, les modèles multilingues tendent progressivement vers une situation de surajustement au fur et à mesure de leur entraînement. Nous avons résolu ces problèmes en innovant sur trois fronts : la régularisation et l’apprentissage progressif, l’auto-apprentissage et la diversification de la retraduction.
Nous avons commencé par développer des réseaux de type Mixture of Experts avec une capacité partagée et spécialisée afin de rediriger automatiquement les langues avec peu de données vers cette capacité. Conjointement avec l’utilisation de systèmes de régularisation plus efficaces, cela permet d’éviter le surajustement. Nous avons également adopté une approche d’apprentissage progressif en deux étapes. Tout d’abord, nous avons entraîné les langues disposant de ressources abondantes pendant quelques itérations avant d’ajouter les paires de langues pour lesquelles nous disposions de peu de ressources afin de réduire le problème de surajustement. Ensuite, pour faire face à la faible quantité de données bitextuelles parallèles des langues moins représentées, nous avons mis à profit un modèle d’auto-apprentissage sur les données monolingues de ces langues ainsi que des langues mieux représentées qui leur ressemblent afin d’améliorer les performances globales du modèle.
Enfin, nous avons analysé la meilleure façon de générer des données de retraduction et avons découvert que le mélange de données retraduites à l’aide de modèles de traduction statistique bilingue et de traduction neuronale multilingue permettait d’améliorer les performances de traduction des langues moins représentées grâce à la plus grande diversité des données synthétiques générées. Pour entraîner le modèle NLLB-200, qui comporte 54 milliards de paramètres, nous nous sommes servis de notre tout nouveau superordinateur d’IA Research SuperCluster (RSC), un des plus rapides au monde.
Concevoir des outils d’évaluation et de réduction des risques pour plus de 200 langues
Pour évaluer et améliorer le modèle NLLB-200, nous avons mis au point un ensemble de données d’évaluation plusieurs-à-plusieurs unique, baptisé FLORES-200. Cet ensemble permet aux chercheurs d’évaluer les performances du modèle dans 40 000 sens de traduction différents. Nous mettons en accès libre cet ensemble de données pour aider d’autres chercheurs à tester rapidement et à améliorer leurs modèles de traduction. L’ensemble FLORES-200 permet d’évaluer les systèmes de traduction pour un grand nombre d’applications, notamment des brochures santé, des films, des livres et du contenu en ligne dans des pays ou des régions dont les langues sont représentées par un faible nombre de ressources.
Le passage à 200 langues nécessitait de prévenir les risques de génération de contenu toxique, qui peuvent être difficiles à gérer dans un système de traduction multilingue. Pour ce faire, nous avons établi une liste d’expressions toxiques pour toutes les langues prises en charge afin de permettre la détection et le filtrage des injures et de tout autre contenu potentiellement offensant. Nous publions nos références et nos listes d’évaluation des expressions toxiques pour l’ensemble des 200 langues afin de donner aux autres chercheurs un outil leur permettant de réduire les risques de leurs modèles.
Pour être certains d’œuvrer de la manière la plus responsable possible, nous avons fait appel à une équipe interdisciplinaire de linguistes, de sociologues et d’ethnologues pour chacune des langues concernées.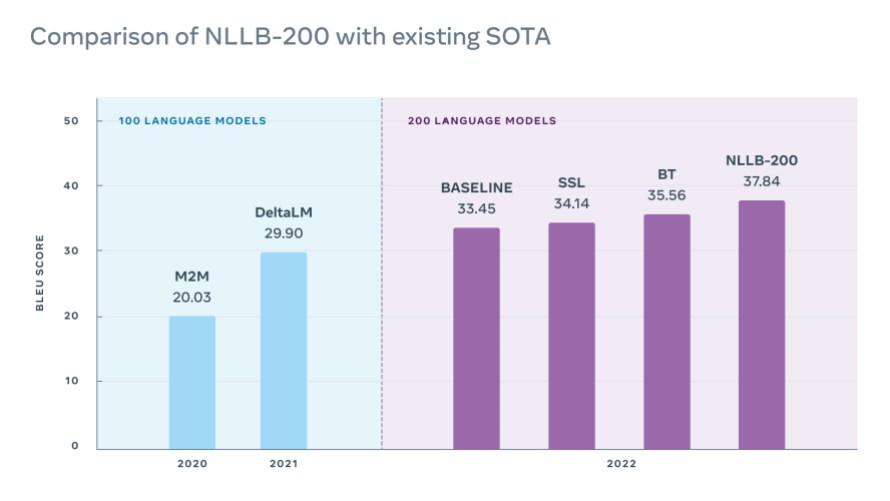
Le graphique ci-dessus indique le score BLEU moyen sur le corpus FLORES-101 de traductions de 100 langues à partir de l’anglais et vers celui-ci. À gauche, M2M et Delta LM, deux modèles de pointe publiés qui prennent en charge 100 langues. À droite, des modèles qui prennent en charge 200 langues : un modèle Transformer de référence avec 3,3 milliards de paramètres, un modèle de référence avec auto-apprentissage, un modèle de référence avec retraduction, et NLLB-200, un modèle de type Mixture of Experts qui exploite l’auto-apprentissage et la retraduction.
Développer la traduction et renforcer l’inclusion
Les outils de traduction de haute qualité peuvent être révolutionnaires. Aujourd’hui, la réalité est que le web est dominé par une poignée de langues, notamment l’anglais, le mandarin, l’espagnol et l’arabe. Les locuteurs natifs de ces langues peuvent avoir du mal à se représenter l’importance de pouvoir lire quelque chose dans leur langue natale. Nous pensons que l’initiative NLLB aidera à préserver le message original de chaque langue plutôt que de risquer souvent de le perdre en faisant appel à une langue intermédiaire.
Outre la traduction, elle permettra également de réaliser des progrès dans d’autres domaines du traitement naturel des langues. Cela peut inclure le développement d’assistants fonctionnant dans des langues tels que le javanais ou l’ouzbek, ou encore la création de systèmes permettant de sous-titrer précisément des films de Bollywood en swahili ou oromo. Avec l’émergence du métavers, la possibilité de créer des technologies qui fonctionnent correctement dans des centaines ou même des milliers de langues facilitera grandement l’accès du plus grand nombre à de nouvelles expériences immersives dans des mondes virtuels.
Il y a seulement quelques années, la traduction automatique de haute qualité ne fonctionnait que dans quelques langues. Grâce au modèle NLLB-200, nous avons fait un pas de plus vers des systèmes permettant à tout le monde de communiquer avec tous les interlocuteurs de son choix. Nous sommes enthousiastes à l’idée de tout ce que cela peut représenter aujourd’hui et à l’avenir, et nous continuerons de repousser les limites de la traduction automatique.
Ce travail a été réalisé par une équipe pluridisciplinaire de Meta AI, notamment : Bapi Akula, Pierre Andrews, Necip Fazil Ayan, Loic Barrault, Shruti Bhosale, Marta Ruiz Costa-jussa, James Cross, Onur Çelebi, Sergey Edunov, Maha Elbayad, Angela Fan, Cynthia Gao, Gabriel Mejia Gonzalez, Vedanuj Goswami, Francisco Guzmán, Prangthip Hansanti, Kennet Heafield, Kevin Heffernan, John Hoffman, Semarley Jarrett, Elahe Kalbassi, Philipp Koehn, Janice Lam, Daniel Licht, Jean Maillard, Alexandre Mourachko, Christophe Ropers, Kaushik Ram Sadagopan, Safiyyah Saleem, Holger Schwenk, Shannon Spruit, Anna Sun, Chau Tran, Skyler Wang, Guillaume Wenzek, Jeff Wang et Al Youngblood.