
Pour développer la prochaine génération de l’intelligence artificielle, il faudra de nouveaux ordinateurs assez puissants pour effectuer des milliards de milliards d’opérations par seconde. Aujourd’hui, Meta annonce la conception et la fabrication de l’AI Research SuperCluster (RSC) qui fait partie des superordinateurs d’intelligence artificielle les plus rapides à ce jour. Il sera, nous en avons la conviction, le plus rapide au monde une fois terminé à la mi-2022. Nos équipes de recherche ont déjà commencé à utiliser le RSC pour entraîner de vastes modèles au traitement du langage naturel (NLP) et la vision par ordinateur pour la recherche. L’objectif est d’entraîner un jour des modèles comportant des milliers de milliards de paramètres.
Le RSC aidera les équipes de recherche en intelligence artificielle de Meta à créer de nouveaux modèles plus performants, capables d’apprendre à partir de milliers de milliards d’exemples, de fonctionner dans des centaines de langues différentes, d’analyser de manière transparente des textes, des images et des vidéos, de développer de nouveaux outils de réalité augmentée, et bien plus encore. Nos équipes seront en mesure d’entraîner les plus grands modèles nécessaires au développement d’une intelligence artificielle avancée pour la vision par ordinateur, le NLP, la reconnaissance vocale, etc. Nous espérons que le RSC nous aidera à créer des systèmes d’intelligence artificielle entièrement nouveaux qui pourront, par exemple, fournir des traductions vocales en temps réel à de nombreuses personnes parlant chacune une langue différente, afin qu’elles puissent collaborer en toute fluidité sur un projet de recherche ou jouer ensemble à un jeu en réalité augmentée. Le travail effectué avec le RSC permettra finalement la mise au point de technologies adaptées à la prochaine grande plate-forme informatique, le métavers, au sein duquel les applications et les produits basés sur l’intelligence artificielle joueront un rôle crucial.

Pourquoi avons-nous besoin d’un superordinateur d’intelligence artificielle à cette échelle ?
Meta s’est engagé à investir à long terme dans l’intelligence artificielle depuis 2013, lors de la création du laboratoire Facebook AI Research. Ces dernières années, nos progrès en matière d’intelligence artificielle ont été considérables, et ce grâce à notre leadership dans un certain nombre de domaines, parmi lesquels l’apprentissage autosupervisé, qui permet aux algorithmes d’apprendre à partir d’un grand nombre d’exemples non étiquetés, et les transformateurs, qui permettent aux modèles d’intelligence artificielle de raisonner plus efficacement en se concentrant sur certaines parties des données recueillies.
Pour tirer pleinement parti des avantages de l’apprentissage autosupervisé et des modèles basés sur les transformateurs, divers domaines, qu’il s’agisse de la vision, de la parole, du langage, ou certains usages essentiels comme l’identification de contenus préjudiciables, nécessiteront l’entraînement de modèles de plus en plus vastes, complexes et adaptables. La vision par ordinateur, par exemple, doit traiter des vidéos plus grandes et plus longues avec des taux d’échantillonnage de données plus élevés. La reconnaissance vocale doit fonctionner correctement même dans des situations compliquées avec beaucoup de bruit de fond, comme des fêtes ou des concerts. Le NLP doit prendre en charge davantage de langues, de dialectes et d’accents. Les avancées dans d’autres domaines, notamment la robotique, l’intelligence artificielle incarnée et l’intelligence artificielle multimodale, aideront quant à elles à accomplir des tâches utiles dans le monde réel.
L’infrastructure informatique à haute performance est un élément essentiel de l’entraînement de modèles aussi vastes, et l’équipe de recherche en intelligence artificielle de Meta élabore ces systèmes à haute puissance depuis de nombreuses années. La première génération de cette infrastructure, conçue en 2017, compte 22 000 processeurs graphiques NVIDIA V100 Tensor Core dans un seul cluster qui effectue 35 000 tâches d’entraînement par jour. Jusqu’à présent, cette infrastructure servait de référence en matière de performance, de fiabilité et de productivité pour les équipes de recherche de Meta.
Début 2020, nous avons décidé que la meilleure façon d’accélérer les progrès était de concevoir une nouvelle infrastructure informatique à partir de zéro pour exploiter la technologie de processeurs graphiques et de réseaux nouveaux. Nous voulions qu’elle soit capable d’entraîner des modèles comportant plus de mille milliards de paramètres sur des ensembles de données aussi volumineux qu’un exaoctet, ce qui, pour donner une idée de l’échelle, équivaut à 36 000 ans de vidéo de haute qualité.
Si la communauté de l’informatique à haute performance aborde la question de l’échelle depuis des décennies, nous devions également veiller à disposer de tous les contrôles nécessaires en matière de sécurité et de confidentialité pour protéger les données d’entraînement que nous utilisons. Contrairement à notre précédente infrastructure de recherche en intelligence artificielle, qui n’utilisait que des sources ouvertes et d’autres ensembles de données accessibles au public, le RSC nous aide également à garantir que nos recherches se concrétisent efficacement. Il nous permet ainsi d’inclure des exemples du monde réel provenant des systèmes de production de Meta dans l’entraînement des modèles. Ce faisant, la recherche avance et permet d’effectuer des tâches en aval, comme l’identification de contenus préjudiciables sur nos plates-formes, ou l’étude de l’intelligence artificielle incarnée et de l’intelligence artificielle multimodale, améliorant ainsi l’expérience du public sur notre famille d’applications. Il s’agit, selon nous, de la première fois que les performances, la fiabilité, la sécurité et la confidentialité sont abordées à une telle échelle.
RSC : en coulisses

Les superordinateurs d’intelligence artificielle combinent plusieurs processeurs graphiques dans des nœuds informatiques, qui sont ensuite reliés par une matrice réseau haute performance pour permettre une communication rapide entre ces processeurs. Aujourd’hui, le RSC comprend un total de 760 systèmes NVIDIA DGX A100 comme nœuds informatiques, pour un total de 6 080 processeurs, chaque processeur A100 étant plus puissant que le V100 utilisé dans notre système précédent. Les processeurs graphiques communiquent par l’intermédiaire d’un réseau Clos InfiniBand NVIDIA Quantum 200 Go/s à deux niveaux, sans sursouscription. Le niveau de stockage du RSC compte 175 pétaoctets de Pure Storage FlashArray, 46 pétaoctets de mémoire cache dans des systèmes Altus de Penguin Computing et 10 pétaoctets de Pure Storage FlashBlade.
Les premiers tests de référence sur le RSC, comparés à l’infrastructure de production et de recherche existante de Meta, ont montré qu’il exécute les workflows de vision par ordinateur jusqu’à 20 fois plus rapidement, qu’il exécute la NVIDIA Collective Communication Library (NCCL) plus de neuf fois plus rapidement et qu’il entraîne les modèles de NLP à grande échelle trois fois plus rapidement. Cela signifie qu’un modèle comportant des dizaines de milliards de paramètres peut terminer son entraînement en trois semaines, contre neuf auparavant.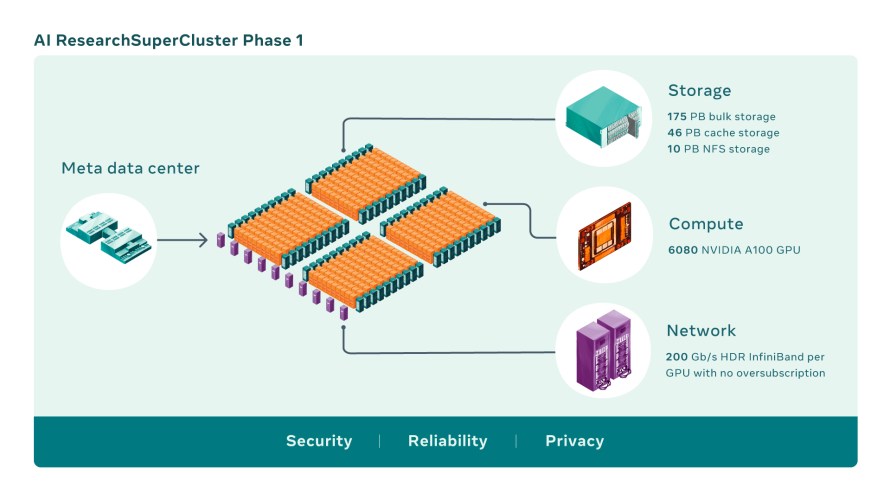
Créer un superordinateur d’intelligence artificielle…

Concevoir et créer quelque chose comme le RSC n’est pas seulement une question de performances, mais de performances à la plus grande échelle possible, avec la technologie la plus avancée actuellement disponible. Une fois le RSC terminé, la matrice InfiniBand connectera 16 000 processeurs graphiques comme points de terminaison, ce qui en fait l’un des plus grands réseaux de ce type déployés à ce jour. Nous avons en outre conçu un système de mise en cache et de stockage capable de traiter 16 To/s de données d’entraînement, et nous prévoyons de mener ce chiffre à 1 exaoctet.
Toute cette infrastructure doit être extrêmement fiable car, selon nos estimations, certaines expériences pourraient durer plusieurs semaines et nécessiter des milliers de processeurs graphiques. Enfin, le RSC doit être convivial pour les équipes de recherche, pour que nous puissions facilement nous pencher sur une multitude de modèles d’intelligence artificielle.
Pour y parvenir, il a fallu collaborer avec un certain nombre de partenaires de longue date, qui ont tous également participé à la conception de la première génération de notre infrastructure d’intelligence artificielle en 2017. Penguin Computing, notre partenaire d’architecture et de services gérés, a travaillé avec notre équipe d’exploitation sur l’intégration du matériel pour déployer le cluster et a aidé à mettre en place les principales parties du plan de contrôle. Pure Storage nous a fourni une solution de stockage solide et évolutive. NVIDIA nous a fourni ses technologies informatiques d’intelligence artificielle avec des systèmes de pointe, des processeurs graphiques et la matrice InfiniBand, ainsi que des composants de la pile logicielle comme la NCCL pour le cluster.
…à distance, pendant une pandémie
Un autre défi inattendu est apparu pendant le développement du RSC : la pandémie de COVID-19. Nous avons lancé le projet RSC entièrement à distance. Il s’agissait au départ d’un simple document partagé, qui a fini par devenir un cluster fonctionnel en un an et demi environ. Le COVID-19 et les contraintes d’approvisionnement en wafers à l’échelle du secteur ont également rendu difficile l’obtention d’un grand nombre de pièces : puces, composants optiques, processeurs graphiques, matériaux de construction, etc. En plus, tous devaient être acheminés en étant conformes à des nouveaux protocoles de sécurité. Pour créer efficacement ce cluster, nous avons dû le concevoir à partir de zéro, en créant de nombreuses conventions spécifiques à Meta, entièrement nouvelles et en repensant les précédentes en cours de route. Nous avons dû établir de nouvelles règles concernant la conception de nos data centers, notamment en ce qui concerne le refroidissement, l’alimentation, la disposition des racks, le câblage et la mise en réseau (y compris un plan de contrôle entièrement nouveau), entre autres éléments importants à prendre en considération. Nous devions nous assurer que toutes les équipes, de la construction au matériel, en passant par les logiciels et l’intelligence artificielle, travaillaient au même rythme et en coordination avec nos partenaires.
Au-delà du système central lui-même, nous avions également besoin d’une solution de stockage puissante, capable de fournir des téraoctets de bande passante à partir d’un système de stockage de l’ordre de l’exaoctet. Pour répondre aux besoins croissants des entraînements d’intelligence artificielle en termes de bande passante et de capacité, nous avons développé un service de stockage, l’AI Research Store (AIRStore), à partir de zéro. Pour optimiser les modèles d’intelligence artificielle, l’AIRStore fait appel à une nouvelle phase de préparation des données qui pré-traite l’ensemble des données à utiliser pour l’entraînement. Une fois la préparation effectuée une fois, l’ensemble de données préparé peut être utilisé pour de multiples entraînements jusqu’à son expiration. L’AIRStore optimise également les transferts de données afin de minimiser le trafic interrégional sur le réseau fédérateur inter-datacenters de Meta.
Protéger les données dans le RSC
Pour élaborer de nouveaux modèles d’intelligence artificielle qui profitent aux utilisateurs et utilisatrices de nos services, qu’il s’agisse de détecter des contenus préjudiciables ou de créer de nouvelles expériences de réalité augmentée, nous devons entraîner les modèles à l’aide de données provenant de nos systèmes de production, dans le monde réel. Le RSC a été conçu dès le départ en tenant compte de la confidentialité et de la sécurité, afin que les équipes de recherche de Meta puissent entraîner des modèles en toute sécurité en utilisant des données chiffrées générées par les utilisateurs et les utilisatrices, et qui ne sont déchiffrées que juste avant l’entraînement. Par exemple, le RSC est isolé du reste d’Internet, sans connexions directes entrantes ou sortantes, et le trafic ne peut provenir que des data centers de production de Meta.
Conformément à nos exigences en matière de confidentialité et de sécurité, l’ensemble du cheminement des données, de nos systèmes de stockage aux processeurs graphiques, est chiffré de bout en bout et dispose des outils et processus nécessaires pour vérifier que ces exigences sont respectées à tout moment. Avant d’être importées dans le RSC, les données sont soumises à un processus de vérification de la confidentialité afin de confirmer qu’elles ont été correctement anonymisées. Les données sont ensuite chiffrées avant d’être utilisées pour entraîner des modèles d’IA et les clés de déchiffrage sont supprimées régulièrement pour s’assurer que les anciennes données ne sont plus accessibles. Et comme les données ne sont déchiffrées qu’en un point de terminaison unique, en mémoire, elles sont protégées même dans le cas peu probable d’une entrée par effraction dans nos locaux.
Vers la phase deux et au-delà
Le RSC est opérationnel aujourd’hui, mais son développement est toujours en cours. Une fois la phase deux de la création du RSC achevée, nous pensons qu’il sera le superordinateur d’intelligence artificielle le plus rapide du monde, avec une performance de près de 5 exaflops de calcul de précision mixte. En 2022, nous nous efforcerons de faire passer le nombre de processeurs graphiques de 6 080 à 16 000, ce qui permettra de multiplier les performances d’entraînement de l’intelligence artificielle par 2,5. La matrice InfiniBand s’étendra pour prendre en charge 16 000 ports dans une topologie à deux couches, sans sursouscription. Le système de stockage bénéficiera d’une bande passante cible de 16 To/s et d’une capacité de l’ordre de l’exaoctet pour répondre à la demande croissante.
Une telle évolution des capacités de calcul devrait nous permettre non seulement de créer des modèles d’intelligence artificielle plus précis pour nos services existants, mais aussi de proposer des expériences d’utilisation totalement nouvelles, notamment dans le métavers. Nos investissements à long terme dans l’apprentissage autosupervisé et dans la construction d’une infrastructure d’intelligence artificielle de nouvelle génération avec le RSC nous aident à créer les technologies fondamentales qui alimenteront le métavers et feront également progresser la communauté de l’intelligence artificielle au sens large.
Pour en savoir plus sur nos efforts de recherche dans le domaine du NLP, de la vision par ordinateur et d’autres domaines de l’intelligence artificielle, rejoignez-nous lors de notre prochain évènement virtuel : « Inside the Lab: Building for the metaverse with AI ».