
Ranking personalizado com machine learning
Existem muitas teorias e mitos sobre o algoritmo do Feed de Notícias. A maioria das pessoas sabe que existe um algoritmo, e muitas conhecem alguns dos fatores que o informam (como se você curte uma publicação ou interage com ele, etc.). No entanto, há várias informações que ainda não foram bem compreendidas.
Falamos publicamente sobre vários detalhes e recursos do Feed de Notícias. Mas existe um sistema de classificação de machine learning (aprendizado de máquina), que é complexo e tem várias camadas, por trás do Feed de Notícias. Como parte do nosso compromisso contínuo de transparência, vamos compartilhar novas informações sobre nosso sistema de classificação e os desafios de usá-lo para personalizar o conteúdo para mais de dois bilhões de pessoas e mostrar a cada uma delas conteúdo relevante toda vez que acessam o Facebook.
Por que é tão difícil fazer isso?
Em primeiro lugar, o volume de publicações é enorme. Mais de dois bilhões de pessoas no mundo inteiro usam o Facebook. Para cada uma delas, existem mais de mil publicações “candidatas” (ou com potencial para aparecer no seu Feed). Isso resulta em trilhões de publicações para todas as pessoas no Facebook.
Agora, considere que para cada pessoa no Facebook existam milhares de sinais que nós precisamos avaliar para determinar o que cada pessoa pode encontrar de mais relevante. Então teremos trilhões de publicações e milhares de sinais – e nós precisamos prever o que cada uma dessas pessoas quer ver imediatamente em seu Feed. Quando você abre o Facebook, esse processo ocorre nos poucos segundos que o Feed de Notícias leva para carregar.
E uma vez que tudo isso está funcionando, as coisas mudam, e precisamos considerar novas questões que surgem, como caça-cliques e a disseminação de informações enganosas. Quando isso acontece, precisamos encontrar novas soluções. O sistema de classificação não é constituído de apenas um algoritmo. São múltiplas as camadas de modelos de machine learning e de classificação que aplicamos para prever o conteúdo mais relevante e significativo para cada usuário. Conforme percorremos cada estágio, o sistema de classificação restringe as milhares de publicações candidatas às centenas que aparecem no Feed de Notícias de alguém a qualquer momento.
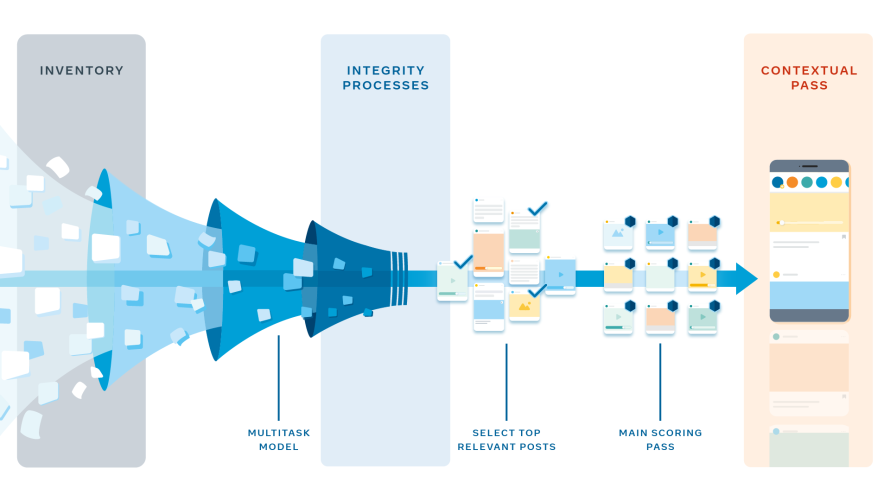
Como fazemos isso
Basicamente, o sistema determina quais publicações aparecem no Feed de Notícias e em qual ordem. Ele faz isso prevendo por quais publicações a pessoa teria maior chance de se interessar ou com quais teria maior probabilidade de interagir. As previsões se baseiam em vários fatores, inclusive o quê e quem você segue/curte e com o quê e quem você interagiu recentemente. Para entender como isso funciona na prática, vamos descrever o que acontece quando alguém entra no Facebook – e imagine que essa pessoa se chama Juan.
Desde que Juan entrou no Facebook ontem, um de seus amigos, Wei, publicou uma foto do seu cocker spaniel. Outra amiga, Saanvi, publicou um vídeo da sua corrida matinal. A Página favorita de Juan publicou um artigo interessante sobre a melhor maneira de ver a Via Láctea à noite, e seu Grupo favorito sobre culinária publicou quatro novas receitas com fermento natural.
Todo esse conteúdo provavelmente é relevante ou interessante para o Juan, pois ele segue as pessoas ou as Páginas que os compartilharam. Para decidir qual dessas publicações deve aparecer no topo do Feed de Notícias dele, precisamos prever qual conteúdo é mais importante para ele. Matematicamente, precisamos definir uma “Função Objetivo” para Juan e fazer uma otimização de objetivo único.
Podemos usar as características de uma publicação, como quem foi marcado em uma foto e a data em que foi publicada, para prever se Juan a curtiria. Por exemplo, se ele costuma interagir com as publicações de Saanvi (por exemplo, ao compartilhar ou comentar) e se o vídeo da corrida dela é bem recente, há maior chance de Juan se interessar pela publicação. Se Juan engajou com mais conteúdo de vídeo do que com fotos anteriormente, provavelmente ele não terá muito interesse na foto do cocker spaniel de Wei. Nesse caso, nosso algoritmo classificará o vídeo da corrida de Saanvi em uma posição mais alta do que a foto do cachorro de Wei, pois ele prevê que há maior probabilidade de Juan curtir o vídeo.
Porém, as pessoas podem manifestar suas preferências no Facebook de outras maneiras. Todo dia, elas compartilham artigos que acham interessantes, assistem a vídeos de pessoas ou celebridades que seguem, ou fazem comentários nas publicações de seus amigos. Matematicamente, as coisas ficam mais complicadas quando precisamos otimizar para vários objetivos que se juntam ao nosso objetivo principal, que é criar o maior valor de longo prazo para as pessoas mostrando conteúdo significativo para elas.
Uma série de modelos de machine learning produz várias previsões para o Juan, entre elas, a probabilidade de que ele irá engajar com a foto de Wei, o vídeo de Saanvi, o artigo sobre a Via Láctea ou as receitas com fermento natural. Cada modelo procura classificar esses conteúdos para Juan. Às vezes, os modelos divergem. Pode haver maior probabilidade de Juan curtir o vídeo da corrida de Saanvi do que o artigo da Via Láctea, mas ele pode ter maior chance de comentar no artigo do que no vídeo. Logo, precisamos encontrar uma forma de combinar essas previsões variáveis a fim de formar uma pontuação otimizada para nosso objetivo principal de valor de longo prazo.
Como podemos mensurar se algo agrega valor a longo prazo para uma pessoa? Perguntamos a ela. Por exemplo, fazemos uma pesquisa em que as pessoas precisam dizer se uma interação com amigos foi significativa e quanto ou se valeu a pena ler uma publicação. Assim, nosso sistema poderá refletir as preferências dos usuários. Podemos pensar em cada previsão para Juan com base nas ações que as pessoas afirmam (nas pesquisas) que são mais proveitosas para elas.
Remoção das camadas
Precisamos tornar o processo eficiente para classificar mais de mil publicações por usuário diariamente, para mais de dois bilhões de pessoas, em tempo real. O processo tem várias etapas, estrategicamente organizadas para acelerá-lo e limitar a quantidade de recursos computacionais exigida.
Primeiro, o sistema coleta todas as publicações candidatas que podemos classificar para Juan (a foto do cocker spaniel, o vídeo da corrida, etc.). Esse inventário qualificado inclui todas as publicações compartilhadas com João por um amigo, um Grupo ou uma Página com o qual ele está conectado, e que foram feitas desde o último login dele (só as que não foram excluídas). Mas como devemos lidar com publicações criadas antes do último login de Juan e que ele ainda não viu?
Para garantir que publicações não vistas sejam reconsideradas, aplicamos uma lógica de posicionamento de publicações não lidas: publicações novas que foram classificadas para Juan (mas que ele não viu) nas sessões anteriores também são adicionadas ao inventário qualificado para a sessão atual. Também aplicamos uma lógica de posicionamento de ações para que as publicações que Juan já viu e que impulsionaram uma conversa interessante entre os amigos dele também sejam adicionadas ao inventário qualificado.
Depois disso, o sistema precisa pontuar cada publicação de acordo com uma variedade de fatores, como o tipo de publicação, semelhança com outros itens e quanto ela corresponde ao conteúdo com o qual Juan tende a interagir. A fim de calcular isso para mais de mil publicações, para cada um dos dois bilhões de usuários (em tempo real), executamos esses modelos para todas as histórias candidatas paralelamente em várias máquinas, chamadas previsores.
Antes de usar todas as previsões para chegar a uma só pontuação, precisamos aplicar algumas regras adicionais. Esperamos até termos essas primeiras previsões para restringirmos o número de publicações que serão classificadas. Aplicamos as previsões em várias etapas para economizar energia computacional.
Primeiro, alguns processos automatizados de integridade são aplicados a cada publicação. Eles determinam quais medidas de detecção de integridade, se houver alguma, precisam ser aplicadas às histórias selecionadas para classificação. Na próxima etapa, um modelo leve diminui o número de candidatos para cerca de 500 das publicações mais relevantes para Juan. Classificando menos histórias, usamos mais modelos potentes de redes neurais nas próximas etapas.
Em seguida, temos a principal etapa de pontuação, em que a maior parte da personalização ocorre. Aqui, uma pontuação para cada história é calculada de forma independente. Depois todas as 500 publicações são ordenadas por pontuação. Para algumas pessoas, calcular um valor mais alto para curtidas do que para comentários pode fazer mais sentido, já que alguns usuários gostam de se manifestar mais através de curtidas do que comentando em publicações. Qualquer ação que uma pessoa raramente faz (por exemplo, uma previsão de curtida muito próxima a zero) automaticamente recebe uma função mínima na classificação, como o valor previsto é muito baixo.
Por fim, executamos a etapa contextual, na qual recursos contextuais como regras de variedade de tipos de conteúdo são adicionadas para que o Feed de Notícias do Juan tenha multiplicidade de conteúdo e que ele não veja uma série de publicações de vídeo, uma atrás da outra. Todas essas etapas de classificação acontecem enquanto Juan abre o aplicativo do Facebook. Em uma questão de segundos, ele pode acessar um Feed de Notícias classificado, pronto para navegação.