A equipe do Fundamental AI Research (FAIR) da Meta está focada em alcançar inteligência avançada de máquina (AMI na sigla em inglês) e usá-la para impulsionar produtos e inovação para o benefício de todos. Hoje, estamos animados em compartilhar algumas de nossas pesquisas e modelos mais recentes que apoiam nossa meta de alcançar AMI e nosso compromisso de longa data em compartilhar ciência aberta e reproduzível.
Meta PARTNR: Desbloqueando a colaboração entre humanos e robôs
Imagine um mundo em que os robôs são parceiros intuitivos no dia a dia — limpam a casa, recebem entregas e ajudam a cozinhar, tudo isso enquanto entendem nossas necessidades e se adaptam a ambientes dinâmicos. Hoje, estamos animados em apresentar o PARTNR, uma estrutura de pesquisa voltada para a colaboração perfeita entre humanos e robôs. Atualmente, a maioria dos robôs opera de forma isolada, o que limita seu potencial como assistentes do futuro. Com o PARTNR, pretendemos mudar o status quo ao tornar público um benchmark, um conjunto de dados e um modelo em larga escala para o estudo da interação entre humanos e robôs em tarefas do cotidiano. Em sua essência, o PARTNR permite o treinamento de robôs sociais por meio de simulações em grande escala, seguido de implementação no mundo real.
O PARTNR se baseia em pesquisas anteriores de alto impacto, compartilhados com a comunidade com enfoque de IA aberta. Ele evoluiu a partir do Habitat 1.0, que treinou robôs virtuais para navegar em escaneamentos 3D de casas reais, e do Habitat 2.0, que treinou robôs virtuais para limpar casas e organizar objetos. Com o Habitat 3.0, um simulador projetado para treinar modelos para colaboração humano-robô, demos mais um grande salto. O Habitat 3.0 permitiu o treinamento de modelos de colaboração humano-robô em larga escala, o que não é viável no mundo real por questões de segurança e problemas de escalabilidade.
Também estamos introduzindo o benchmark PARTNR, que visa avaliar robôs colaborativos e garantir que eles possam ter um bom desempenho em ambientes simulados e reais. Nosso benchmark consiste em 100.000 tarefas, incluindo tarefas domésticas, como lavar louça e brinquedos. Também estamos lançando o conjunto de dados PARTNR, que consiste em demonstrações humanas das tarefas PARTNR em simulação, que podem ser usadas para treinar modelos de IA incorporados. O benchmark PARTNR destaca as principais deficiências dos modelos existentes, como má coordenação e falhas no rastreamento de tarefas e recuperação de erros. Incentivamos a comunidade acadêmica a continuar a desenvolver nosso trabalho e a impulsionar o progresso no campo da colaboração entre humanos e robôs.
Ainda fizemos avanços em modelos que podem colaborar com humanos em ambientes de simulação e do mundo real. Usando dados de simulação em larga escala, treinamos um grande modelo de planejamento que supera as linhas de base de última geração em termos de velocidade e desempenho. Este modelo atinge um aumento de 8,6x na velocidade, ao mesmo tempo em que permite que os humanos sejam 24% mais eficientes na conclusão de tarefas em comparação aos modelos de alto desempenho existentes. Ele pode interpretar instruções de longo prazo, dividindo tarefas complexas em etapas acionáveis e fornecendo assistência significativa aos usuários humanos. Implementamos, com sucesso, este modelo no Spot da Boston Dynamics, demonstrando sua capacidade de trabalhar junto com humanos em cenários reais. Para aumentar a transparência e a confiança, também desenvolvemos uma interface de realidade mista que visualiza as ações e os processos de pensamento do robô, oferecendo uma janela para sua tomada de decisão.
O potencial para inovação e desenvolvimento no campo da colaboração humano-robô é amplo. Com o PARTNR, queremos reimaginar os robôs não apenas como agentes autônomos, mas como futuros parceiros e, assim, dar início à pesquisa neste campo emocionante.
Democratizando a tecnologia da linguagem para a Década Internacional das Línguas Indígenas
A linguagem é uma parte fundamental de quem somos, e, ainda assim, muitas pessoas ao redor do mundo são excluídas da conversa digital porque sua língua não é suportada pela tecnologia. Para preencher essa lacuna, estamos convidando a comunidade linguística para colaborar com a melhoria e ampliação da cobertura das tecnologias de linguagem com enfoque aberto da Meta, incluindo reconhecimento de fala e tradução automática.
Programa de Parceiros em Tecnologia de Linguagem
Estamos buscando parceiros para colaborar com o avanço das tecnologias de linguagem, incluindo reconhecimento de fala e tradução automática. Nossos esforços são especialmente focados em línguas carentes, em apoio ao trabalho da UNESCO e como parte da contribuição do setor privado para o empoderamento digital dentro da Década Internacional das Línguas Indígenas. Estamos buscando parceiros que possam contribuir com mais de 10 horas de gravações de fala com transcrições, grandes corpora de texto escrito (mais de 200 frases) e conjuntos de frases traduzidas em diversos idiomas. Os parceiros trabalharão com nossas equipes para integrar esses idiomas a modelos de reconhecimento de fala e tradução automática baseados em IA, que serão disponibilizados gratuitamente para a comunidade. Os parceiros também terão acesso a workshops liderados por nossos pesquisadores, onde aprenderão como aproveitar nossos modelos com enfoque aberto para construir tecnologias de linguagem. Estamos felizes que o Governo de Nunavut, no Canadá, tenha concordado em trabalhar conosco nesta iniciativa empolgante.
Para participar do nosso Programa de Parceiros em Tecnologia de Linguagem, preencha este formulário de interesse.
Benchmark de tradução automática com enfoque de IA aberta
Além do nosso Programa de Parceiros em Tecnologia de Linguagem, estamos lançando um benchmark de tradução automática com enfoque aberto de IA, composto por frases cuidadosamente elaboradas por especialistas em linguística para mostrar a diversidade da linguagem humana. Convidamos você a acessar o benchmark em sete idiomas e contribuir com traduções que serão disponibilizadas para a comunidade. Nosso objetivo é construir, de forma colaborativa, um benchmark de tradução automática multilíngue sem precedentes.
Nosso compromisso de oferecer suporte a mais idiomas e desenvolver tecnologias com enfoque aberto para IA para eles é contínuo. Em 2022, lançamos o No Language Left Behind (NLLB), um mecanismo inovador de tradução automática com enfoque aberto que estabeleceu a base para futuras pesquisas e desenvolvimentos nessa área. Como o primeiro modelo de tradução neural para muitos idiomas, o NLLB abriu caminho para mais inovação. Desde seu lançamento, a comunidade de enfoque aberto para IA se baseou nesse trabalho, expandindo suas capacidades para oferecer suporte a dezenas de idiomas adicionais. Também estamos satisfeitos que a UNESCO e a Hugging Face colaboraram conosco para criar um tradutor de idiomas baseado no NLLB, que anunciamos durante a semana da Assembleia Geral das Nações Unidas em setembro de 2024. À medida que continuamos a desenvolver essa tecnologia, estamos animados para colaborar com comunidades de idiomas para aprimorar e expandir a tradução automática e outras tecnologias de idiomas.
Para dar suporte ao empoderamento digital, que é uma área temática fundamental do Plano de Ação Global da Década Internacional das Línguas Indígenas, introduzimos recentemente o projeto Massively Multilingual Speech (MMS), que dimensiona a transcrição de áudio para mais de 1.100 idiomas. Continuamos a melhorar e expandir suas capacidades, incluindo a adição do reconhecimento de fala zero-shot, que permite que o modelo transcreva áudio em idiomas nunca vistos antes sem treinamento prévio. Essas tecnologias têm implicações significativas para o suporte e acessibilidade de idiomas, especialmente para comunidades carentes.
Ao promover a implementação da Década Internacional de Línguas Indígenas, pretendemos abordar os desafios impostos pelo crescimento de modelos de língua inglesa e trabalhar para uma representação igualitária de todos os idiomas, contribuindo para a realização dos Objetivos de Desenvolvimento Sustentável das Nações Unidas.
Além de seu impacto potencial no suporte e acessibilidade de idiomas, nosso trabalho também tem implicações mais amplas para o desenvolvimento do AMI. Ao trabalhar em problemas multilíngues e idiomas carentes, o modelo demonstra a capacidade de aprender com dados mínimos. Esses desenvolvimentos marcam um passo crucial para a criação de sistemas inteligentes que podem se adaptar a novas situações e aprender com a experiência.
Nosso grande objetivo é criar sistemas inteligentes que possam entender e responder a necessidades humanas complexas, independentemente do idioma ou origem cultural, garantindo que a tecnologia seja inclusiva e acessível para todas as línguas do mundo.
Meta Audiobox Aesthetics: um novo padrão para processamento de áudio
Tradicionalmente, medir a estética do áudio tem sido uma tarefa complexa devido à sua natureza subjetiva. Ao contrário de métricas objetivas como resposta de frequência ou relação sinal-ruído, a estética do áudio requer uma compreensão diferenciada da percepção humana. Hoje, estamos animados em trazer nosso enfoque de IA aberta para o Meta Audiobox Aesthetics, um modelo que permite a avaliação automática da estética do áudio, fornecendo uma avaliação abrangente da qualidade do áudio em fala, música e som. O modelo faz previsões que analisam o prazer do conteúdo, a utilidade do conteúdo, a complexidade e a qualidade da produção. Abordar os desafios da avaliação subjetiva do áudio leva à melhoria da qualidade do conteúdo de áudio e ao desenvolvimento de modelos de áudio generativos mais avançados.
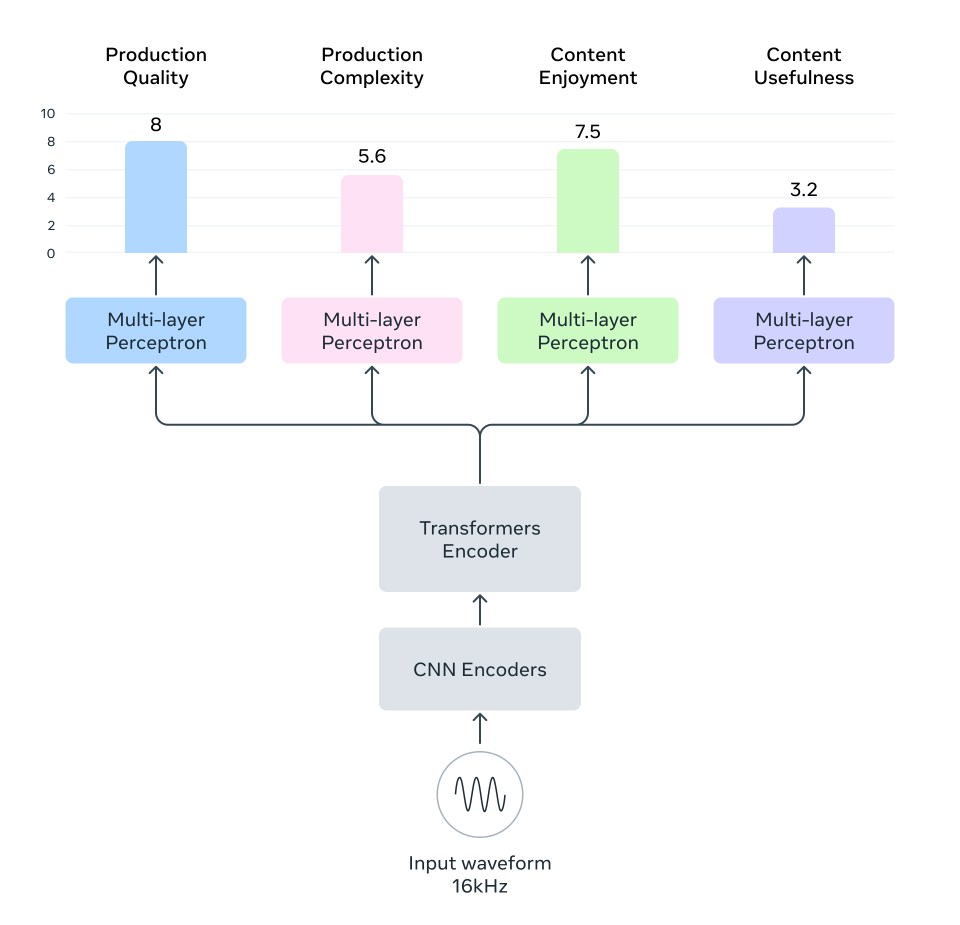
Os métodos de avaliação existentes geralmente fornecem resultados específicos de submodalidade com instruções vagas que são difíceis de interpretar. O Audiobox Aesthetics supera essas limitações ao oferecer uma abordagem estruturada para avaliação de áudio.
Para desenvolver o Audiobox Aesthetics, projetamos um protocolo de anotação abrangente, resultando na coleta de 562 horas de dados estéticos de áudio. Nosso conjunto de dados foi anotado por avaliadores profissionais para garantir dados de alta qualidade. O processo de anotação envolveu a avaliação de amostras de áudio em uma escala de um a dez em quatro métricas definidas: qualidade da produção, complexidade da produção, aproveitamento do conteúdo e utilidade do conteúdo. Esse processo permitiu a criação de uma pontuação estética unificada calibrada em diferentes modalidades de áudio, garantindo consistência e confiabilidade nas previsões do modelo.
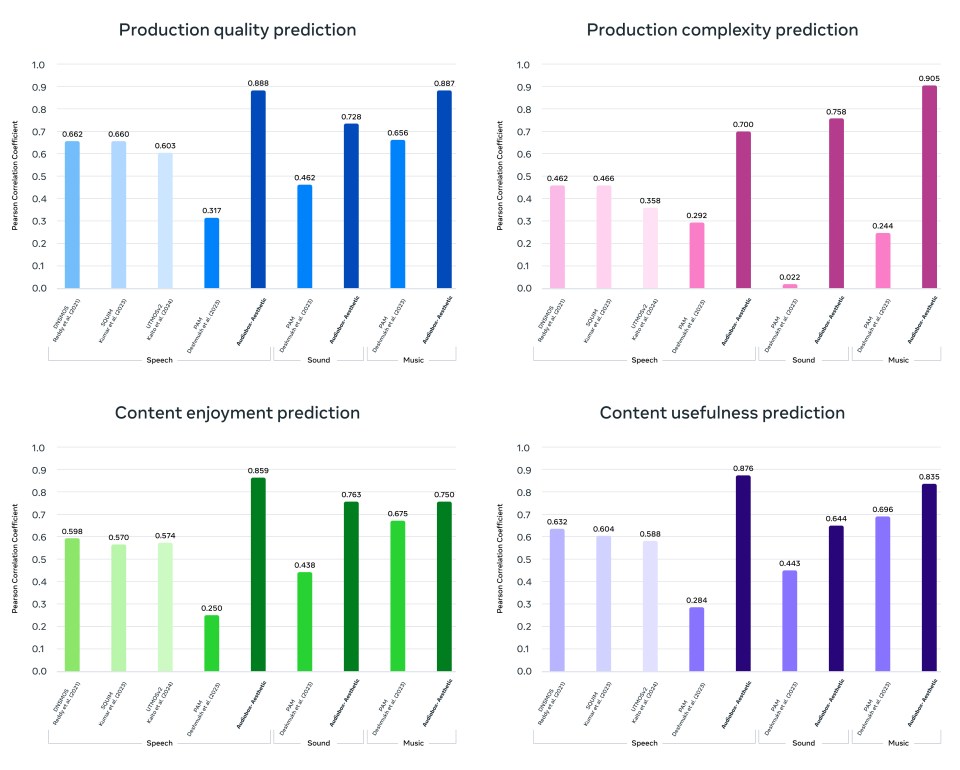
Experimentos extensivos mostraram que o Audiobox Aesthetics superou trabalhos anteriores com maior correlação com o julgamento humano, provando sua eficácia como uma métrica automática para avaliação de qualidade. O modelo, que está sendo lançado com uma licença CC-BY 4.0, também aumenta a qualidade de vários modelos de geração de áudio por meio de filtragem de dados e solicitação de qualidade, alcançando melhorias significativas em aplicativos de texto para fala, texto para música e texto para som.
O Audiobox Aesthetics já foi aproveitado para aprimorar o Meta Movie Gen, ajudando a facilitar o conteúdo multimídia de alta qualidade, impulsionando ainda mais o progresso e a inovação no setor. Esperamos que este trabalho seja usado para aprimorar a qualidade do conteúdo de áudio e dar suporte ao desenvolvimento de modelos de áudio generativos mais sofisticados.
Baixe os pesos e o código do modelo
Transcrições de mensagens de voz do WhatsApp: desbloqueando a comunicação perfeita
À medida que continuamos a construir o futuro da conexão humana e a tecnologia que a torna possível, lançamos uma atualização no WhatsApp para tornar a comunicação ainda mais perfeita. As transcrições de mensagens de voz utilizam tecnologia avançada no dispositivo para gerar transcrições de mensagens de áudio localmente e com segurança, garantindo que as mensagens de voz pessoais sejam criptografadas de ponta a ponta. Atualmente, esse recurso oferece suporte a inglês, espanhol, português e russo, ampliando seu alcance em diversas comunidades.
O desenvolvimento das transcrições de mensagens de voz foi possível aproveitando os insights da pesquisa do FAIR da Meta sobre Seamless Communication. O WhatsApp pode continuar a inovar e melhorar seus serviços usando essa pesquisa, impulsionando, em última análise, o progresso em direção à meta de atingir AMI com recursos multilíngues. Nós exploramos, desenvolvemos e compartilhamos amplamente as melhores práticas para ajuste fino de modelos com a comunidade de pesquisa para os lançamentos públicos de modelos Seamless M4T. Essas técnicas foram aplicadas e aprimoradas ainda mais, junto com a destilação, para ajustá-las ao gênero de mensagens de voz do WhatsApp.
Esse avanço aprimora as experiências das pessoas ao mesmo tempo em que protege as mensagens privadas e prepara o cenário para futuras inovações em comunicação multilíngue.