
Para as pessoas que entendem idiomas como o inglês, o mandarim ou o espanhol, pode parecer que os aplicativos e as ferramentas da web atuais já proporcionam a tecnologia de tradução de que precisamos. Mas há bilhões de pessoas que são deixadas de fora, sem a possibilidade de acessar facilmente a maioria das informações na internet e de se conectar com a maior parte do mundo online em seu idioma nativo. Os atuais sistemas de tradução automática (MT, na sigla em inglês) estão se aprimorando rapidamente, mas ainda dependem muito do aprendizado com grandes quantidades de dados textuais, portanto, geralmente não funcionam bem para idiomas de recursos baixos, ou seja, idiomas que não têm dados para aprendizado de máquina, e para idiomas que não têm um sistema de escrita padronizado.
Eliminar a barreira da língua seria algo profundo, que proporcionaria a bilhões de pessoas o acesso às informações online em seus idiomas nativos ou preferenciais. Os avanços da MT não ajudarão apenas as pessoas que não falam nenhum dos idiomas que dominam a internet atualmente; eles também vão alterar, de maneira fundamental, a forma como as pessoas do mundo inteiro se conectam e compartilham ideias.
E, ao usarmos cada vez mais o metaverso, precisaremos criar espaços virtuais imersivos em que as pessoas possam participar e se comunicar independentemente dos idiomas que elas falam.
Pense, por exemplo, em um mercado em que haja pessoas que falam idiomas diferentes se comunicando em tempo real usando um smartphone, um relógio ou um óculos. Imagine ainda um conteúdo multimídia na web que seja acessível a qualquer pessoa do mundo em seu idioma de preferência. Em um futuro não muito distante, quando as tecnologias emergentes como a realidade virtual e aumentada unirem o mundo digital e o mundo físico no metaverso, as ferramentas de tradução permitirão que as pessoas realizem as atividades do dia a dia, como organizar um clube de leitura ou colaborar em um projeto de trabalho, com qualquer um e em qualquer lugar, da mesma forma que o fariam com um vizinho.
A Meta AI está anunciando uma iniciativa de longo prazo para criar ferramentas de idiomas e MT que incluirão a maioria dos idiomas do mundo. Isso inclui dois novos projetos. O primeiro é o No Language Left Behind (Nenhum Idioma Deixado para Trás, em português), que consiste em construir um novo modelo de inteligência artificial avançada capaz de aprender com idiomas que têm menos exemplos para treinamento. Nós o usaremos para possibilitar traduções de qualidade profissional em centenas de idiomas, como o asturiano, o luganda e o urdu. O segundo é o Universal Speech Translator (Tradutor de Fala Universal, em português), no qual estamos projetando novas abordagens para traduzir a fala em um idioma para outro em tempo real. Assim, poderemos incluir idiomas que não têm um sistema de escrita padrão da mesma forma que aqueles que são falados e escritos.
Será necessário muito mais trabalho para fornecer a todos, no mundo inteiro, ferramentas de tradução realmente universais. Mas nós acreditamos que as iniciativas descritas aqui são um importante passo à frente. Compartilhar os detalhes e liberar nosso código e nossos modelos no futuro significa que outras pessoas poderão aproveitar desse nosso trabalho e nos aproximar da realização desse importante objetivo.
Os desafios de traduzir todos os idiomas
Os sistemas de tradução atuais baseados em IA não são concebidos para atender aos milhares de idiomas usados no mundo inteiro nem para fornecer tradução de fala para fala em tempo real. Para realmente atender a todos, a comunidade de pesquisa em MT precisará enfrentar três desafios importantes. Precisaremos superar a escassez de dados, adquirindo mais dados de aprendizado em mais idiomas e encontrando novas formas de aproveitar os que já estão disponíveis. Precisaremos também superar os desafios de modelagem que surgem à medida que os modelos crescem para atender a muito mais idiomas. E precisaremos ainda encontrar novas formas de avaliar e aprimorar seus resultados.
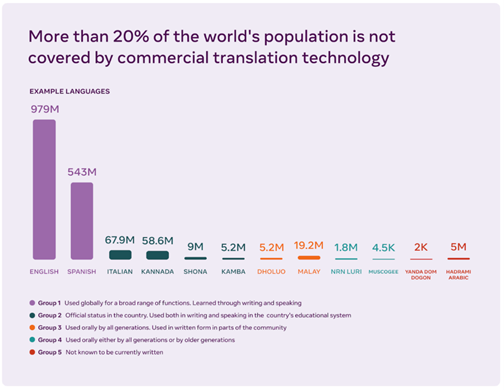
A escassez de dados continua sendo um dos maiores obstáculos para a expansão das ferramentas de tradução para mais idiomas. Normalmente, os sistemas de MT para tradução de textos se baseiam no aprendizado com milhões de frases de dados anotados. Por causa disso, os sistemas de MT capazes de gerar traduções de alta qualidade foram desenvolvidos apenas para os poucos idiomas que dominam a web. A expansão para outros idiomas significa encontrar maneiras de adquirir e usar exemplos para aprendizado de idiomas cuja presença na web é escassa.
Para tradução direta de fala para fala, o desafio de adquirir dados é ainda maior. A maioria dos sistemas de MT de fala usa o texto como etapa intermediária, o que significa que a fala em um idioma é primeiro convertida em texto, depois traduzida para texto no idioma de destino e, por fim, inserida em um sistema de conversão de texto para fala para gerar áudio. Isso faz com que a tradução de fala para fala fique dependente de texto em formas que limitam a sua eficiência e a tornam difícil de ampliar para idiomas que são essencialmente orais.
Os modelos de tradução direta de fala para fala podem permitir a tradução de idiomas que não têm sistemas de escrita padronizados. Essa abordagem também pode levar a sistemas de tradução muito mais eficientes e rápidos, já que eles não precisarão das etapas adicionais de conversão de fala para texto, da tradução deste e da geração de fala no idioma de destino.
Além da necessidade de dados de aprendizado adequados em milhares de idiomas, os sistemas de MT atuais simplesmente não são concebidos para serem ampliados de forma a atender às necessidades de todas as pessoas no mundo inteiro. Muitos sistemas de MT são bilíngues, o que significa que existe um modelo separado para cada par de idiomas, como inglês-russo ou japonês-espanhol. Essa abordagem é extraordinariamente difícil de ampliar para dezenas de pares de idiomas e mais ainda para todos os idiomas em uso no mundo inteiro. Imagine se você precisasse criar e manter muitos milhares de modelos diferentes para cada combinação, de tailandês-laosiano a nepalês-assamês. Vários especialistas já sugeriram que os sistemas multilíngues podem ajudar a resolver o problema. Mas tem sido extremamente difícil incorporar muitos idiomas em um único modelo multilíngue eficiente e de alto desempenho que tenha a capacidade de representar todos os idiomas.
Os modelos de MT de fala para fala em tempo real enfrentam muitos dos mesmos desafios dos modelos baseados em texto, mas também precisam superar a latência — o atraso que ocorre quando um idioma está sendo traduzido para outro — para poderem ser usados com eficácia nas traduções em tempo real. O principal desafio deriva do fato de que uma frase pode ser falada em uma ordem diferente de palavras em idiomas distintos. Até mesmo os profissionais de tradução simultânea apresentam um atraso de aproximadamente três segundos em relação à fala original. Considere uma frase em alemão, “Ich möchte alle Sprachen übersetzen”, e a sua equivalente em espanhol, “Quisiera traducir todos los idiomas”. Ambas significam “Gostaria de traduzir todos os idiomas”. Mas traduzir do alemão para o inglês em tempo real seria mais difícil porque o verbo “traduzir” aparece no final da frase, enquanto a ordem das palavras em espanhol e em inglês é semelhante.
Por fim, ao ampliarmos para cada vez mais idiomas, precisamos também desenvolver novas formas de avaliar o trabalho produzido pelos modelos de MT. Já existem recursos para avaliar a qualidade das traduções entre determinados idiomas, por exemplo, do inglês para o russo; mas e se as traduções forem do amárico para o cazaque? Ao expandirmos o número de idiomas que os nossos modelos de MT são capazes de traduzir, precisaremos também desenvolver novas abordagens com relação aos dados e à mensuração de aprendizado para abranger mais idiomas. Além de avaliar o desempenho dos sistemas de MT com relação à precisão, também é importante assegurar que as traduções sejam feitas de forma responsável. Precisaremos encontrar maneiras de assegurar que os sistemas de MT preservem as sensibilidades culturais e não criem nem intensifiquem vieses. Como descrito nas seções abaixo, a Meta AI está trabalhando com cada um desses três desafios.
Treinando sistemas de tradução direta de fala para fala e de recursos baixos
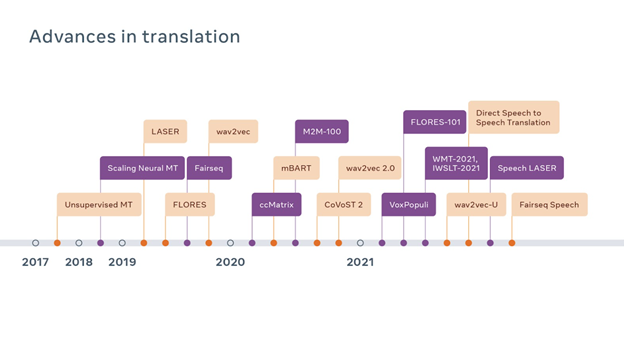
Para possibilitar as traduções de idiomas de recursos baixos e para criar os elementos básicos para futuras traduções de mais idiomas independentemente de quanto eles sejam falados ou escritos, estamos expandindo nossas técnicas de criação automática de conjuntos de dados. Uma dessas técnicas é o LASER, um kit de ferramentas de código aberto que atualmente abrange mais de 125 idiomas escritos em 28 scripts diferentes.
O LASER converte frases de vários idiomas em uma única representação multilíngue. Em seguida, usamos uma pesquisa de semelhança multilíngue em grande escala para identificar frases que têm uma representação semelhante, ou seja, que provavelmente têm o mesmo significado em diferentes idiomas. Usamos o LASER para construir sistemas como o ccMatrix e o ccAligned, que são capazes de localizar textos paralelos na internet. Devido à escassez de dados disponíveis para os idiomas de recursos baixos, criamos um novo método de aprendizado professor-aluno que permite que o LASER se concentre em subgrupos de idiomas específicos, como os idiomas bantos, e aprenda com conjuntos de dados muito menores. Isso permite que o LASER opere em escala com vários idiomas de forma eficaz. Cada um desses progressos nos permitirá abranger mais idiomas à medida que avançamos no seu dimensionamento, aprimoramento e expansão para incluir mineração de dados para centenas de idiomas e, por fim, para todos os idiomas que têm um sistema de escrita. Recentemente, estendemos o LASER para que funcione também com a fala: graças à construção de representações para fala e texto no mesmo espaço multilíngue, conseguimos extrair traduções entre fala em um idioma e texto em outro e até mesmo traduções diretas de fala para fala. Com esse método, já identificamos cerca de 1.400 horas de fala alinhada em francês, alemão, espanhol e inglês.
Os dados de texto são importantes, mas não são suficientes para construir ferramentas de tradução que atendam às necessidades de todos. Anteriormente, havia disponibilidade de dados de referência de tradução de fala para uns poucos idiomas, por isso criamos o CoVoST 2, que abrange 22 idiomas e 36 direções linguísticas com diferentes condições de recursos. Além disso, é difícil encontrar grandes quantidades de áudio em diferentes idiomas. O VoxPopuli, que contém 400 mil horas de fala em 23 idiomas, permite o aprendizado em grande escala semissupervisionado e autossupervisionado para programas como reconhecimento de fala e tradução de fala. Posteriormente, o VoxPopuli foi usado para construir o maior modelo pré-treinado aberto e universal para 128 idiomas e tarefas de fala, incluindo a tradução de fala. Esse modelo aprimorou o modelo de ponta anterior para a tradução de fala para texto de 21 idiomas para o inglês em 7.4 BLEU no conjunto de dados CoVoST 2.
Construindo modelos que funcionam em muitos idiomas e diferentes modalidades

Além de produzir mais dados para treinar os sistemas de MT e torná-los disponíveis para outros pesquisadores, estamos trabalhando para aprimorar a capacidade do modelo e poder assim lidar com traduções entre um conjunto de idiomas muito mais amplo. Os sistemas de MT atuais frequentemente funcionam em uma única modalidade e em um conjunto de idiomas limitado. Se o modelo for pequeno demais para representar muitos idiomas, o seu desempenho poderá ser prejudicado, introduzindo erros tanto nas traduções de texto como nas de fala. As inovações na modelagem nos ajudarão a criar um futuro em que as traduções serão transferidas de forma rápida e fluida entre diferentes modalidades, indo de fala para texto, de texto para fala, de texto para texto e de fala para fala em inúmeros idiomas.
Para obter um desempenho aprimorado de nossos modelos de MT, investimos muito na criação de modelos que apresentem um aprendizado eficiente apesar de sua grande capacidade, com foco em modelos de especialidades mistas restringidos de forma esparsa. Aumentando o tamanho do modelo e aprendendo uma função de roteamento automático de forma que tokens diferentes usem recursos de especialidades diferentes, conseguimos equilibrar o desempenho das traduções de recursos altos e de recursos baixos.
Para ampliar uma MT baseada em texto para 101 idiomas, criamos o primeiro sistema de tradução de texto multilíngue não centrado no inglês. Os sistemas bilíngues geralmente funcionam traduzindo primeiro do idioma de origem para o inglês e, em seguida, do inglês para o idioma de destino. Para tornar esses sistemas mais eficientes e aumentar a sua qualidade, eliminamos o inglês como meio, de maneira que os idiomas possam ser traduzidos diretamente para outros idiomas sem passar pelo inglês. Embora a eliminação do inglês tenha aumentado a capacidade do modelo, os modelos multilíngues anteriormente não eram capazes de atingir o mesmo nível de qualidade do que os sistemas bilíngues feitos sob medida. Recentemente, no entanto, nosso sistema de tradução multilíngue ganhou o concurso Workshop on Machine Translation, superando até mesmo os melhores modelos bilíngues.
Queremos que a nossa tecnologia seja inclusiva: ela deve abranger tanto os idiomas escritos como os idiomas que não têm sistema de escrita padronizado. Pensando nisso, estamos desenvolvendo um sistema de tradução de fala para fala que não depende da geração de uma representação textual intermediária durante a inferência. Foi demonstrado que essa abordagem é mais rápida do que os sistemas tradicionais em cascata que combinam modelos separados de reconhecimento de fala, tradução automática e síntese de fala. Com maior eficiência e uma arquitetura mais simples, a tradução direta de fala para fala pode proporcionar uma tradução em tempo real de qualidade quase humana para futuros dispositivos, como óculos de realidade aumentada. Por fim, para criar traduções faladas que preservem a expressividade e a singularidade na fala das pessoas, estamos trabalhando para incluir alguns aspectos do áudio de entrada, como a entonação, nas traduções geradas de áudio.
Mensurando o sucesso em centenas de idiomas
O desenvolvimento de modelos em grande escala que possam traduzir entre muito mais idiomas faz surgir uma pergunta importante: como podemos determinar se desenvolvemos dados ou modelos melhores? Avaliar o desempenho de um modelo multilíngue em grande escala é complicado, especialmente porque requer um conhecimento aprofundado de todos os idiomas que o modelo abrange — um desafio que é demorado, demanda muitos recursos e frequentemente é inviável.
Nós criamos o FLORES-101, o primeiro conjunto de dados de avaliação de tradução multilingue que abrange 101 idiomas, permitindo que os pesquisadores testem e aprimorem rapidamente os modelos de tradução multilíngues. Diferentemente dos conjuntos de dados existentes, o FLORES-101 permite que os pesquisadores quantifiquem o desempenho dos sistemas em qualquer direção linguística, e não apenas de traduções de/para o inglês. Para os milhões de pessoas do mundo inteiro que vivem em locais com dezenas de idiomas oficiais, isso permite a criação de sistemas de tradução que atendem a necessidades importantes do mundo real.
Usando o FLORES-101, temos colaborado com outros líderes da comunidade de pesquisa em IA para fazer avançar a tradução multilíngue com recursos baixos. No Workshop on Machine Translation de 2021, organizamos uma tarefa compartilhada para fazer progressos nesta área de forma coletiva. Houve a participação de pesquisadores do mundo inteiro, muitos dos quais com foco em idiomas pessoalmente relevantes para eles. Esperamos continuar expandindo o FLORES para abranger centenas de idiomas.
Ao fazermos progressos tangíveis em direção a uma tradução universal, também nos concentramos em fazer isso de forma responsável. Estamos trabalhando em colaboração com linguistas para entender os desafios de produzir coleções de conjuntos de dados corretos e com redes de avaliadores para assegurar que as traduções sejam corretas. Também estamos realizando estudos de caso com falantes de mais de 20 idiomas, para saber quais características da tradução são importantes para as pessoas com diferentes históricos e como elas usarão as traduções que nossos modelos de IA produzem. Existem muitos outros aspectos para o desenvolvimento responsável de uma tradução universal, incluindo a diminuição do viés e da toxicidade e a preservação das sensibilidades culturais ao passar as informações de um idioma para outro. Para alcançarmos nossos objetivos de longo prazo em relação à tradução, precisaremos não apenas de conhecimento em IA, mas também da contribuição contínua de diversos especialistas, pesquisadores e indivíduos do mundo inteiro.
Qual é o próximo passo?
Se o No Language Left Behind e o Universal Speech Translator, combinados com as iniciativas da comunidade de pesquisa em MT, conseguirem criar tecnologias de tradução que incluam todos os habitantes do planeta, isso abrirá o mundo digital e o mundo físico de maneiras que antes não eram possíveis. Já estamos fazendo progressos no sentido de possibilitar traduções envolvendo idiomas com poucos recursos, uma barreira significativa à tradução universal para a maior parte da população do mundo. Ao avançar e abrir o código do nosso trabalho na criação de corpus, modelagem multilíngue e avaliação, esperamos que outros pesquisadores possam se basear nesse trabalho e aproximar da realidade os verdadeiros usos de sistemas de tradução.
A nossa capacidade de comunicação é um dos aspectos mais fundamentais do ser humano. As tecnologias, da prensa móvel ao bate-papo em vídeo, têm frequentemente transformado nossa maneira de nos comunicar e compartilhar ideias. O poder dessas e de outras tecnologias se estenderá quando elas puderem funcionar da mesma forma para bilhões de pessoas no mundo inteiro, proporcionando-lhes um acesso semelhante às informações e permitindo que se comuniquem com um público muito mais amplo, independentemente dos idiomas que elas falam ou escrevem. À medida que nos esforçamos para construir um mundo mais inclusivo e conectado, será ainda mais importante derrubar as barreiras que impedem o acesso às informações e às oportunidades, capacitando as pessoas nos idiomas que elas escolherem.