
Um dos dos esforços centrais da IA do Facebook é a implementação de tecnologia de aprendizagem automática de ponta para proteger as pessoas de conteúdos prejudiciais. Com milhões de pessoas utilizando as nossas plataformas, usamos a IA para expandir o trabalho da nossa revisão de conteúdos e automatizar as decisões sempre que possível. O nosso objetivo é detectar de forma rápida e precisa o discurso de ódio, informações incorretas e outros tipos de conteúdos que desrespeitem as nossas políticas, em todas as formas de conteúdos e todos os idiomas e comunidades de todo o mundo.
Para concretizarmos este objetivo como um todo são necessários muitos mais avanços técnicos na IA. Mas temos progredido muito e hoje os nossos sistemas automatizados são os primeiros a serem utilizados na revisão de conteúdos em violações de todos os tipos. O nosso investimento e a nossa melhoria contínua podem ser consultados no Relatório de Aplicação dos Padrões da Comunidade, que publicamos hoje.
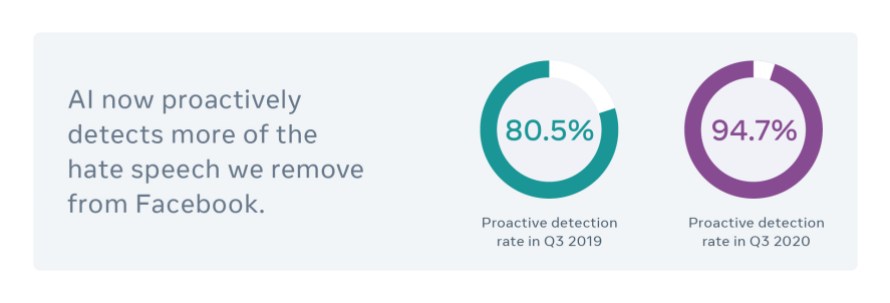
Agora, a IA detecta proativamente 94,7% do discurso de ódio que removemos do Facebook, em comparação com os 80,5% registrados há um ano e com os apenas 24% de 2017.
Este aumento foi gerado pelos avanços nas nossas ferramentas de detecção automática, como a implementação de XLM, o método de IA do Facebook que treina os sistemas de linguagem em múltiplos idiomas sem depender de conjuntos de dados identificados à mão. Implementamos recentemente novos sistemas que melhoraram ainda mais a nossa capacidade de detectar o discurso de ódio. Esses sistemas incluem o Reinforced Integrity Optimizer, um sistema que aprende a partir de exemplos e indicadores reais, e a nossa arquitetura de IA Linformer, que nos permite utilizar modelos de compreensão de idiomas de ponta que, antes, eram grandes e pesados demais para poderem ser trabalhados em escala.
Claro que o discurso de ódio não é o único conteúdo que precisamos detectar. Também temos mais detalhes sobre a nossa nova tecnologia de IA para lidar com as informações incorretas. Entre esses detalhes estão o SimSearchNet, a ferramenta de correspondência de imagens que apresentamos este ano, e a criação de uma nova ferramenta de detecção de técnicas deepfake que pode aprender e se adaptar no decorrer do tempo.
Em conjunto, todas estas inovações se traduzem num entendimento dos conteúdos mais profundos e amplos por parte dos nossos sistemas de IA. Estão mais sintonizadas para as coisas que as pessoas compartilham nas nossas plataformas neste momento, para que possam se adaptar mais depressa quando um meme ou foto nova surgir e viralizar.
Estes desafios são complexos, variados e evoluem rapidamente. É fundamental não só detectar os problemas, mas também evitar erros, uma vez que classificar um conteúdo de forma errada como informação incorreta ou discurso de ódio pode prejudicar a capacidade de as pessoas se expressarem na nossa plataforma. A melhoria contínua exigirá não só uma tecnologia melhor, como também uma excelência operacional e parcerias eficazes com especialistas externos.
Embora estejamos constantemente melhorando as nossas ferramentas de IA, estas estão longe de ser perfeitas. Sabemos que ainda temos muito trabalho pela frente e estamos criando e testando sistemas novos que nos ajudem a fazer mais para proteger as pessoas que recorrem à nossa plataforma.
Aprendizagem completa e modelos novos e eficientes para detectar discurso de ódio
Detectar alguns discursos de ódio é muito simples para a IA e para os humanos. A difamação e os símbolos de ódio representam ataques óbvios à raça ou à religião de alguém. Contudo, existem muitos tipos de discurso de ódio mais complexos. A combinação de textos e imagens faz com que seja mais difícil à IA perceber se o significado pretendido é ofensivo, mesmo que um humano o possa achar óbvio. Também se pode recorrer ao sarcasmo ou a gírias para disfarçar o discurso de ódio ou até mesmo a imagens aparentemente inócuas que são encaradas de formas diferentes em culturas, regiões e idiomas distintos.
Para melhor responder a estes desafios, criamos e implementamos um novo framework de aprendizagem reforçada, denominado Reinforced Integrity Optimizer (RIO). Em vez de se basear num conjunto de dados offline e estático (logo limitado), o RIO utiliza diretamente dados online do mundo real dos nossos sistemas de produção para otimizar os modelos de IA que detectam o discurso de ódio. O RIO funciona em todo o ciclo de vida de desenvolvimento de aprendizagem automática, desde a amostragem de dados aos testes A/B.
Nos sistemas de IA tradicionais, os engenheiros otimizam estes passos em dois processos separados: otimização offline e experimentação online. Na otimização offline, os engenheiros podem utilizar várias ferramentas para ajudar a escolher o conjunto certo de preparação/teste e a arquitetura neural adequada, mas baseiam-se apenas em indicadores offline, como a precisão e a evocação. Depois, o modelo também é otimizado offline, mediante a utilização dos testes A/B, para perceber o impacto do mesmo nos indicadores de utilizadores e negócios online.
O RIO segue uma abordagem completamente diferente. Otimiza todos os passos deste processo ao mesmo tempo e utiliza indicadores reais de desempenho de produção para ajustar os componentes offline. Este nível de otimização completa permite um desempenho significativamente melhor e uma interação mais rápida. Em vez de fazer o trabalho offline e, depois, aplicá-lo à produção para ver se funciona conforme o esperado, o sistema online enfrenta o verdadeiro desafio.
O RIO nos permite concentrar o nosso treino de modelos nas violações da nossa política contra o discurso de ódio, que antes passavam despercebidas pelos nossos modelos de produção.
Utilizando os dados de preparação certos do RIO, podemos utilizar modelos de compreensão de conteúdos de ponta para criar classificadores eficazes. Nos últimos anos, os investigadores melhoraram significativamente o desempenho dos modelos de linguagem através da utilização do Transformers, um mecanismo que ensina à IA as partes de um texto às quais deve ter atenção. Contudo, os maiores e mais avançados modelos do Transformer podem ter milhares de milhões de parâmetros. A sua elevada complexidade computacional, por norma expressa como O(N^2), significa que não são suficientemente eficientes para implementação em escala na produção e funcionam em tempo quase real para detectar o discurso de ódio.
Para aumentar a eficiência dos modelos do Transformer, os investigadores do Facebook AI desenvolveram uma arquitetura nova, chamada Linformer. O Linformer proporciona uma forma muito mais eficiente de utilizar modelos massivos e de ponta para compreender os conteúdos. Agora, utilizamos o RIO e o Linformer em produção para analisar milhares de milhões de conteúdos do Facebook e do Instagram em diferentes regiões de todo o mundo. Compartilhamos o nosso trabalho e o código do Linformer com a comunidade de investigação de IA, para que possamos aprender com os trabalhos uns dos outros e acelerar o progresso para todos.
Compreensão supervisionada de forma autônoma, holística e multimodal
O RIO e o Linformer nos ajudam a preparar os nossos sistemas de forma mais eficaz e a utilizar modelos avançados de compreensão de conteúdos. Contudo, há partes do discurso de ódio ou de incitação à violência que podem ser mais complexas do que um mero texto. Em alguns dos exemplos mais difíceis, vemos que parte do conteúdo de ódio é transmitido através de uma imagem ou vídeo e outra através de texto. Vistas isoladamente, estas diferentes partes podem ser benignas. No entanto, se vistas em conjunto, se tornam ofensivas.
 Para identificar este meme como discurso de ódio, a IA tem que entender a imagem e o texto em conjunto.
Para identificar este meme como discurso de ódio, a IA tem que entender a imagem e o texto em conjunto.
Conforme mostrado nos exemplos anteriores, estes cenários exigem uma compreensão mais holística do conteúdo em causa. Para facilitar essa compreensão, criamos o Whole Post Integrity Embeddings (WPIE), uma representação universal pré-preparada dos conteúdos para problemas de integridade. O WPIE funciona ao compreender os conteúdos entre modalidades, tipos de infração e até mesmo do tempo. A última versão é preparada com mais infrações e mais dados de preparação de um modo geral. O sistema melhora o desempenho ao nível das várias modalidades, como texto e imagem, mediante a utilização de perda focal. Esta abordagem impede que o detector seja sobrecarregado com exemplos fáceis de classificar durante a preparação, juntamente com a mistura de gradientes, que calcula uma mistura ideal de modalidades com base nos seus comportamentos dominantes.
Também utilizamos a aprendizagem supervisionada de forma autônoma e pós-nível para criar uma representação universal de conteúdos pré-preparada para problemas de integridade. E desenvolvemos o XLM-R, um modelo que usa a arquitetura de IA RoBERTa de ponta, para melhorar os nossos classificadores de discurso de ódio em idiomas diferentes no Facebook e no Instagram. O XLM-R também faz agora parte do nosso sistema para expandir a funcionalidade do Centro da comunidade sobre a COVID-19 internacionalmente.
Temos muito mais trabalho pela frente. A detecção do discurso de ódio não é só um desafio difícil, mas também um trabalho que está em constante evolução. Um conteúdo de discurso de ódio novo poderá não ser semelhante aos exemplos anteriores porque menciona uma tendência nova ou uma notícia nova. Criamos as ferramentas como o RIO e o WPIE para que possam crescer e dar resposta aos desafios futuros e aos atuais. Com uma IA mais flexível e adaptativa, estamos confiantes de que podemos continuar fazendo progressos reais.