Update on November 2, 2021 at 12:05 PM PT:
Today we announced a significant reduction in our use of facial recognition technology, including the deletion of face recognition templates that we previously used to identify faces in photos. This means automatic alt text will still be able to recognize when a person is in a photo, but it will no longer include names of people.
Originally posted on January 19, 2021 at 10:00 AM PT:
When Facebook users scroll through their News Feed, they find all kinds of content — articles, friends’ comments, event invitations, and of course, photos. Most people are able to instantly see what’s in these images, whether it’s their new grandchild, a boat on a river, or a grainy picture of a band onstage. But many users who are blind or visually impaired (BVI) can also experience that imagery, provided it’s tagged properly with alternative text (or “alt text”). A screen reader can describe the contents of these images using a synthetic voice and enable people who are BVI to understand images in their Facebook feed.
Unfortunately, many photos are posted without alt text, so in 2016 we introduced a new technology called automatic alternative text (AAT). AAT — which was recognized in 2018 with the Helen Keller Achievement Award from the American Foundation for the Blind — utilizes object recognition to generate descriptions of photos on demand so that blind or visually impaired individuals can more fully enjoy their News Feed. We’ve been improving it ever since and are excited to unveil the next generation of AAT.
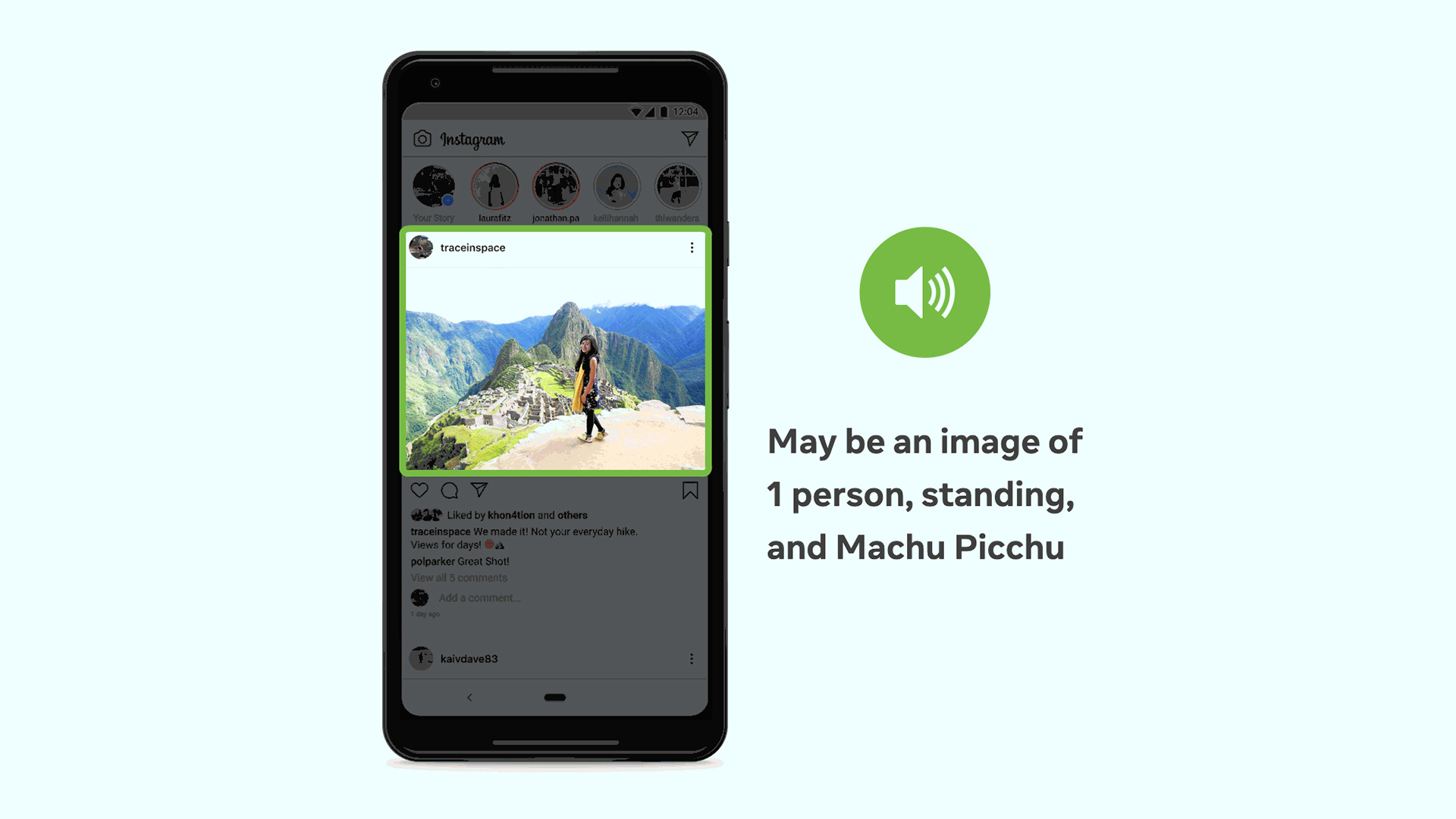
The latest iteration of AAT represents multiple technological advances that improve the photo experience for our users. First and foremost, we’ve expanded the number of concepts that AAT can reliably detect and identify in a photo by more than 10x, which in turn means fewer photos without a description. Descriptions are also more detailed, with the ability to identify activities, landmarks, types of animals, and so forth — for example, “May be a selfie of 2 people, outdoors, the Leaning Tower of Pisa.”

And we’ve achieved an industry first by making it possible to include information about the positional location and relative size of elements in a photo. So instead of describing the contents of a photo as “May be an image of 5 people,” we can specify that there are two people in the center of the photo and three others scattered toward the fringes, implying that the two in the center are the focus. Or, instead of simply describing a lovely landscape with “May be a house and a mountain,” we can highlight that the mountain is the primary object in a scene based on how large it appears in comparison with the house at its base.
Taken together, these advancements help users who are blind or visually impaired better understand what’s in photos posted by their family and friends — and in their own photos — by providing more (and more detailed) information.
Where we Started
The concept of alt text dates back to the early days of the internet, providing slow dial-up connections with a text alternative to downloading bandwidth-intensive images. Of course, alt text also helped people who are blind or visually impaired navigate the internet, since it can be used by screen reader software to generate spoken image descriptions. Unfortunately, faster internet speeds made alt text less of a priority for many users. And since these descriptions needed to be added manually by whoever uploaded an image, many photos began to feature no alt text at all — with no recourse for the people who had relied on it.
Nearly five years ago, we leveraged Facebook’s computer vision expertise to help solve this problem. The first version of AAT was developed using human-labeled data, with which we trained a deep convolutional neural network using millions of examples in a supervised fashion. Our completed AAT model could recognize 100 common concepts, like “tree,” “mountain,” and “outdoors.” And since people who use Facebook often share photos of friends and family, our AAT descriptions used facial recognition models that identified people (as long as those people gave explicit opt-in consent). For people who are BVI, this was a giant step forward.
Seeing More of the World
But we knew there was more that AAT could do, and the next logical step was to expand the number of recognizable objects and refine how we described them.
To achieve this, we moved away from fully supervised learning with human-labeled data. While this method delivers precision, the time and effort involved in labeling data are extremely high — and that’s why our original AAT model reliably recognized only 100 objects. Recognizing that this approach would not scale, we needed a new path forward.
For our latest iteration of AAT, we leveraged a model trained on weakly supervised data in the form of billions of public Instagram images and their hashtags. To make our models work better for everyone, we fine-tuned them so that data was sampled from images across all geographies, and using translations of hashtags in many languages. We also evaluated our concepts along gender, skin tone, and age axes. The resulting models are both more accurate and culturally and demographically inclusive — for instance, they can identify weddings around the world based (in part) on traditional apparel instead of labeling only photos featuring white wedding dresses.
It also gave us the ability to more readily repurpose machine learning models as the starting point for training on new tasks — a process known as transfer learning. This enabled us to create models that identified concepts such as national monuments, food types (like fried rice and french fries), and selfies. This entire process wouldn’t have been possible in the past.
To get richer information like position and counts, we also trained a two-stage object detector, called Faster R-CNN, using Detectron2, an open source platform for object detection and segmentation developed by Facebook AI Research. We trained the models to predict locations and semantic labels of the objects within an image. Multilabel/multi–data set training techniques helped make our model more reliable with the larger label space.
The improved AAT reliably recognizes over 1,200 concepts — more than 10 times as many as the original version we launched in 2016. As we consulted with screen reader users regarding AAT and how best to improve it, they made it clear that accuracy is paramount. To that end, we’ve included only those concepts for which we could ensure well-trained models that met a certain high threshold of precision. While there is a margin for error, which is why we start every description with “May be,” we’ve set the bar very high and have intentionally omitted concepts that we couldn’t reliably identify.
We want to give our users who are blind or visually impaired as much information as possible about a photo’s contents — but only correct information.
Delivering Details
Having increased the number of objects recognized while maintaining a high level of accuracy, we turned our attention to figuring out how to best describe what we found in a photo.
We asked users who depend on screen readers how much information they wanted to hear and when they wanted to hear it. They wanted more information when an image is from friends or family, and less when it’s not. We designed the new AAT to provide a succinct description for all photos by default but offer an easy way to get more detailed descriptions about photos of specific interest.

When users select that latter option, a panel is presented that provides a more comprehensive description of a photo’s contents, including a count of the elements in the photo, some of which may not have been mentioned in the default description. Detailed descriptions also include simple positional information — top/middle/bottom or left/center/right — and a comparison of the relative prominence of objects, described as “primary,” “secondary,” or “minor.” These words were specifically chosen to minimize ambiguity. Feedback on this feature during development showed that using a word like “big” to describe an object could be confusing because it’s unclear whether the reference is to its actual size or its size relative to other objects in an image. Even a Chihuahua looks large if it’s photographed up close!
AAT uses simple phrasing for its default description rather than a long, flowy sentence. It’s not poetic, but it is highly functional. Our users can read and understand the description quickly — and it lends itself to translation so all the alt text descriptions are available in 45 different languages, ensuring that AAT is useful to people around the world.
Facebook is for Everyone
Every day, our users share billions of photos. The ubiquity of inexpensive cameras in mobile phones, fast wireless connections, and social media products like Instagram and Facebook have made it easy to capture and share photography and help make it one of the most popular ways to communicate — including for individuals who are blind or visually impaired. While we wish everyone who uploaded a photo would include an alt text description, we recognize that this often doesn’t happen. We built AAT to bridge this gap, and the impact it’s had on those who need it is immeasurable. AI promises extraordinary advances, and we’re excited to have the opportunity to bring these advances to communities that are so often underserved.


