
When it comes to the News Feed algorithm, there are many theories and myths. Most people understand that there’s an algorithm at work, and many know some of the factors that inform that algorithm (whether you like a post or engage with it, etc.). But there’s still quite a lot that’s misunderstood.
We publicly share many of the details and features of News Feed. But under the hood, the machine learning (ML) ranking system that powers News Feed is incredibly complex, with many layers. We are sharing new details about how our ranking system works and the challenges of building a system to personalize the content for more than 2 billion people and show each of them content that is relevant and meaningful for them, every time they come to Facebook.
What’s So Hard About This?
First, the volume is enormous. More than 2 billion people around the world use Facebook. For each of those people, there are more than a thousand “candidate” posts (or posts that could potentially appear in that person’s feed). We are now talking about trillions of posts across all the people on Facebook.
Now consider that for each person on Facebook, there are thousands of signals that we need to evaluate to determine what that person might find most relevant. So we have trillions of posts and thousands of signals — and we need to predict what each of those people wants to see in their feed instantly. When you open up Facebook, that process happens in the background in just the second or so it takes to load your News Feed.
And once we’ve got all this working, things change, and we need to factor in new issues that arise, such as clickbait and the spread of misinformation. When this happens, we need to find new solutions. In reality, the ranking system is not just one single algorithm; it’s multiple layers of ML models and rankings that we apply in order to predict the content that’s most relevant and meaningful for each user. As we move through each stage, the ranking system narrows down those thousands of candidate posts to the few hundred that appear in someone’s News Feed at any given time.
How Does it Work?
Put simply, the system determines which posts show up in your News Feed, and in what order, by predicting what you’re most likely to be interested in or engage with. These predictions are based on a variety of factors, including what and whom you’ve followed, liked, or engaged with recently. To understand how this works in practice, let’s start with what happens for one person logging in to Facebook: We’ll call him Juan.
Since Juan’s login yesterday, his friend Wei posted a photo of his cocker spaniel. Another friend, Saanvi, posted a video from her morning run. His favorite Page published an interesting article about the best way to view the Milky Way at night, while his favorite cooking Group posted four new sourdough recipes.
All this content is likely to be relevant or interesting to Juan because he has chosen to follow the people or Pages sharing it. To decide which of these things should appear higher in Juan’s News Feed, we need to predict what matters most to him and which content carries the highest value for him. In mathematical terms, we need to define an objective function for Juan and perform a single-objective optimization.
We can use the characteristics of a post, such as who is tagged in a photo and when it was posted, to predict whether Juan might like it. For example, if Juan tends to interact with Saanvi’s posts (e.g., sharing or commenting) often and her running video is very recent, there is a high probability that Juan will like her post. If Juan has engaged with more video content than photos in the past, the like prediction for Wei’s photo of his cocker spaniel might be fairly low. In this case, our ranking algorithm would rank Saanvi’s running video higher than Wei’s dog photo because it predicts a higher probability that Juan would like it.
But liking is not the only way people express their preferences on Facebook. Every day, people share articles they find interesting, watch videos from people or celebrities they follow, or leave thoughtful comments on their friends’ posts. Mathematically, things get more complex when we need to optimize for multiple objectives that all add up to our primary objective: creating the most long-term value for people by showing them content that is meaningful and relevant to them.
Multiple ML models produce multiple predictions for Juan: the probability that he’ll engage with Wei’s photo, Saanvi’s video, the Milky Way article, or the sourdough recipes. Each model tries to rank these pieces of content for Juan. Sometimes they disagree — there might be a higher probability that Juan would like Saanvi’s running video than the Milky Way article, but he might be more likely to comment on the article than on the video. So we need a way to combine these varying predictions into one score that’s optimized for our primary objective of long-term value.
How can we measure whether something creates long-term value for a person? We ask them. For example, we survey people to ask how meaningful they found an interaction with their friends or whether a post was worth their time so that our system reflects what people say they enjoy and find meaningful. Then we can take each prediction into account for Juan based on the actions that people tell us (via surveys) are more meaningful and worth their time.
Peeling Back the Layers
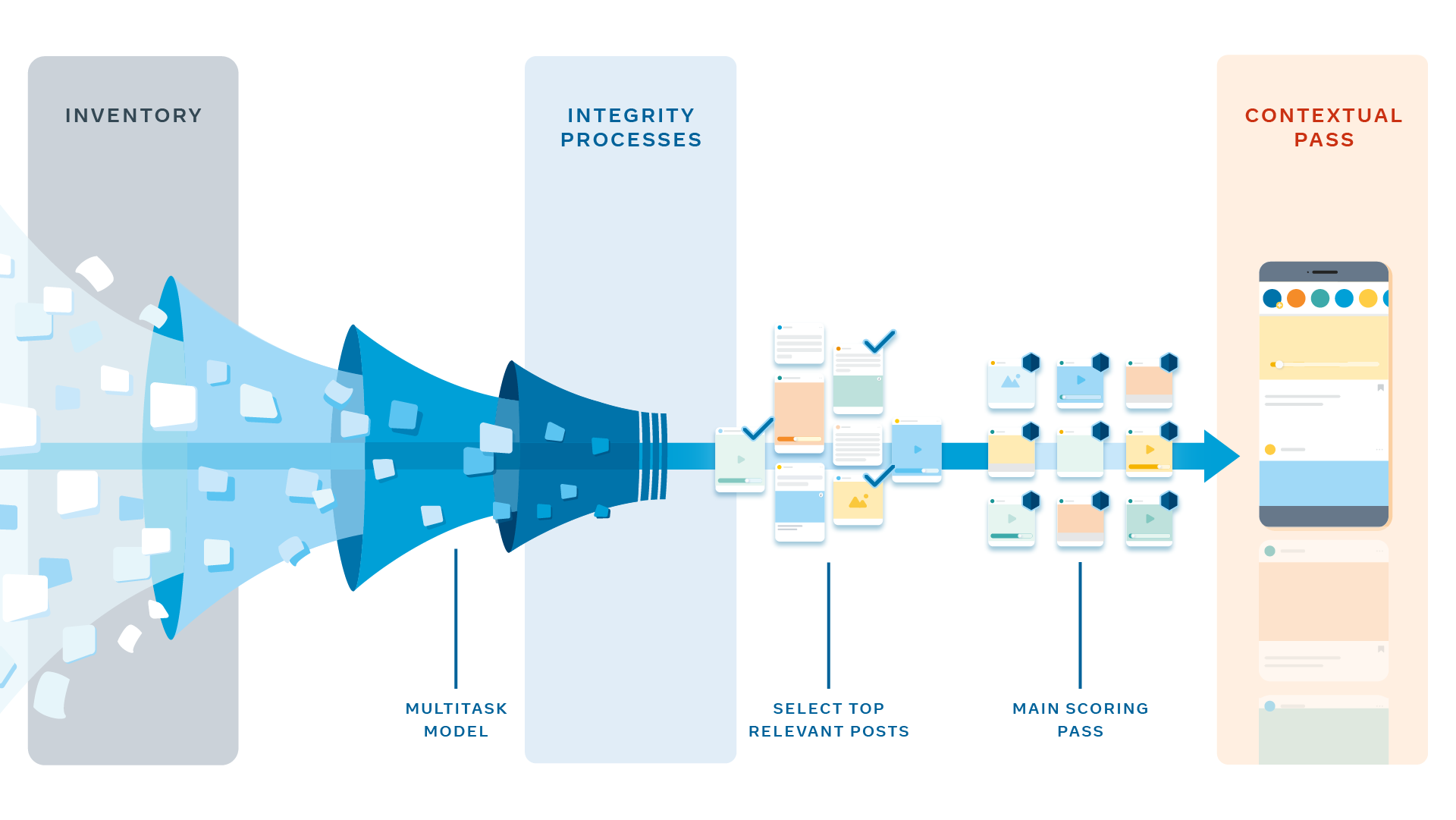
To rank more than a thousand posts per user, per day, for more than 2 billion people — in real time — we need to make the process efficient. We manage this in various steps, strategically arranged to make it fast and to limit the amount of computing resources required.
First, the system collects all the candidate posts we can possibly rank for Juan (the cocker spaniel photo, the running video, etc.). This eligible inventory includes any post shared with Juan by a friend, Group, or Page he’s connected to that was made since his last login and has not been deleted. But how should we handle posts created before Juan’s last login that he hasn’t seen yet?
To make sure unseen posts are reconsidered, we apply an unread bumping logic: Fresh posts that were ranked for Juan (but not seen by him) in his previous sessions are added to the eligible inventory for this session. We also apply an action-bumping logic so that any posts Juan has already seen that have since triggered an interesting conversation among his friends are added to the eligible inventory as well.
Next, the system needs to score each post for a variety of factors, such as the type of post, similarity to other items, and how much the post matches what Juan tends to interact with. To calculate this for more than 1,000 posts, for each of the billions of users — all in real time — we run these models for all candidate stories in parallel on multiple machines, called predictors.
Before we combine all these predictions into a single score, we need to apply some additional rules. We wait until after we have these first predictions so that we can narrow the pool of posts to be ranked — and we apply them over multiple passes to save computational power.
First, certain integrity processes are applied to every post. These are designed to determine which integrity detection measures, if any, need to be applied to the stories selected for ranking. In the next pass, a lightweight model narrows the pool of candidates to approximately 500 of the most relevant posts for Juan. Ranking fewer stories allows us to use more powerful neural network models for the next passes.
Next is the main scoring pass, where most of the personalization happens. Here, a score for each story is calculated independently, and then all 500 posts are put in order by score. For some, the score may be higher for likes than for commenting, as some people like to express themselves more through liking than commenting. Any action a person rarely engages in (for instance, a like prediction that’s very close to zero) automatically gets a minimal role in ranking, as the predicted value is very low.
Finally, we run the contextual pass, in which contextual features like content type diversity rules are added to make sure Juan’s News Feed has a good mix of content types and he’s not seeing multiple video posts, one after another. All these ranking steps happen in the time it takes for Juan to open the Facebook app, and within seconds, he has a scored News Feed that’s ready for him to browse and enjoy.


