Por Angela Fan, Investigadora Científica; Sergey Edunov, Gerente de Ingeniería de Investigación; Paco Guzman, Gerente de Investigación; Juan Pino, Investigador Científico
Es posible que las personas que entienden idiomas como inglés, mandarín o español, crean que las apps y herramientas web actuales ya ofrecen la tecnología de traducción que necesitamos. Sin embargo, esta no incluye a miles de millones de personas que no pueden acceder con facilidad a gran parte de la información online ni conectarse en su idioma nativo con el mundo en internet. Los sistemas de traducción automática de hoy están mejorando con rapidez, pero todavía dependen mucho del aprendizaje basado en datos de texto, por lo que no funcionan muy bien para idiomas que no cuentan con datos de entrenamiento y los que no tienen un sistema de escritura estandarizado.
Superar el obstáculo del idioma sería clave, dado que ayudaría a miles de millones de personas a acceder a información online en su lengua nativa o de preferencia. Los avances en la traducción automática no solo ayudarían a quienes no hablan uno de los idiomas que dominan el internet actual, sino que también cambiarían fundamentalmente el modo en que las personas se conectan y comparten ideas.
Y, a medida que desarrollemos el metaverso, necesitaremos trabajar para ofrecer espacios virtuales inmersivos donde las personas puedan participar y comunicarse con los demás, independientemente del idioma que hablen.
Imaginemos, por ejemplo, un mercado en el que las personas hablen diferentes lenguas y se puedan comunicar entre sí en tiempo real usando un teléfono, un reloj o unos lentes, o contenido multimedia en la web al que cualquier persona del mundo pueda acceder en su idioma de preferencia. En un futuro no muy lejano, cuando las tecnologías emergentes, como la realidad virtual y aumentada, unan al mundo físico con el digital en el metaverso, las herramientas de traducción permitirán a las personas realizar actividades diarias (por ejemplo, organizar un club de lectura o colaborar en un proyecto laboral) con cualquier persona, en cualquier lugar, como lo harían con un vecino.
Meta AI lanza una iniciativa a largo plazo para desarrollar herramientas de traducción automática y de idiomas que incluirá a la mayoría de los idiomas del mundo. Se trata de dos proyectos nuevos. El primero es No Language Left Behind (Ningún Idioma Excluido), a través del que estamos desarrollando un nuevo modelo de IA de avanzada que se puede entrenar a partir de idiomas con menos ejemplos de aprendizaje y lo usaremos para obtener traducciones de alta calidad en cientos de lenguas, desde asturiano hasta luganda y urdu. El segundo es Universal Speech Translator (Traductor de Voz Universal), en el que estamos diseñando enfoques innovadores para traducir voz en un idioma a otro en tiempo real, e incluir tanto a los idiomas sin un sistema de escritura estándar, como a los que son escritos y orales.
Tomará mucho más trabajo ofrecer herramientas de traducción realmente universales a cada persona en el mundo. Sin embargo, creemos que las iniciativas que se describen aquí son un avance importante. Compartir los detalles, así como nuestro código y nuestros modelos en el futuro, implica que otros puedan basarse en nuestro trabajo para ayudarnos a alcanzar este importante objetivo.
El desafío de traducir todos los idiomas
Los sistemas de traducción de IA de la actualidad no están diseñados para admitir los miles de idiomas de todo el mundo, ni para proporcionar traducción de voz-a-voz en tiempo real. Para atender a todas las personas, la comunidad de investigación de traducción automática necesitará hacer frente a tres grandes desafíos. Tendremos que superar la escasez de datos al adquirir más datos de entrenamiento en más idiomas y al buscar nuevas maneras de usar los datos que tenemos actualmente. También necesitaremos abordar los desafíos que surjan en la creación de modelos a medida que estos se amplíen para incluir a muchos más idiomas. Y tendremos que buscar nuevos modos de evaluar y mejorar los resultados.
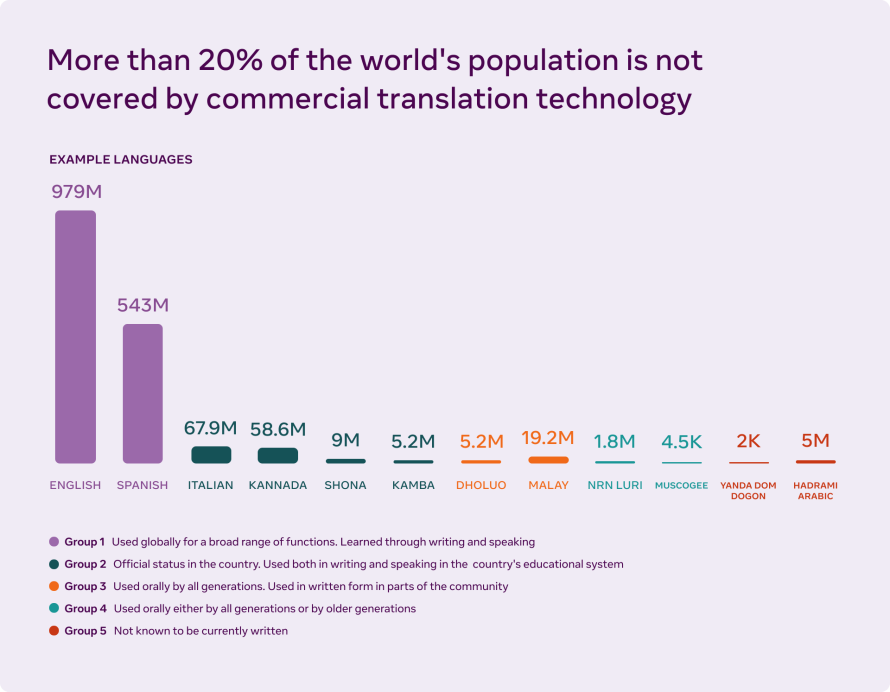
La escasez de datos sigue siendo uno de los mayores obstáculos en la expansión de las herramientas de traducción en más idiomas. Los sistemas de traducción automática para texto generalmente se basan en el aprendizaje de millones de oraciones de datos analizados. Debido a esto, los sistemas de traducción automática con traducciones de alta calidad solo se desarrollaron para algunos idiomas que dominan la web. La expansión a otros idiomas implica buscar maneras de adquirir y usar ejemplos de entrenamiento de idiomas con escasa presencia en internet.
En el caso de la traducción de voz-a-voz directa, el desafío de adquirir datos es incluso más complejo. En la mayoría de los sistemas de traducción de voz automática se usa el texto como paso intermedio, es decir, la voz en un idioma primero se transcribe en texto y, luego, este se traduce al idioma final para generar el audio a través de un sistema de conversión de texto-a-voz. De este modo, las traducciones de voz-a-voz dependen del texto, lo que limita su eficacia y dificulta su implementación en idiomas que son principalmente orales.
Los modelos de traducción de voz-a-voz directa pueden permitir la traducción de idiomas que no tienen sistemas de escritura estandarizados. Este enfoque también podría dar origen a sistemas de traducción más rápidos y eficaces, ya que no requerirán de pasos adicionales para convertir la voz en texto, traducirlo y, luego, generar la voz en el idioma final.
Además, los sistemas de traducción automática actuales requieren de datos de entrenamiento adecuados en miles de idiomas y, simplemente, no están diseñados para satisfacer las necesidades de todas las personas en el mundo. Muchos sistemas de traducción automática son bilingües, es decir, que hay un modelo separado para cada par de idioma, como de inglés a ruso o de japonés a español. Este enfoque es muy difícil de ampliar a decenas de pares de idiomas, menos aún a todos los idiomas que se usan alrededor del mundo. Imagina tener que crear y mantener miles de modelos diferentes para cada combinación, desde de tailandés a lao, hasta de nepalí a asamés. Varios expertos sugirieron que los sistemas multilingües podrían ser útiles en este caso. Sin embargo, resultó increíblemente complicado incorporar muchos idiomas a un solo modelo multilingüe eficaz y de alto rendimiento que pueda representar a todos los idiomas.
Los modelos de traducción automática de voz-a-voz en tiempo real enfrentan muchos de los mismos desafíos que los modelos basados en texto, pero también necesitan superar la latencia (el retraso que ocurre cuando un idioma se traduce a otro) a fin de aplicarlos de manera eficaz para generar traducciones en tiempo real. El principal desafío surge del hecho de que las palabras de una oración pueden decirse en distinto orden en diferentes idiomas. Incluso los intérpretes simultáneos profesionales se retrasan a la voz original en aproximadamente tres segundos. Pensemos en la oración en alemán «Ich möchte alle Sprachen übersetzen» y su equivalente en español «Quisiera traducir todos los idiomas». Sin embargo, traducir de alemán a inglés en tiempo real sería más desafiante porque el verbo «traducir» aparece al final de la oración, mientras que, en español e inglés, el orden de las palabras es similar.
Por último, a medida que incorporemos más y más idiomas, también tendremos que desarrollar nuevas maneras de evaluar el trabajo producido por los modelos de traducción automática. Ya hay recursos para evaluar la calidad de las traducciones de, por ejemplo, inglés a ruso, pero ¿qué ocurre con las traducciones de amhárico a kazajo? A medida que ampliemos el número de idiomas que nuestros modelos de traducción automática puedan traducir, también necesitaremos desarrollar nuevos enfoques para las mediciones y los datos de entrenamiento a fin de abarcar más idiomas. Además de evaluar el rendimiento de los sistemas de traducción automática para determinar la exactitud, también es importante garantizar que las traducciones se realicen con responsabilidad. Deberemos encontrar el modo de garantizar que los sistemas de traducción automática conserven las peculiaridades, y no creen ni intensifiquen sesgos. Como describimos en las secciones a continuación, Meta AI abordará cada uno de estos tres desafíos.
Entrenar sistemas de traducción de voz-a-voz directa y con escasos recursos
Para facilitar las traducciones de idiomas con pocos recursos y para crear la base para futuras traducciones de más idiomas, independientemente de cuánto se escriban o hablen, estamos expandiendo nuestras técnicas de creación automática de conjuntos de datos. Una de esas técnicas es LASER, un kit de herramientas de código abierto que ahora incluye más de 125 idiomas escritos en 28 scripts diferentes.
LASER convierte las oraciones de varios idiomas en una única representación multilingüe. Luego, realizamos una búsqueda de similitud multilingüe a gran escala para identificar las oraciones que tienen una representación similar, es decir, que es probable que tengan el mismo significado en diferentes idiomas. Usamos LASER para crear sistemas como ccMatrix y ccAligned, que pueden encontrar textos paralelos en internet. Como los idiomas con pocos recursos carecen de datos disponibles, creamos un nuevo método de entrenamiento de «maestro a estudiante», mediante el cual LASER se centra en subgrupos de idiomas específicos, como idiomas bantúes, y aprende de conjuntos de datos mucho más pequeños. De este modo, LASER funciona con eficacia a escala en varios idiomas. Cada uno de estos avances nos permitirá cubrir más idiomas a medida que los mejoremos y expandamos para incluir la exploración a cientos de idiomas y, finalmente, a cada idioma con un sistema de escritura. Recientemente ampliamos LASER para trabajar también con voz: al crear representaciones de voz y texto en el mismo espacio multilingüe, podemos extraer traducciones entre voz en un idioma y texto en otro idioma, o, incluso, traducciones de voz-a-voz directas. Con este método, ya identificamos casi 1,400 horas de voz alineada en francés, alemán, español e inglés.
Los datos de texto son importantes, pero no son suficientes para desarrollar herramientas de traducción que satisfagan todas las necesidades. Anteriormente, había datos de referencia de traducción de voz disponibles para unos pocos idiomas, de modo que creamos CoVoST 2, que incluye 22 idiomas y 36 combinaciones de idiomas con diferentes grados de recursos. Además, es difícil encontrar grandes cantidades de audio en diferentes idiomas. VoxPopuli, que contiene 400,000 horas de voz en 23 idiomas, permite el entrenamiento semi-supervisado y auto-supervisado a gran escala para apps de voz, como reconocimiento y traducción de voz. VoxPopuli se usó más tarde para desarrollar el modelo abierto y universal más grande con entrenamiento previo para 128 idiomas y tareas orales, incluida la traducción de voz. Este modelo mejoró el estado anterior del arte de la traducción de voz-a-texto de 21 idiomas a inglés en 7.4 puntos, según la evaluación BLEU, en el conjunto de datos de CoVoST 2.
Desarrollar modelos que funcionen en muchos idiomas y diferentes modalidades
Además de producir más datos para entrenar los sistemas de traducción automática y de ponerlos a disposición para otros investigadores, estamos trabajando para mejorar la capacidad del modelo a fin de lograr traducciones entre un rango mucho más amplio de idiomas. Los sistemas de traducción automática de la actualidad, a menudo, funcionan con una única modalidad entre un conjunto limitado de idiomas. Si el modelo es demasiado acotado para representar muchos idiomas, es posible que su rendimiento disminuya, lo que generaría problemas de exactitud en las traducciones de voz y texto. Las innovaciones en la creación de modelos nos ayudarán a crear un futuro en el que las traducciones avancen rápido y sin contratiempos en diferentes modalidades, desde voz-a-texto, texto-a-voz, texto-a-texto o voz-a-voz, en una gran cantidad de idiomas.
Con el fin de conseguir un mejor rendimiento para nuestros modelos de traducción automática, realizamos una importante inversión para crear modelos de entrenamiento eficaz pese a la gran capacidad, que se centran en modelos de mezcla de expertos con red de agregación escasa. Al incrementar el tamaño del modelo y entrenar una función de ruta automática para que varios tokens usen diferente capacidad experta, pudimos equilibrar el rendimiento de la traducción con muchos y pocos recursos.
Para ampliar la traducción automática basada en texto a 101 idiomas, creamos el primer sistema de traducción de texto multilingüe que no está centrado en idioma inglés. Por lo general, los sistemas bilingües traducen primero del idioma de origen a inglés y, luego, de inglés al idioma final. Para mejorar la calidad y eficacia de estos sistemas, eliminamos el idioma inglés como medio, de modo que los idiomas se puedan traducir directamente a otro idioma sin pasar por el inglés. Si bien, al eliminar el idioma inglés, se mejoró la capacidad del modelo, los modelos multilingües previamente no podían alcanzar el mismo nivel de calidad que los sistemas bilingües personalizados. Sin embargo, recientemente nuestro sistema de traducción multilingüe ganó la competencia Workshop on Machine Translation y superó incluso a los mejores modelos bilingües.
Queremos que nuestra tecnología sea inclusiva: tiene que incluir tanto a los idiomas escritos, como a los que no tienen un sistema de escritura estándar. Con ese objetivo, estamos desarrollando un sistema de traducción de voz-a-voz que no se base en generar una representación textual intermedia durante la inferencia. Se demostró que este enfoque es más rápido que un sistema en cascada tradicional, el cual combina modelos de síntesis de voz, traducción automática y reconocimiento de voz independientes. Con mayor eficacia y una arquitectura más simple, el método de voz-a-voz directa podría permitir una traducción en tiempo real casi de calidad humana en dispositivos futuros, como lentes de AR. Por último, para crear traducciones orales que transmitan la expresividad y el carácter de cada persona, estamos trabajando para incluir algunos aspectos del audio de entrada, como la entonación, en las traducciones de audio generadas.
Medir el éxito en cientos de idiomas
Al desarrollar modelos a gran escala que puedan traducir entre muchos más idiomas, surge una pregunta importante: ¿cómo podemos determinar si desarrollamos mejores datos o mejores modelos? Evaluar el rendimiento de un modelo multilingüe a gran escala es delicado, en especial, porque requiere que tengamos experiencia en el campo en todos los idiomas que abarca el modelo, un desafío que requiere de tiempo, muchos recursos y, a menudo, es poco viable.
Basándose en modelos de traducción multilingües, creamos FLORES-101, el primer conjunto de datos de evaluación de traducción multilingüe que incluye 101 idiomas, y que facilita a los investigadores probar y mejorar rápidamente. A diferencia de los conjuntos de datos existentes, FLORES-101 permite a los investigadores cuantificar el rendimiento de los sistemas entre cualquier combinación de idioma, no sólo la traducción del inglés y a este idioma. En el caso de los millones de personas de todo el mundo que viven en lugares que tienen decenas de idiomas oficiales, este modelo permite crear sistemas de traducción que satisfacen las importantes necesidades del mundo real.
Con FLORES-101, colaboramos con otros líderes de la comunidad de investigación de IA para perfeccionar la traducción multilingüe de idiomas con escasos recursos. En Workshop on Machine Translation de 2021, presentamos una tarea compartida para juntos lograr progresos en esta área. Participaron investigadores de todo el mundo, y muchos se enfocaron en idiomas que eran personalmente relevantes para ellos. Esperamos seguir expandiendo FLORES para incluir a cientos de idiomas.
A medida que conseguimos avances tangibles hacia la traducción universal, también nos centramos en realizar este trabajo con responsabilidad. Estamos trabajando con lingüistas que nos ayudan a entender los desafíos de producir colecciones de conjuntos de datos precisos y con redes de evaluadores que colaboran con nosotros a fin de garantizar que las traducciones sean exactas. También estamos investigando casos prácticos con hablantes de más de 20 idiomas para entender qué características de la traducción son importantes para las personas de diferentes entornos y cómo usarán las traducciones que generarán nuestros modelos de IA. Hay muchos más aspectos en el desarrollo responsable de la traducción universal, como mitigar los sesgos y la interferencia, y conservar las peculiaridades culturales al transmitir la información de un idioma a otro. Alcanzar nuestros objetivos de traducción a largo plazo no solo requerirá de experiencia en IA, sino también del aporte continuo de varios expertos, investigadores y personas de todo el mundo.
¿Cuál es el siguiente paso?
Si los proyectos No Language Left Behind y Universal Speech Translator, combinados con las iniciativas de la comunidad de investigación de traducción automática, crean con éxito tecnologías de traducción que incluyan a cada persona del planeta, los mundos digitales y físicos se abrirán de una manera que antes no era posible. Ya estamos avanzando para facilitar la traducción en idiomas que cuentan con escasos recursos, una barrera importante en la traducción universal para la mayor parte de la población mundial. Esperamos que al progresar en nuestras iniciativas de creación de corpus, modelado multilingüe y evaluación y compartirlas, se sienten las bases para que otros investigadores sigan trabajando y den vida a los usos del mundo real de los sistemas de traducción.
La capacidad de comunicación es uno de los aspectos básicos del ser humano. Desde la imprenta hasta el videochat, las tecnologías han transformado a menudo la forma en que nos comunicamos y compartimos ideas. El poder de estas tecnologías y de otras se ampliará si funcionan de manera equitativa para los miles de millones de personas de todo el mundo, es decir, si les otorga el mismo acceso a la información y les permite comunicarse con un público mucho más amplio, independientemente de los idiomas en los que hablen o escriban. En nuestra iniciativa para lograr un mundo más inclusivo y conectado, es cada vez más importante superar los obstáculos en el camino hacia la información y las oportunidades al empoderar a las personas en sus idiomas de preferencia.