Ranking personalizado con machine learning
Existen muchos mitos y teorías sobre el algoritmo de la Sección de Noticias. La mayoría de las personas saben que existe un algoritmo y muchas de ellas podrán conocer algunos de los factores que proporcionan información a ese algoritmo (si te gusta una publicación o si interactúas con ella, etc.). Sin embargo, se siguen malinterpretando varias cosas.
Compartimos públicamente muchos de los detalles y las características de la Sección de Noticias. Pero no es tan visible el sistema de clasificación del aprendizaje automático que soporta la Sección de Noticias y es increíblemente complejo y tiene muchos niveles. Como parte de nuestro compromiso con la transparencia, compartimos detalles nuevos sobre cómo funciona nuestro sistema de clasificación y los retos de crear un sistema para personalizar contenido para más de 2.000 millones de personas y mostrarle a cada una el contenido que le resulte relevante y significativo cada vez que accede a Facebook.
¿Cuáles son los retos?
Primero, el volumen es enorme. Más de 2.000 millones de personas en todo el mundo usan Facebook. Para cada una de esas personas, hay más de mil publicaciones «candidatas» (o publicaciones que podrían aparecer potencialmente en la Sección de Noticias de esa persona). Estamos hablando de billones de publicaciones entre todas las personas en Facebook.
Hay que considerar que por cada persona en Facebook existen miles de señales que debemos evaluar para determinar qué puede ser más relevante para esa persona. Tenemos billones de publicaciones y miles de señales, y debemos predecir instantáneamente qué es lo que cada una de esas personas quiere ver en su Sección de Noticias. Cuando abres Facebook, ese proceso se realiza en segundo plano, en el segundo que tarda en cargarse la Sección de Noticias.
Una vez que todo esto está en funcionamiento, las cosas cambian y debemos tener en cuenta nuevos retos, como el clickbait y la información errónea. Cuando esto ocurre, debemos encontrar soluciones nuevas. En realidad, el sistema de clasificación no es un algoritmo único. Se trata de múltiples niveles de modelos de aprendizaje automático y clasificaciones que aplicamos con la finalidad de predecir el contenido más relevante y significativo para cada usuario. A medida que avanzamos en cada etapa, el sistema de clasificación reduce esas miles de publicaciones candidatas a unos pocos cientos que aparecen en la Sección de Noticias de una persona en un momento determinado.

¿Cómo lo hacemos?
En pocas palabras, el sistema predice cuál es el contenido que tiene más probabilidades de captar tu atención o interés, y determina qué publicaciones se muestran en tu Sección de Noticias y en qué orden. Estas predicciones se basan en una variedad de factores, incluso qué y a quién sigues o te gusta, o con quién interactuaste recientemente. Para entender cómo funciona esto en la práctica, empecemos por ver qué pasa cuando una persona inicia sesión en Facebook: Lo llamaremos Juan.
Desde que Juan inició sesión ayer, Wei, amigo de Juan, publicó una foto de su cocker spaniel. Otra amiga, Saanvi, publicó un video de su ejercicio de la mañana. Su página favorita publicó un artículo interesante sobre la mejor manera de ver la Vía Láctea por la noche, mientras que su Grupo de cocina favorito publicó cuatro recetas nuevas de pan de masa madre.
Es probable que todo este contenido sea relevante o interesante para Juan porque él eligió seguir a las personas o las Páginas que lo comparten. Para decidir cuál de estas cosas debe aparecer más arriba en la Sección de Noticias de Juan, debemos predecir qué le interesa más y qué contenido tiene el valor más alto para él. En términos matemáticos, debemos definir una función imparcial para Juan y realizar la optimización de un solo objetivo.
Podemos usar las características de una publicación, como a quién se etiquetó en la foto y cuándo se publicó, para predecir si a Juan podría gustarle. Por ejemplo, si Juan suele interactuar con las publicaciones de Saanvi (por ejemplo, las comparte o comenta) y su video de ejercicios es muy reciente, es muy probable que Juan indique que le gusta la publicación. Si Juan interactuó con más contenido de video que con fotos en el pasado, la probabilidad de que indique que le gusta la foto de Wei de su cocker spaniel podría ser bastante baja. En este caso, nuestro algoritmo de clasificación pondría el video de ejercicios de Saanvi más arriba que la foto del perro de Wei porque predice una mayor probabilidad de que Juan indique que le gusta.
Pero las personas no solo expresan sus preferencias con los ‘Me gusta’ en Facebook. Cada día, las personas comparten artículos que encuentran interesantes, miran videos de personas o celebridades que siguen o dejan comentarios amables en las publicaciones de sus amigos. Matemáticamente, las cosas se vuelven más complejas cuando debemos optimizar para múltiples objetivos que se suman a nuestro objetivo principal: crear el valor de más largo plazo para las personas al mostrarles contenido que les resulte significativo y relevante.
Diversos modelos de aprendizaje automático producen múltiples predicciones para Juan: la probabilidad de que interactúe con la foto de Wei, el video de Saanvi, el artículo sobre la Vía Láctea o las recetas del pan de masa madre. Cada modelo intenta clasificar este contenido para Juan. Algunas veces discrepan, y puede haber una mayor probabilidad de que a Juan le guste el video de ejercicio de Saanvi en vez del artículo de la Vía Láctea, pero es más probable que comente el artículo que el video. Entonces, necesitamos una manera de combinar estas distintas predicciones en una puntuación optimizada para nuestro objetivo principal de valor a largo plazo.
¿Cómo podemos medir si algo crea un valor a largo plazo para una persona? Le preguntamos.
Por ejemplo, hacemos encuestas para preguntar a las personas qué tan significativa es para ellas una interacción con sus amigos o si valió la pena ver una publicación. De ese modo, nuestro sistema refleja lo que las personas dicen que disfrutan y encuentran significativo. Así, podemos considerar cada predicción para Juan en función de las acciones que las personas nos indican (a través de las encuestas) que son más significativas y que valen la pena para ellas.
Análisis de los diversos niveles
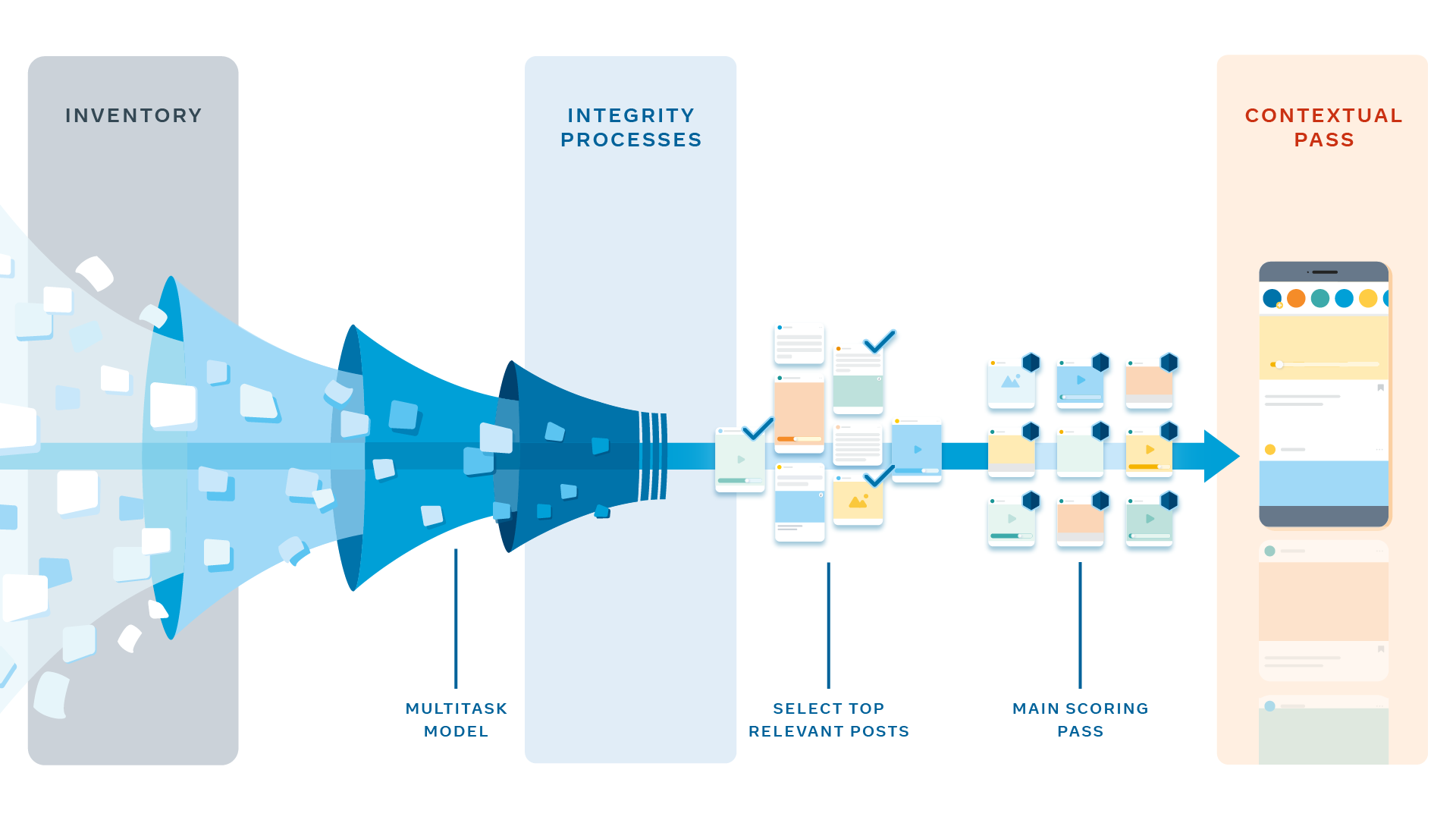
Para clasificar más de mil publicaciones por usuario, por día, para más de 2.000 millones de personas y en tiempo real, debemos llevar a cabo un proceso eficiente. Lo administramos en varios pasos, que están estratégicamente organizados para hacerlo rápidamente y limitar la cantidad de recursos informáticos requeridos.
Primero, el sistema recopila todas las publicaciones candidatas que posiblemente podemos clasificar para Juan (la foto del cocker spaniel, el video de ejercicios, etc.). Este inventario elegible incluye cualquier publicación compartida con Juan por parte de un amigo, un Grupo o una Página con los que esté conectado, y que se haya realizado desde su último inicio de sesión y no se haya eliminado. Pero ¿cómo debemos tratar las publicaciones que Juan todavía no vio y que se crearon antes de su último inicio de sesión?
Para asegurarnos de reconsiderar las publicaciones no vistas, aplicamos una lógica de incrementos no leídos: Las publicaciones nuevas que se clasificaron para Juan (pero que no vio) en sus sesiones anteriores también se agregan al inventario elegible para esta sesión. También aplicamos una lógica de incrementos de acción, de modo que todas las publicaciones que Juan ya vio que hayan generado conversaciones interesantes entre sus amigos también se agregan al inventario elegible.
Luego, el sistema debe asignar una puntuación a cada publicación para una variedad de factores, como el tipo de publicación, la similitud con otros elementos y la medida en que la publicación coincide con el contenido con el que Juan suele interactuar. Para calcular esto para más de mil publicaciones, por cada mil millones de usuarios, todo en tiempo real, ejecutamos estos modelos para todas las historias candidatas en paralelo en diversos equipos, llamados predictores.
Antes de combinar todas estas predicciones en una sola puntuación, debemos aplicar algunas reglas adicionales. Esperamos hasta tener estas primeras predicciones para poder acotar el grupo de publicaciones que debemos clasificar y les aplicamos diversas aprobaciones para ahorrar energía computacional.
Primero, se aplican determinados procesos automatizados a cada publicación. Están diseñados para determinar qué medidas de detección de contenido, si las hay, se deben aplicar a las historias seleccionadas para la clasificación. En la siguiente fase de aprobación, un modelo sencillo acota el grupo de publicaciones candidatas a aproximadamente 500 de las más relevantes para Juan. Clasificar menos historias nos permite usar modelos de redes neuronales más potentes para las siguientes fases de aprobación.
Luego, aplicamos la aprobación de puntuación principal, donde ocurre la mayor parte de la personalización. Aquí, se calcula una puntuación para cada historia de forma independiente y, luego, las 500 publicaciones se ordenan según la puntuación. Para algunas personas, podría tener más sentido calcular un valor más alto para los ‘Me gusta’ que para los comentarios, ya que prefieren expresarse de esa forma. Cualquier acción con la que una persona no suela interactuar (por ejemplo, una predicción de ‘Me gusta’ muy cercana a 0) obtiene automáticamente un rol mínimo en la clasificación, ya que el valor previsto es muy bajo.
Por último, ejecutamos aprobaciones contextuales en las que se agregan las funciones contextuales, como las reglas de diversidad del tipo de contenido, para asegurarnos de que la Sección de Noticias de Juan tenga una buena combinación de tipos de contenido y que no vea distintas publicaciones con video una detrás de la otra. Todos estos pasos de clasificación ocurren en el tiempo que tarda Juan en abrir la app de Facebook y, en cuestión de segundos, puede disfrutar de una Sección de Noticias clasificada y explorarla.