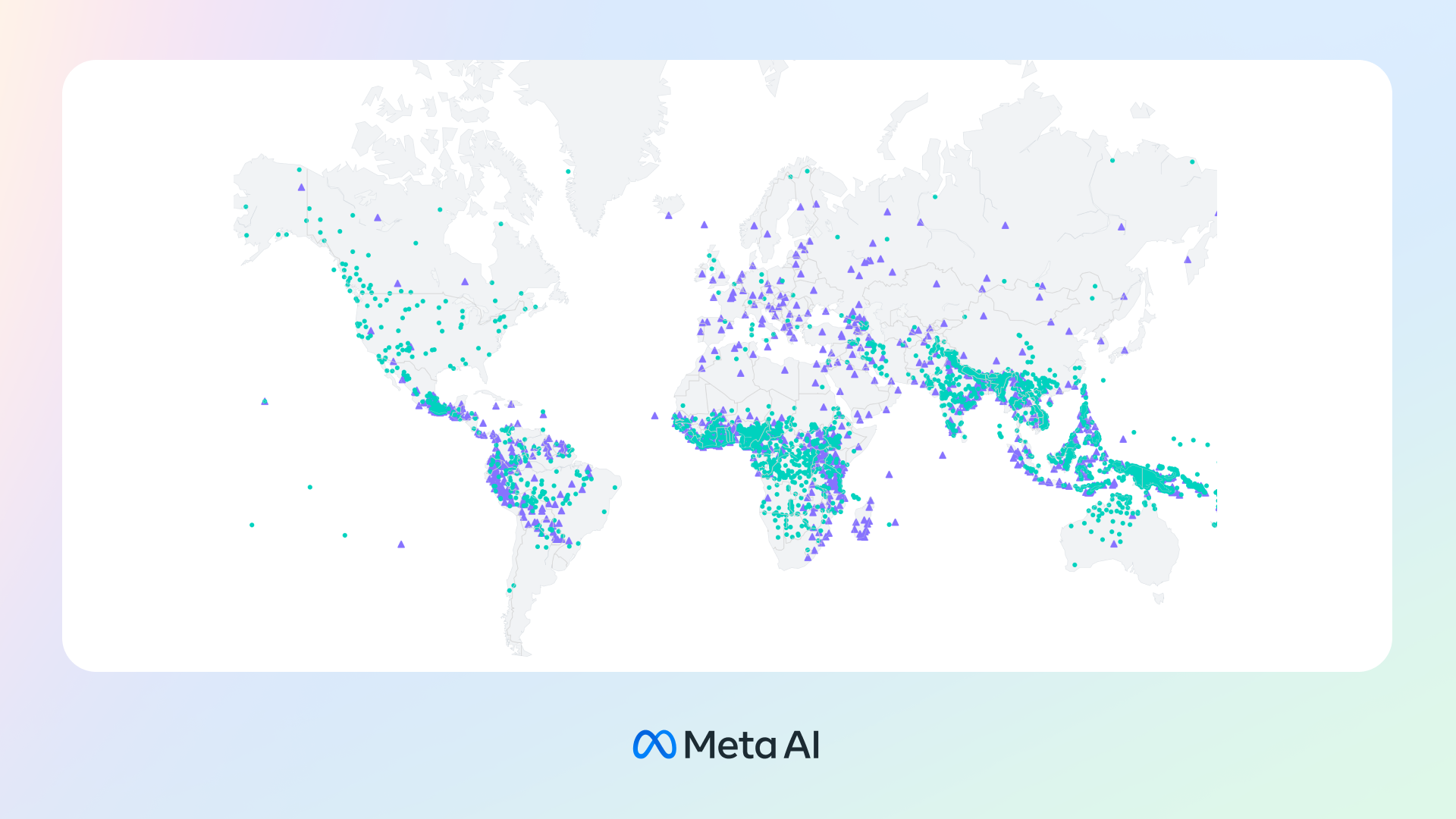
Ampliamos la tecnología de reconocimiento de voz de alrededor de 100 idiomas a más de 1.000, mediante la creación de un único modelo de reconocimiento de voz multilingüe compatible con más de 1.100 idiomas (10 veces más que los modelos actuales), con modelos de identificación de idiomas capaces de identificar 4.000 idiomas (40 veces más que los modelos actuales), con modelos preentrenados compatibles con 1.400 idiomas y modelos de texto a voz para más de 1.100 idiomas. Nuestro objetivo es facilitar a las personas el acceso a la información y el uso de dispositivos en su idioma preferido.
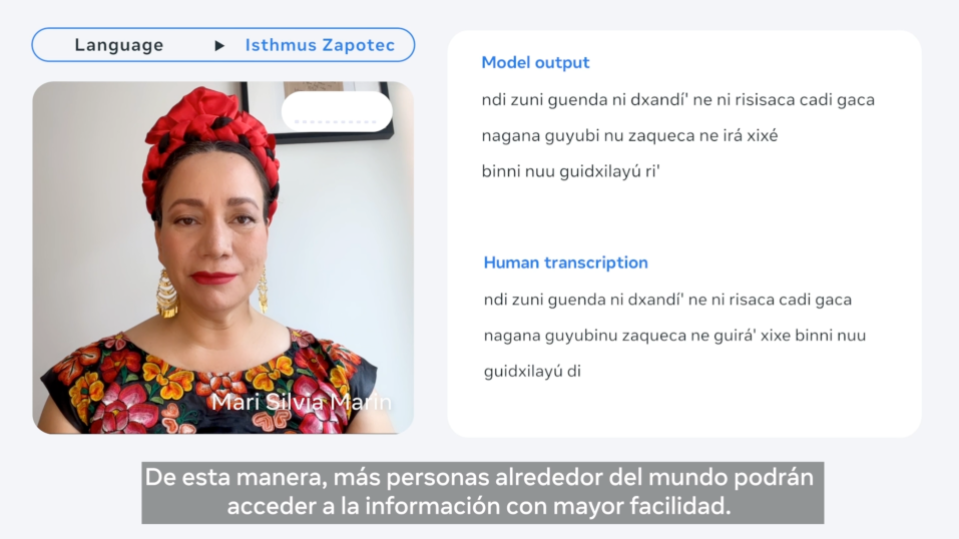
Demostración de nuestros modelos de voz a texto para algunos de los más de 1.100 idiomas que cubiertos.
Equipar sistemas con la capacidad de comprender y producir voces puede permitir que muchas más personas accedan a la información, incluidas aquellas que dependen totalmente de la voz para hacerlo. Sin embargo, crear modelos de aprendizaje automático de buena calidad para estas tareas requiere grandes cantidades de datos etiquetados: en este caso, miles de horas de audio, además de transcripciones. Estos datos son inexistentes para la mayoría de los idiomas. Por ejemplo, los modelos de reconocimiento de voz actuales solo abarcan aproximadamente 100 idiomas, una fracción de los más de 7.000 idiomas que se hablan en todo el mundo. Y lo que es más preocupante, casi la mitad de estos idiomas corren el riesgo de desaparecer durante nuestra vida.
En el proyecto Massively Multilingual Speech (MMS, por sus siglas en inglés), superamos algunos de estos desafíos combinando wav2vec 2.0, nuestro trabajo precursor en aprendizaje autosupervisado, y un nuevo conjunto de datos que proporciona datos etiquetados para más de 1.100 idiomas y datos sin etiquetar para casi 4.000 idiomas. Algunos de ellos, como el idioma tatuyo, tienen apenas unos cientos de hablantes y no existe una tecnología del habla para la mayoría de estos idiomas. Nuestros resultados demuestran que MMS se desempeña bien en comparación con los modelos actuales y cubren 10 veces más idiomas. Meta se centra en el multilingüismo en general: en cuanto al texto, el proyecto NLLB amplió la traducción multilingüe a 200 idiomas, y el proyecto MMS amplía la tecnología de voz a muchos más idiomas.
Hoy, compartimos con el público nuestros modelos y códigos para que otros investigadores puedan utilizarlos como referencia. Con este trabajo, esperamos hacer una pequeña contribución para preservar la increíble diversidad lingüística del mundo.
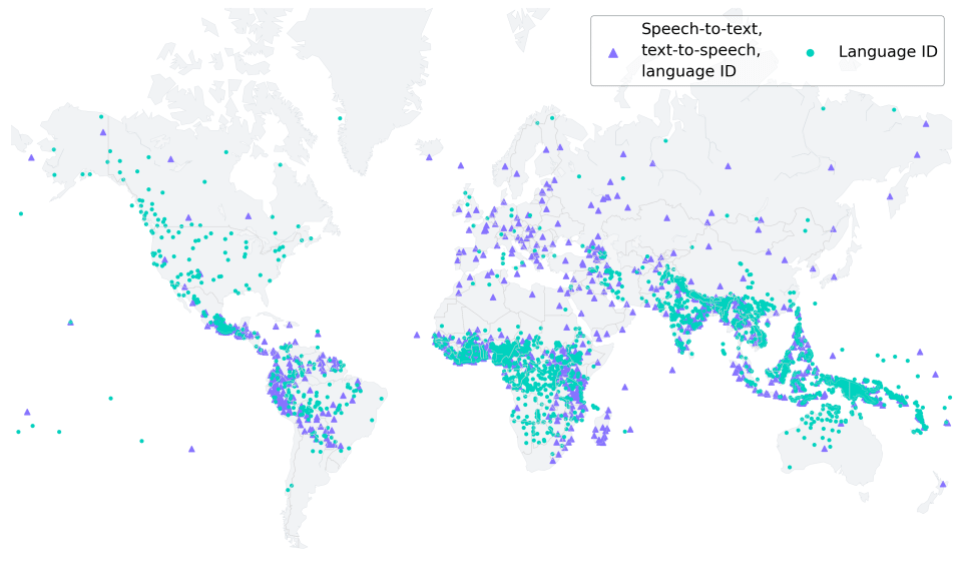
Ilustración de los idiomas cubiertos por el modelo de reconocimiento Massively Multilingual Speech (MMS). MMS habilita conversión de voz a texto y de texto a voz para 1.107 idiomas e identificación de idioma para más de 4.000 idiomas.
Nuestro enfoque
Recopilar datos de audio de miles de idiomas fue nuestro primer desafío, ya que los mayores conjuntos de datos de voz actuales abarcan, como mucho, 100 idiomas. Para superarlo, recurrimos a textos religiosos, como la Biblia, que se tradujeron a muchos idiomas distintos y cuyas traducciones se estudiaron en profundidad para investigar la traducción de textos lingüísticos. Estas traducciones cuentan con grabaciones de audio, a disposición del público, de personas leyendo estos textos en diferentes idiomas. Como parte de este proyecto, creamos un conjunto de datos de lecturas del Nuevo Testamento en más de 1.100 idiomas, lo que proporcionó un promedio de 32 horas de datos por idioma.
Mediante las grabaciones no etiquetadas de otras lecturas religiosas cristianas, aumentamos el número de idiomas disponibles a más de 4.000. Aunque estos datos provienen de un ámbito específico y los suelen leer hablantes masculinos, nuestro análisis demuestra que nuestros modelos funcionan con la misma eficacia tanto para voces masculinas como femeninas. Y, si bien el contenido de las grabaciones de audio es religioso, nuestro análisis muestra que esto no sesga el modelo para producir un lenguaje más religioso. Creemos que esto se debe a que utilizamos un enfoque de clasificación temporal conexionista (CTC), que está mucho más restringido en comparación con los modelos de lenguaje grandes (LLM, por sus siglas en inglés) o los modelos secuencia a secuencia de reconocimiento de voz.
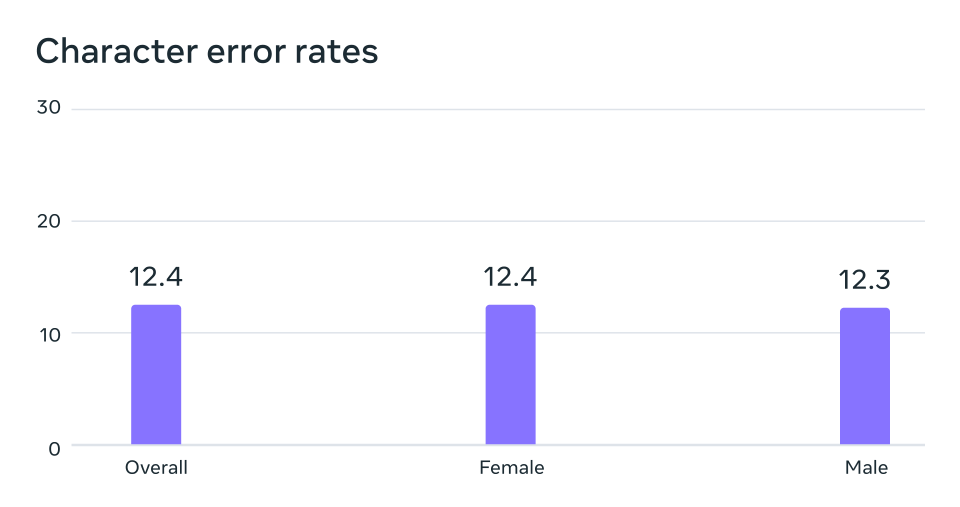
Análisis de posibles sesgos de género. Los modelos de reconocimiento de voz automático entrenados con datos de MMS tienen una tasa de error similar para hablantes masculinos y femeninos en el punto de referencia FLEURS.
Procesamos los datos para mejorar su calidad y hacerlos útiles para nuestros algoritmos de aprendizaje automático. Para ello, entrenamos un modelo de alineación con datos existentes en más de 100 idiomas y lo utilizamos junto con un eficiente algoritmo de alineación forzada que puede procesar grabaciones extensas de alrededor de 20 minutos o más. Aplicamos varias rondas de este proceso y realizamos un último paso de filtrado de validación cruzada basado en la precisión del modelo para eliminar los datos que podían estar desalineados. Para que otros investigadores puedan crear nuevos conjuntos de datos de voz, agregamos el algoritmo de alineación a PyTorch y publicamos el modelo de alineación.
Treinta y dos horas de datos por idioma no son suficientes para entrenar modelos convencionales de reconocimiento de voz supervisados. Por eso, nos basamos en wav2vec 2.0, nuestro trabajo anterior sobre el aprendizaje autosupervisado de la representación de voz, que redujo en gran medida la cantidad de datos etiquetados necesarios para entrenar buenos sistemas. Concretamente, entrenamos modelos autosupervisados con unas 500.000 horas de datos de voz en más de 1.400 idiomas, es decir, casi el triple de idiomas que cualquier trabajo previo publicado. Luego, los modelos obtenidos se perfeccionaron para una tarea específica de voz, como el reconocimiento de voz multilingüe o la identificación de idiomas.
Resultados
Para comprender mejor el rendimiento de los modelos entrenados con los datos de MMS, los evaluamos en bases de datos de referencia ya existentes, como FLEURS.
Entrenamos modelos de reconocimiento de voz multilingües en más de 1.100 idiomas mediante un modelo wav2vec 2.0 con 1.000 millones de parámetros. A medida que aumenta el número de idiomas, el rendimiento disminuye, pero muy poco: al pasar de 61 a 1.107 idiomas, el porcentaje de errores de caracteres aumenta solo en un 0,4%, pero la cobertura lingüística aumenta más de 17 veces.
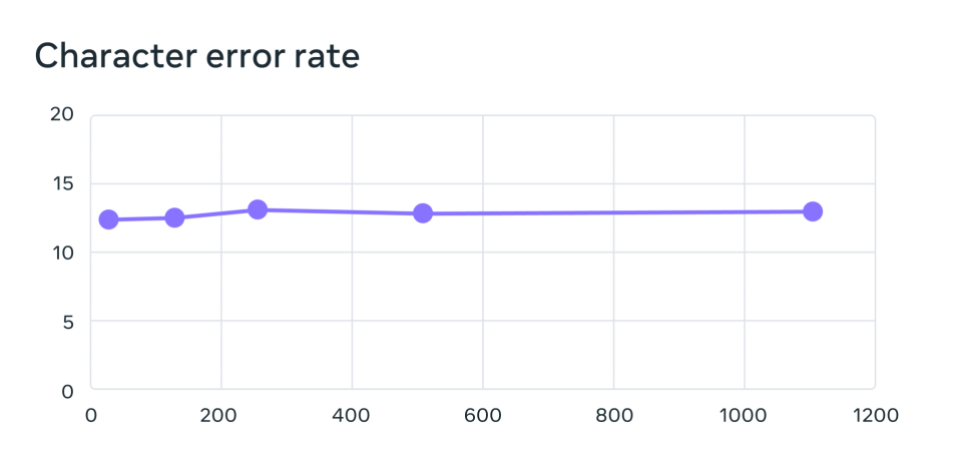
Tasa de error en 61 idiomas FLEURS para sistemas de reconocimiento de voz multilingües entrenados en MMS al aumentar la cantidad de idiomas admitidos por cada sistema de 61 a 1.107. Las tasas de error más altas indican un rendimiento más bajo.
En una comparación equivalente con Whisper de OpenAI, descubrimos que los modelos entrenados con los datos del proyecto MMS, reducen a la mitad el porcentaje de errores de palabras, pero MMS abarca 11 veces más idiomas. Esto demuestra que nuestro modelo puede funcionar muy bien en comparación con los mejores modelos de voz actuales.
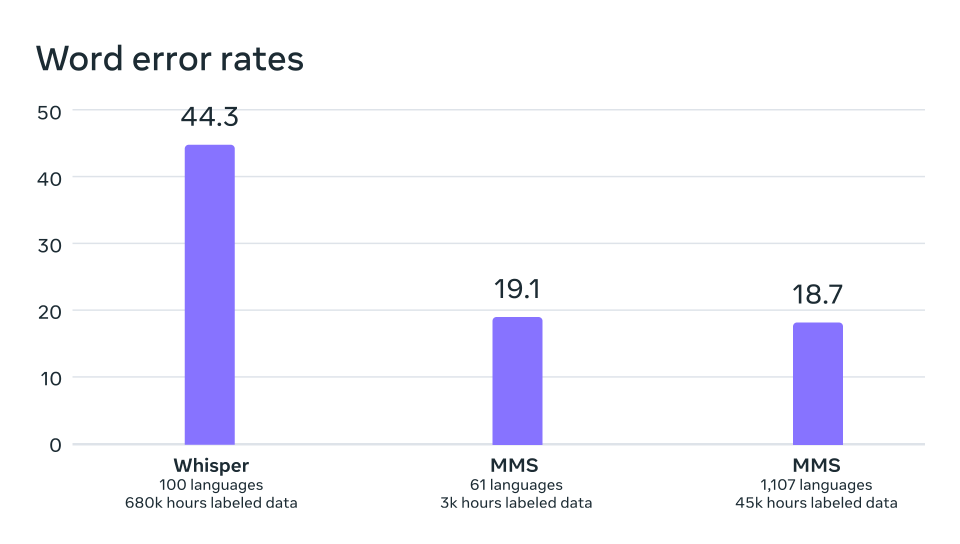
Tasa de error de palabras de OpenAI Whisper en comparación con Massively Multilingual Speech en los 54 idiomas de FLEURS que permiten una comparación directa.
Posteriormente, entrenamos un modelo de identificación de idiomas (LID) para más de 4.000 idiomas a partir de nuestros conjuntos de datos y de otros ya existentes, como FLEURS y CommonVoice, y lo evaluamos en la tarea LID de FLEURS. El resultado es que, si se cubren 40 veces más idiomas, el rendimiento sigue siendo muy bueno.
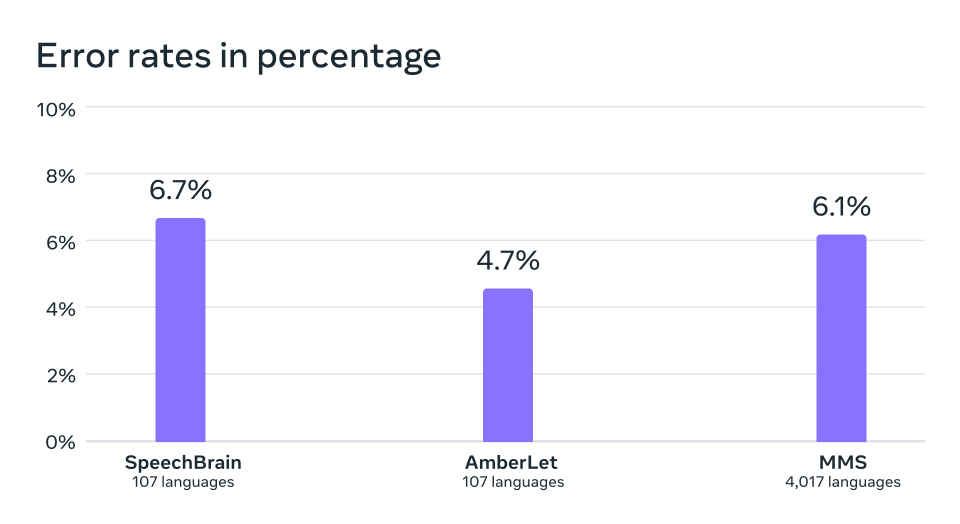
Precisión de identificación de idioma en el punto de referencia VoxLingua-107 del trabajo existente, que admite poco más de 100 idiomas, y MMS, que admite más de 4.000 idiomas.
También creamos sistemas de conversión de texto a voz para más de 1.100 idiomas. Los modelos actuales de conversión de texto en voz suelen entrenarse con corpus de voz que contienen un único hablante. Una limitante de los datos de MMS es que contienen relativamente pocos hablantes distintos para muchos idiomas y, en ocasiones, solo un hablante. Sin embargo, esto es una ventaja al construir sistemas de conversión de texto a voz, por lo que entrenamos dichos sistemas para más de 1.100 idiomas. Comprobamos que la calidad de las voces producidas por estos sistemas es buena, como demuestran los ejemplos siguientes.
Nuestros resultados nos motivan pero, como ocurre con todas las nuevas tecnologías de inteligencia artificial (IA), estos modelos no son perfectos. Por ejemplo, existe cierto riesgo de que el modelo de voz a texto transcriba mal determinadas palabras o frases. En función de los resultados, esto podría generar un lenguaje ofensivo o inexacto. Creemos que la colaboración a lo largo de la comunidad de IA es fundamental para el desarrollo responsable de tecnologías impulsadas por inteligencia artificial.
Hacia un modelo único de voz compatible con miles de idiomas
Muchos idiomas del mundo están en peligro de desaparecer y las limitaciones de las tecnologías actuales de reconocimiento y generación de voz solo acelerarán esta tendencia. Nuestra visión es un mundo en el que la tecnología tenga el efecto contrario, que anime a las personas a preservar sus idiomas a raíz de poder acceder a la información y utilizar la tecnología en su idioma de preferencia.
El proyecto MMS representa un importante avance hacia esa meta. En el futuro, queremos aumentar aún más la cantidad de idiomas y afrontar el desafío de los dialectos, que suele ser difícil para la tecnología de voz actual. Nuestro objetivo es facilitar a las personas el acceso a la información y el uso de los dispositivos en su idioma de preferencia. También hay muchos casos de uso concretos de la tecnología de voz, como la tecnología de VR/AR (que puede utilizarse en el idioma que prefiera la persona) o los servicios de mensajes que pueden entender la voz de cualquier persona.
Además, vislumbramos un futuro en el que un solo modelo pueda resolver varias tareas de voz en todos los idiomas. Aunque entrenamos modelos distintos de reconocimiento de voz, síntesis de voz e identificación de idiomas, creemos que, en el futuro, un único modelo podrá realizar todas estas tareas y muchas más, lo que permitirá mejorar el rendimiento general.