Cuando las personas en Facebook navegan por su Feed de noticias, encuentran todo tipo de contenidos —artículos, comentarios de amigos, invitaciones a eventos y, por supuesto, fotos. La mayoría de las personas pueden ver instantáneamente lo que hay en estas imágenes, ya sea su nuevo nieto, un bote en un río o la imagen borrosa de una banda en el escenario. Muchos usuarios ciegos y con discapacidad visual también pueden experimentar esas imágenes, siempre y cuando estén etiquetadas correctamente con texto alternativo (o “alt text”). Un lector de pantalla puede describir el contenido de estas imágenes utilizando una voz sintética, y permitir que las personas con discapacidad visual comprendan las imágenes en su Feed de Facebook.
Desafortunadamente, muchas fotos se publican sin texto alternativo, por lo que en 2016 presentamos una nueva tecnología llamada Texto Alternativo Automático (AAT por sus siglas en inglés). AAT — que fue reconocido en 2018 con el premio Helen Keller Achievement Award de la American Foundation for the Blind — utiliza el reconocimiento de objetos para generar descripciones de fotos a pedido para que las personas ciegas o con discapacidad visual puedan disfrutar más plenamente de su Feed de noticias. Desde entonces, lo hemos estado mejorando y estamos contentos de presentar la próxima generación de AAT.
La evolución de ATT representa múltiples avances tecnológicos que mejoran la experiencia fotográfica de nuestros usuarios. En primer lugar, ampliamos más de 10 veces la cantidad de objetos que AAT puede detectar e identificar de manera confiable en una foto, lo que a su vez significa menos fotos sin descripción. Además, las descripciones son más detalladas, con la capacidad de identificar actividades, puntos de referencia, tipos de animales, y mucho más — como “Puede ser una selfie de 2 personas, al aire libre, en la Torre de Pisa”.
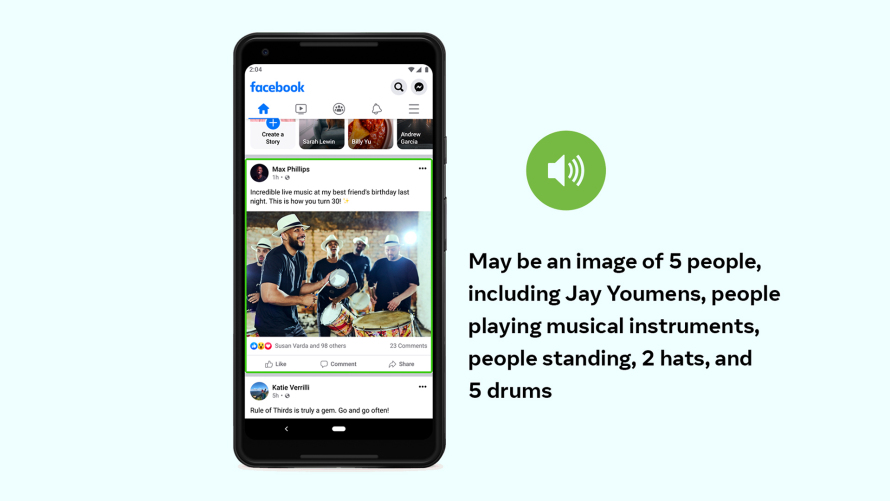
Somos la primera empresa de la industria que será capaz de incluir información sobre la ubicación posicional y el tamaño relativo de los elementos en una foto. En lugar de describir el contenido de una foto como “Puede ser una imagen de 5 personas”, podemos especificar que hay dos personas en el centro de la foto y otras tres hacia los márgenes, lo que implica que las dos en el centro son el foco. O en lugar de simplemente describir un paisaje encantador como “Puede ser una casa y una montaña”, podemos resaltar que la montaña es el objeto principal en una escena según lo grande que parece en comparación con la casa en su base.
En conjunto, estos avances ayudan a los usuarios con discapacidad visual a comprender mejor el contenido de las fotos publicadas por familiares y amigos — y sus propias fotos — al proporcionar más información, más detallada.
Dónde empezamos
El concepto de “texto alternativo” se remonta a los primeros días de Internet, cuando era una alternativa de texto a la descarga de imágenes para conexiones lentas. Por supuesto, el texto alternativo también ayudó a las personas con discapacidad visual a navegar por Internet, ya que el software de lectura de pantalla puede usarse para generar descripciones de imágenes en audio. Desafortunadamente, las rápidas velocidades de Internet hicieron que el texto alternativo deje de ser una prioridad para varios usuarios. Y dado que estas descripciones debían ser agregadas manualmente por quien cargaba la imagen, muchas fotos dejaron de incluir el texto alternativo, dejando sin el recurso a las personas que utilizaban la herramienta.
Hace casi cinco años aprovechamos la experiencia en visión computacional de Facebook para ayudar a resolver este problema. La primera versión de AAT se desarrolló utilizando datos etiquetados por humanos, con los que entrenamos una red neuronal convolucional profunda utilizando millones de ejemplos de forma supervisada. Nuestro modelo completo de AAT pudo reconocer 100 conceptos comunes, como “árbol”, “montaña” y “al aire libre”. Y dado que los usuarios de Facebook a menudo comparten fotos de amigos y familiares, nuestras descripciones de AAT utilizaron modelos de reconocimiento facial que identificaron a las personas (siempre que esas personas dieran su consentimiento explícito). Para los usuarios con discapacidad visual, este fue un gran paso.
Ver más del mundo
Pero sabíamos que el AAT podía hacer más, y el siguiente paso lógico era ampliar el número de objetos reconocibles y perfeccionar la forma en que eran descritos.
Para lograr esto, nos alejamos del aprendizaje completamente supervisado con datos etiquetados por humanos. Si bien este método ofrece precisión, el tiempo y esfuerzo involucrados en el etiquetado de datos es extremadamente alto — y por eso nuestro modelo AAT original sólo reconoció 100 objetos de manera confiable. Como ese enfoque no era escalable, necesitábamos un nuevo camino para seguir.
Para la última versión de AAT, aprovechamos un modelo entrenado con datos supervisados parcialmente, utilizando miles de millones de imágenes públicas de Instagram y sus hashtags. Para que nuestros modelos funcionen mejor para todos, los ajustamos para que los datos fueran muestreados a partir de imágenes en todas las geografías, y utilizando traducciones de hashtags en muchos idiomas. También evaluamos nuestros conceptos en los ejes de género, tono de piel y edad. Los modelos resultantes son más precisos e inclusivos a nivel cultural y demográfico — por ejemplo, pueden identificar casamientos en todo el mundo basándose (en parte) en atuendos tradicionales en lugar de etiquetar solo fotos con vestidos de novia blancos.
También nos brindó la capacidad de reutilizar más fácilmente los modelos de aprendizaje automático como punto de partida para la capacitación en nuevas tareas — un proceso conocido como aprendizaje por transferencia. Esto nos permitió crear modelos que identifican conceptos como monumentos nacionales, tipos de alimentos (como arroz frito y papas fritas) y selfies. Todo este proceso no hubiera sido posible en el pasado.
Para obtener información más rica, como posición y recuento en la imagen, también entrenamos a un detector de objetos de dos etapas, Faster R-CNN, utilizando Detectron2, una plataforma de código abierto para la detección y segmentación de objetos desarrollada por Facebook AI Research. Entrenamos los modelos para predecir ubicaciones y etiquetas semánticas de los objetos dentro de una imagen. Las técnicas de entrenamiento de múltiples etiquetas y conjuntos de datos ayudaron a que nuestro modelo fuera más confiable con más espacio para etiquetas.
El AAT mejorado reconoce de manera confiable más de 1200 conceptos — 10 veces más que la versión original que lanzamos en 2016. Cuando consultamos con los usuarios de lectores de pantalla sobre AAT y la mejor manera de perfeccionarlo, dejaron en claro que la precisión es primordial. Con ese fin, solo hemos incluido conceptos en los que podríamos garantizar modelos bien entrenados que cumplieran con un cierto umbral de precisión. Si bien existe un margen de error, razón por la cual comenzamos cada descripción con «Puede ser», elevado el umbral de precisión y omitimos intencionalmente conceptos que no pudimos identificar de manera confiable.
Queremos brindarles a nuestros usuarios con discapacidad visual y ciegos tanta información como sea posible sobre el contenido de una foto, y asegurar que sea información correcta.
Brindar detalles
Habiendo aumentado el número de objetos reconocidos con un alto nivel de precisión, centramos nuestra atención en descubrir cómo describir mejor lo que encontramos en una foto.
Le preguntamos a los usuarios que dependen de los lectores de pantalla cuánta información querían escuchar y cuándo querían escucharla. Querían más información cuando una imagen es de amigos o familiares, y menos cuando no lo es. Diseñamos el nuevo AAT para proporcionar una descripción precisa de todas las fotos de forma predeterminada, pero ofrecemos una manera fácil de solicitar detalles mejorados sobre las fotos de interés.
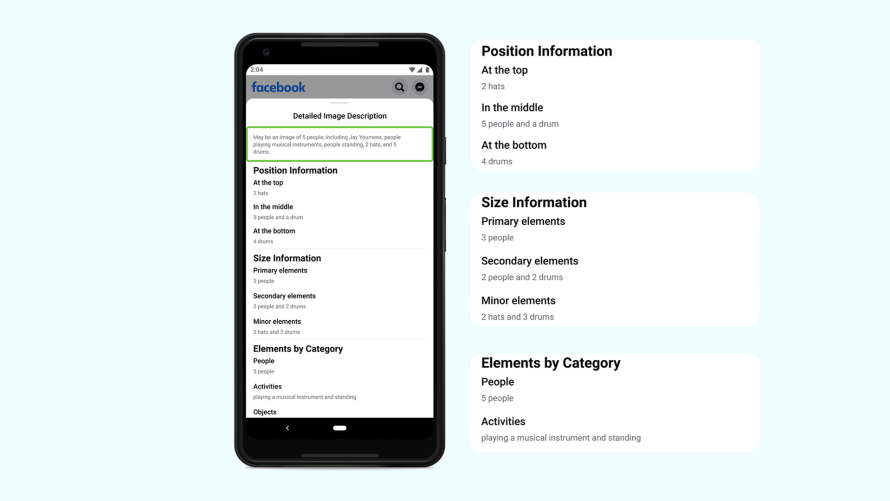
Cuando los usuarios seleccionan esta última opción, se presenta un panel que proporciona una descripción más completa del contenido de una foto, incluido un recuento de los elementos de la foto, algunos de los cuales pueden no haber sido mencionados en la descripción predeterminada. Las descripciones detalladas también incluyen información posicional simple — superior/medio/inferior o izquierda/centro/derecha de una imagen — y una comparación de la prominencia relativa de los objetos, descritos como “primarios”, “secundarios” o “menores” en la imagen. Estas palabras fueron elegidas específicamente para minimizar la ambigüedad. Feedbacks durante el desarrollo de la herramienta mostraron que usar una palabra como “grande” para describir un objeto podría resultar confuso porque no está claro si la referencia es a su tamaño real o su tamaño en relación con otros objetos en una imagen. ¡Incluso un chihuahua se ve grande si se saca una fotografía de cerca!
El AAT usa una redacción simple para brindar descripciones precisas predeterminadas, en lugar de una oración larga. No es poético, pero es muy funcional. Nuestros usuarios pueden obtener la descripción rápidamente — y nos permite traducir fácil y rápidamente nuestras descripciones de texto alternativo a 45 idiomas diferentes, incluso a español, lo que garantiza que AAT sea útil para personas de todo el mundo.
Facebook es para todos
Todos los días, nuestros usuarios comparten miles de millones de fotos. La ubicuidad de cámaras económicas en los teléfonos móviles, las conexiones inalámbricas rápidas y los productos de redes sociales como Instagram y Facebook han facilitado la captura y el intercambio de fotografías, una de las formas más populares de comunicarse — incluso para las personas con discapacidad visual. Si bien deseamos que todos los que hayan subido una foto incluyan una descripción de texto alternativo, reconocemos que esto no suele suceder. Creamos AAT para cerrar esta brecha, y el impacto que ha tenido en quienes lo necesitan es inconmensurable. La inteligencia artificial promete avances extraordinarios, y nos entusiasma la oportunidad de llevar estos avances a las comunidades que los necesitan.