
- Metaは、より安全で、より楽しい体験を人々に提供するため、リリース前にAIの機能やモデルに安全措置を組み込んでいます。
- すべての生成AIシステムと同様に、AIモデルは不正確または不適切な出力を返すことがあります。私たちは、テクノロジーの進化と、より多くの人から寄せられるフィードバックに基づき、これからも機能の改善に取り組んでいきます。
- Metaは、政府機関、他の企業、学界および市民社会におけるAI専門家、支援者、プライバシーの専門家や擁護者などと協力して、責任ある安全対策を講じていきます。
- こうした取り組みの一環として本日、「Llama 2の責任ある使用のためのガイド」の日本語版を公開します。
Metaは、10年以上にわたりAIのパイオニアであり続け、1,000 を超えるAIモデル、ライブラリ、データセットを研究者向けにリリースしてきました。その中には、マイクロソフト社との協力によって実現した、最新バージョンの大規模言語モデル「Llama 2」も含まれています。
Connect 2023では、Metaのプラットフォーム上における体験をよりソーシャルで没入感のあるものにする、新しい生成AI機能を発表しました。私たちは、このような生成AIツールがさまざまな点で人々の助けとなることを願っています。友人同士で旅行の計画を立てることを想像してみてください。グループチャットでAIアシスタントにお勧めのレジャーやレストランを尋ねることができます。また、教師であれば、それぞれの生徒の学習スタイルに合わせた個別の授業計画を立てるのにAIを活用できるかもしれません。
こうしたテクノロジーの構築には、ベストプラクティスや方針を確立していく責任が伴います。生成AIの用途には、面白く、創造的なものがたくさんありますが、それは常に完璧というわけではありません。たとえば、基盤となっているモデルは、架空の回答を生成したり、学習データから学んだステレオタイプを過剰に反映したりすることがあります。Metaは、この10年間で学んだ教訓を新しい機能に組み込んでいます。生成AIの限界を理解してもらうための注意書きや、危険な回答の検知と除外に役立つ完全性区分などはその一例です。こうした対策は、Llama 2の責任ある使用のためのガイドに概説されている業界のベストプラクティスに従って行われています。
Metaは、責任あるAIへの取り組みに基づき、安全性を向上させるために製品のストレステストを実施しています。また、政策担当者、学界や市民社会の専門家、そして業界関係者らとも協力を重ねながら、このテクノロジーの責任ある使用を推進しています。テクノロジーの進化と、人々の日常生活におけるテクノロジーの使用方法に合わせて、今後もこうした機能の改善を継続的に行っていきます。
責任ある構築と人々の安全の優先
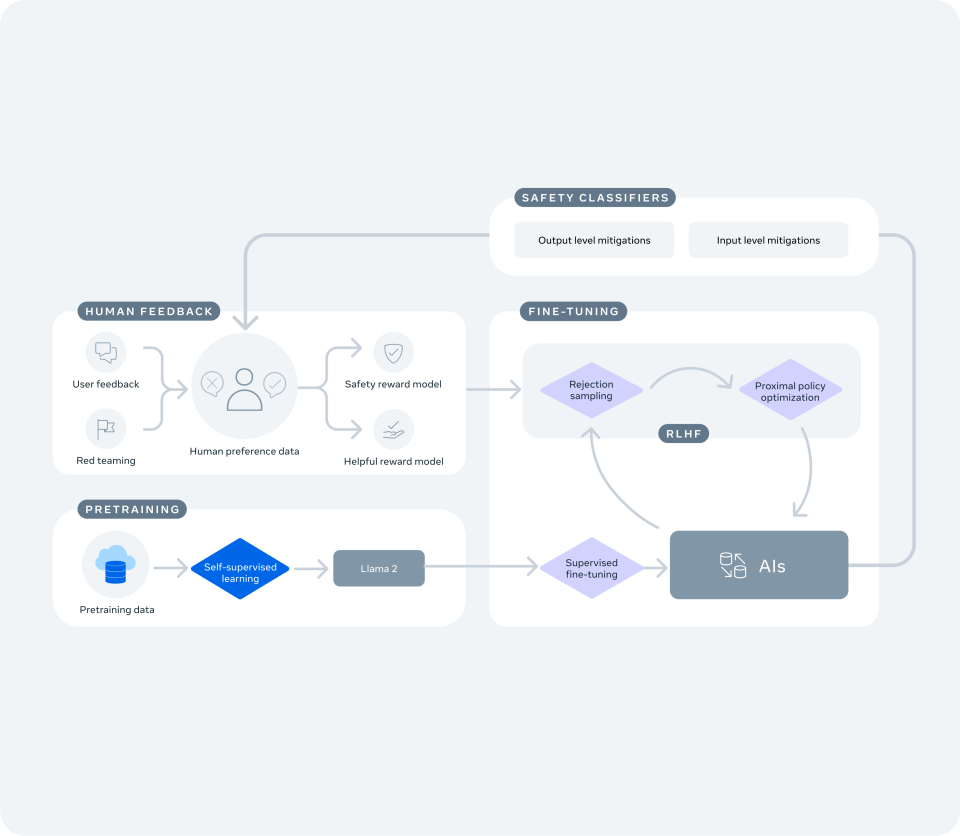
大規模言語モデルを活用した「Meta AI」など、新しいテキストベースの体験を支えるカスタムAIモデルはLlama 2を基盤として構築されているため、Llama 2の安全性と責任に関する学習を活用しています。それに加えて、私たちは、Connect 2023で発表した機能に関する具体的な対策にも注力してきました。
潜在的な脆弱性の検出、リスクの低減、安全性と信頼性の向上のために私たちが実施している手順については、公開資料(英文のみ)で詳しく説明しています。以下に例を挙げます。
- レッドチーム演習を通じて内外の専門家とともに会話型AIを評価し、改善しています:専任の専門家チームが数千時間をかけてこれらのモデルにストレステストを実施し、想定外の方法で使用されることがないかを確認して脆弱性の検出と修正に取り組んでいます。
- モデルをファインチューニングしています:これには、有用な回答を提供する確率を高める指示を使用し、高画質の画像の生成など、特定のタスクを実行するモデルのトレーニングが含まれます。また、安全性の課題に対しては、専門家の裏付けに基づいたリソースを提供するようにモデルをトレーニングしています。たとえば、特定の質問に対しては、AIは地元の自殺予防や摂食障害対策の支援団体を紹介し、医療的なアドバイスは提供できないことを明示します。
- 安全と責任のガイドラインに沿ってモデルをトレーニングしています:モデルにガイドラインを学習させることにより、どの年齢の人がアプリを使用していても、有害または不適切となり得る回答が提供される可能性が少なくなります。
- 偏見を減らす対策を講じています:生成AIシステム内の潜在的な偏見への対応は、新たな研究分野の1つとなっています。他のAIモデルと同様、より多くの人に機能を使用してもらいフィードバックを得ることが、私たちのアプローチを改善する助けとなります。
- ポリシーに反するコンテンツを検出して措置を講じる新しい技術を開発しました:私たちのチームは、有害な回答が利用者に提供される前にそれらをスキャンし、除外するアルゴリズムを構築しました。
- 機能内にフィードバックツールを組み込んでいます:完璧なAIモデルはありません。頂いたフィードバックに基づき、安全性能とポリシー違反の自動検知の向上のためにモデルをトレーニングし続けます。また、長年実施されているMetaのバグ報奨金プログラムを通じて、新しい生成AI機能をセキュリティ研究者に公開しています。
人々のプライバシーを保護するための対策
Metaは、規制当局、政策担当者、専門家から人々のプライバシーを守る責任を負っています。私たちはそうしたステークホルダーと協力し、私たちが構築するものがベストプラクティスに従っていること、データ保護に関する厳しい基準を満たしていることを保証します。
私たちは、生成AI製品を支えているモデルの学習に、どのような種類のデータが使用されているのかを知っていただくことが大切だと考えています。たとえば、友人や家族の間で交わされるプライベートなメッセージがAIの学習に使用されることはありません。Metaが使用するデータの種類については、こちら(英文のみ) で詳しく説明しています。
新しい機能の使用方法ならびにその限界を知ってもらうための対策
AIとの対話がいつ行われ、この新しいテクノロジーがどのように機能しているのかを利用者に知ってもらうため、各機能内で情報を提供しています。また、利用者が機能を使用するそのときに、不正確または不適切な出力が返される可能性があることを明示しています。
この1年間に、私たちは22個のシステムカードを公開し、AIシステムがどのように人々に影響を与える決定を下しているかについて、わかりやすい情報を提供してきました。本日、新しい生成AIシステムカードをMetaのAIウェブサイト(英文のみ)に2つ公開しました。1つは、Meta AIを支えるテキストを生成するAIシステムに関するもの(英文のみ)、もう1つは、AIスタンプ、Meta AI、restyle、backdropに使用される画像を生成するAIシステムに関するもの(英文のみ)です。これらには操作可能なデモが含まれているので、プロンプトの改善がモデルの出力にどのように影響するのかを実際に確かめることができます。
AI機能によって作成された画像であることを知らせるための対策
Metaは業界のベストプラクティスに従っているため、私たちのツールを使って偽情報を拡散することはさらに難しくなっています。Meta AI、restyle、backdropによって作成または編集された画像には、AIが作成したコンテンツであることがわかるようにマークが表示されます。また、他のソースからAIが生成した画像や動画を識別し、そうでないものと区別することができるように、他の企業とも協力しています。ただし、AIスタンプにはこのような機能の追加は予定していません。AIスタンプは写真のようなリアルな映像ではないので、人々が本物と誤解する可能性は低いと考えられます。
現在のところ、業界全体でAI生成コンテンツの識別や分類に用いられる共通の基準はありません。私たちは、こうした基準が必要であると考え、Partnership on AIなどの団体を通じて他の企業とも協力して基準の策定を目指しています。
生成AIを活用して偽情報の拡散を防ぐ方法
AIは、偽情報やその他の有害コンテンツの対処においても重要な役割を果たします。たとえば、私たちが開発したAIテクノロジー(英文のみ)では、以前にファクトチェックした内容とほぼ同じものを検出することできます。また、フューショット学習(英文のみ)を活用したツールもあります。これは、100以上の言語に対応し、新しい有害コンテンツや進化する有害コンテンツにすばやく対処することができます。これまで、1つのAIモデルを学習させるためには、千から、ときには数百万に及ぶサンプルを集めて十分な大きさのデータセットを作り、その後、適切に機能させるためにファインチューニングを行う必要がありました。フューショット学習では、少数のサンプルに基づいてAIモデルを学習させることができます。
生成AIは、既存のAIツールよりももっと速く的確に有害コンテンツを排除できるようになるでしょう。私たちは、コミュニティ規定を学習させた大規模言語モデル(LLM)を、コンテンツのポリシー違反の判断に活用する検証を始めています。最初の検証では、LLMは既存の機械学習モデルよりも高いパフォーマンスを発揮できること、また少なくともフューショット学習などのモデルを強化できることが示唆されました。私たちは、将来的に生成AIをポリシーの実施に活用できるだろうという明るい見通しを持っています。
ダウンロード:Llama 2の責任ある使用のためのガイド