

Si vous parlez des langues comme l’anglais, le mandarin ou l’espagnol, vous pensez peut-être que les applications et les outils web d’aujourd’hui fournissent déjà les technologies de traduction dont nous avons besoin. Mais des milliards de personnes ne peuvent pas encore accéder facilement à des informations et communiquer en ligne dans leur langue maternelle. Les systèmes de traduction automatique d’aujourd’hui s’améliorent rapidement, mais leur entraînement repose encore sur de grandes quantités de données textuelles. C’est pour cette raison qu’ils ne fonctionnent généralement pas bien pour les langues à faibles ressources, c’est-à-dire celles pour lesquelles peu de données d’entraînement sont disponibles, ni pour les langues qui n’ont pas de système d’écriture standardisé.
Faire tomber complètement les barrières linguistiques pourrait changer le monde. Cela permettrait à des milliards de personnes d’accéder à des informations en ligne dans leur langue maternelle ou préférée. En plus d’inclure les personnes qui ne parlent pas l’une des langues qui dominent actuellement Internet, les progrès de la traduction automatique pourraient changer fondamentalement la façon dont les populations communiquent et échangent des idées à travers le monde.
Alors que nous travaillons à créer le métavers, nous devrons inventer des espaces virtuels immersifs auxquels tout le monde pourra participer, quelles que soient les langues parlées.

Par exemple, imaginez que des personnes se trouvant dans un pays où différentes langues sont parlées puissent communiquer entre elles en temps réel à l’aide d’un téléphone, d’une montre ou de lunettes. Ou encore qu’un contenu multimédia sur le web soit accessible pour n’importe qui dans le monde dans sa langue préférée. Dans un avenir pas si lointain, alors que des technologies émergentes comme la réalité virtuelle et la réalité augmentée pourraient estomper les frontières entre le monde virtuel et le monde réel dans le métavers, les outils de traduction permettront à tout le monde de participer à des activités du quotidien (comme créer un club de lecture ou collaborer sur un projet de travail) avec n’importe qui et de n’importe où.
Meta AI annonce une initiative à long terme visant à créer des outils linguistiques et de traduction automatique qui incluront la plupart des langues du monde. Cette initiative comprend deux nouveaux projets. Le premier, No Language Left Behind, consiste à développer un nouveau modèle d’IA avancé qui pourra apprendre des langues sans avoir besoin d’autant d’exemples d’entraînement que les modèles actuels. Nous l’utiliserons pour permettre des traductions professionnelles dans des centaines de langues, de l’asturien au luganda en passant par l’ourdou. Le deuxième, Universal Speech Translator, vise à concevoir de nouvelles approches pour traduire le langage parlé d’une langue à une autre en temps réel, afin de prendre en charge les langues qui n’ont pas de système d’écriture standardisé ainsi que celles qui sont à la fois écrites et parlées.
De nombreux efforts seront nécessaires pour proposer des outils de traduction véritablement universels. Mais nous pensons que cela constitue un grand pas en avant. En partageant des informations sur notre code et nos modèles et en les rendant open source, nous permettrons aux autres de s’appuyer sur notre travail et de nous aider à atteindre cet objectif important.
Les défis de la traduction dans toutes les langues
Les systèmes de traduction basés sur l’IA d’aujourd’hui ne prennent pas en charge les milliers de langues en usage à travers le monde, et ne sont pas conçus pour fournir une traduction vocale en temps réel. Pour que tout le monde puisse en profiter, la communauté de la recherche en traduction automatique devra surmonter trois défis importants. Nous devrons surmonter le manque de données. Pour cela, il faudra acquérir plus de données d’entraînement dans plus de langues et trouver de nouvelles façons de tirer parti de celles déjà disponibles aujourd’hui. Nous devrons surmonter les défis en matière de modélisation qui se poseront à mesure que les modèles se développeront pour servir de plus en plus de langues. Et nous devrons également trouver de nouvelles façons d’évaluer et d’améliorer leurs résultats.
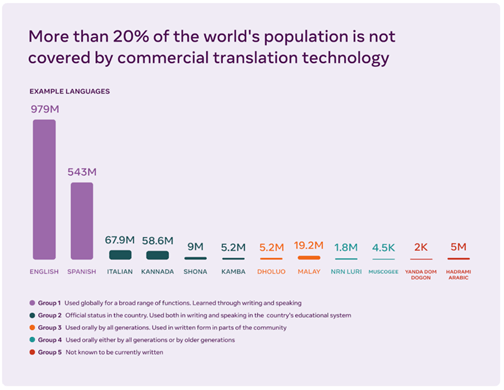

Le manque de données reste l’un des principaux obstacles au développement des outils de traduction dans plus de langues. Les systèmes de traduction automatique de texte reposent généralement sur un entraînement à partir de millions de phrases issues de données annotées. C’est pour cette raison que des systèmes de traduction automatique pouvant produire des traductions de haute qualité n’ont été développés que pour les quelques langues qui dominent le web. Pour en développer dans d’autres langues, il faut trouver des moyens d’acquérir et d’utiliser des exemples d’entraînement à partir de langues peu présentes sur le web.
Pour la traduction orale directe, acquérir des données est encore plus difficile. La plupart des systèmes de traduction automatique vocale utilisent le texte en tant qu’étape intermédiaire : le discours oral dans une langue est d’abord converti en texte, puis ce texte est traduit dans la langue cible et la traduction est entrée dans un système de synthèse vocale pour générer de l’audio. Les traductions vocales sont donc dépendantes du texte, ce qui limite leur efficacité et les rend difficiles à adapter aux langues qui sont principalement parlées.
Les modèles de traduction vocale directe peuvent permettre la traduction de langues qui n’ont pas de système d’écriture standardisé. Cette approche pourra également rendre les systèmes de traduction beaucoup plus rapides et efficaces, car elle élimine les étapes supplémentaires de conversion du discours en texte, de traduction et de génération du discours dans la langue cible.
En plus de requérir des données d’entraînement appropriées dans des milliers de langues, les systèmes de traduction automatique d’aujourd’hui ne sont pas conçus pour s’adapter aux besoins individuels. De nombreux systèmes de traduction automatique sont bilingues, ce qui signifie qu’il existe un modèle distinct pour chaque combinaison, comme anglais-russe ou japonais-espagnol. Cette approche est extrêmement difficile à adapter à des dizaines de combinaisons et à toutes les langues utilisées dans le monde. Imaginez devoir créer et maintenir plusieurs milliers de modèles différents pour chaque combinaison, de thaï-lao à népalais-assamais. Un grand nombre de spécialistes ont suggéré que des systèmes multilingues pourraient être la solution. Mais il est extrêmement difficile d’intégrer de nombreuses langues à un seul modèle multilingue efficace et performant capable de représenter toutes les langues.
En plus d’être confrontés aux mêmes défis que les modèles textuels, les modèles de traduction vocale doivent remédier à la latence (le décalage qui se produit lorsqu’une langue est traduite dans une autre) avant de pouvoir être utilisés efficacement pour une traduction en temps réel. Un défi qui est principalement dû au fait que l’ordre des mots d’une phrase peut ne pas être le même dans une langue que dans une autre. Même les spécialistes de la traduction simultanée ont un retard d’environ trois secondes sur le discours original. Prenons l’exemple d’une phrase en allemand, « Ich möchte alle Sprachen übersetzen », et de son équivalent en espagnol, « Quisiera traducir todos los idiomas ». Les deux phrases signifient « Je voudrais traduire toutes les langues ». Mais traduire de l’allemand vers le français en temps réel serait plus difficile, car le verbe « traduire » apparaît à la fin de la phrase en allemand, alors qu’en espagnol et en français, l’ordre des mots est similaire.
Enfin, alors que nous prenons en charge de plus en plus de langues, nous devons développer de nouvelles façons d’évaluer le travail produit par les modèles de traduction automatique. Il existe déjà des ressources qui permettent d’évaluer la qualité des traductions, par exemple, de l’anglais vers le russe. Mais qu’en est-il de la combinaison amharique-kazakh, par exemple ? À mesure que le nombre de langues que nos modèles de traduction automatique peuvent traduire augmente, nous devrons développer de nouvelles approches pour l’entraînement des données et la mesure. Et en plus d’évaluer les performances des systèmes de traduction automatique en termes de précision, il est important de s’assurer que les traductions sont effectuées de manière responsable. Nous devrons trouver des moyens de nous assurer que les systèmes de traduction automatique tiennent compte des éléments culturels et ne favorisent pas les préjugés. Meta AI s’efforce de relever chacun de ces trois défis, tels que nous les décrivons dans les sections ci-dessous.
Entraîner les systèmes de traduction vocale directe et à faibles ressources
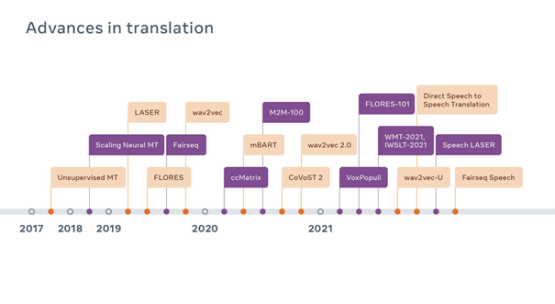
Pour permettre la traduction de langues à faibles ressources et poser les bases d’un avenir où un plus grand nombre de langues pourront être traduites, qu’elles soient très répandues ou non, nous développons nos techniques de création automatique d’ensembles de données. L’une de ces techniques est LASER, une boîte à outils open source qui couvre désormais plus de 125 langues écrites et 28 scripts différents.
LASER convertit des phrases dans différentes langues en une seule représentation multilingue. Nous effectuons ensuite une recherche de similitude multilingue à grande échelle afin d’identifier les phrases ayant une représentation similaire, c’est-à-dire susceptibles d’avoir la même définition dans différentes langues. Nous avons utilisé LASER pour développer des systèmes tels que ccMatrix et ccAligned, qui sont capables de trouver des textes parallèles sur Internet. Pour les langues à faibles ressources, nous avons créé une nouvelle méthode d’entraînement qui permet à LASER de se concentrer sur des sous-groupes de langues spécifiques (tels que les langues bantoues) et d’apprendre à partir d’ensembles de données beaucoup plus réduits. LASER peut ainsi fonctionner efficacement à grande échelle dans toutes les langues. Ces progrès nous permettront de couvrir plus de langues alors que nous travaillons à les développer et à les améliorer, le but étant de prendre en charge l’exploration de données pour des centaines de langues, voire toutes les langues ayant un système d’écriture. Nous avons récemment développé le système LASER afin qu’il fonctionne également avec le discours oral : en développant des représentations pour le discours oral et le texte dans le même espace multilingue, nous sommes en mesure d’extraire des traductions d’un discours oral dans une langue à du texte dans une autre langue, voire même des traductions vocales directes. Grâce à cette méthode, nous avons déjà mis en correspondance près de 1 400 heures de discours en français, en allemand, en espagnol et en anglais.
Les données textuelles sont importantes, mais elles ne sont pas suffisantes pour créer des outils de traduction répondant à tous les besoins. Pour la traduction vocale, des données de référence n’étaient auparavant disponibles que dans quelques langues. C’est pour cela que nous avons créé CoVoST 2, qui couvre 22 langues et 36 combinaisons, ainsi que différents niveaux de ressources. De plus, il est difficile de trouver de grandes quantités d’audio dans différentes langues. VoxPopuli, qui contient 400 000 heures de langage parlé dans 23 langues, permet un apprentissage semi-supervisé et auto-contrôlé à grande échelle pour des cas d’utilisation tels que la reconnaissance vocale et la traduction vocale. VoxPopuli a ensuite été utilisé pour créer le plus grand modèle pré-entraîné ouvert et universel pour 128 langues et plusieurs tâches axées sur le discours, y compris la traduction vocale. Un modèle qui a amélioré la traduction de discours oral en 21 langues vers du texte en anglais de 7,4 BLEU sur l’ensemble de données CoVoST 2.
Développer des modèles qui fonctionnent pour de nombreuses langues et différentes modalités


En plus de produire plus de données pour l’entraînement des systèmes de traduction automatique et de les mettre à la disposition d’autres équipes de recherche, nous cherchons à améliorer les capacités des modèles afin de prendre en charge la traduction de beaucoup plus de langues. Aujourd’hui, les systèmes de traduction automatique ne fonctionnent souvent que pour une seule modalité et un ensemble limité de langues. Si le modèle est trop petit pour représenter de nombreuses langues, ses performances peuvent en pâtir et des inexactitudes peuvent apparaître dans les traductions textuelles et vocales. Les innovations en matière de modélisation nous aideront à créer un avenir où les traductions passeront d’une modalité à l’autre rapidement et de manière transparente, à savoir de la voix au texte, du texte à la voix, du texte au texte ou de la voix à la voix, et ce, dans une multitude de langues.
Pour améliorer les performances de nos modèles de traduction automatique, nous avons énormément investi dans la création de modèles qui s’entraînent efficacement malgré une grande capacité, en nous concentrant sur des modèles multicouches appelés « MoE » (pour « Mixture of Experts »). En augmentant la taille des modèles et en utilisant une fonction de routage automatique afin que différents tokens utilisent différentes routes, nous avons pu équilibrer les performances des traductions à ressources élevées et à faibles ressources.
Pour étendre la traduction automatique de texte à 101 langues, nous avons créé le premier système de traduction de texte multilingue qui n’est pas axé sur l’anglais. En général, les systèmes bilingues traduisent d’abord la langue source vers l’anglais, puis l’anglais vers la langue cible. Pour rendre ces systèmes plus efficaces et améliorer leur qualité, nous avons arrêté d’utiliser l’anglais en tant que référence, afin que les langues puissent être traduites directement dans d’autres langues, sans passer par l’anglais. Bien que cela ait augmenté la capacité du modèle, les modèles multilingues étaient auparavant incapables d’atteindre le même niveau de qualité que les systèmes bilingues personnalisés. Mais récemment, notre système de traduction multilingue a remporté le concours de la conférence annuelle sur la traduction automatique (WMT), prenant ainsi le pas sur les meilleurs modèles bilingues.
Notre objectif est que notre technologie soit inclusive et qu’elle prenne en charge à la fois les langues écrites et celles qui n’ont pas de système d’écriture standardisé. Pour cela, nous développons actuellement un système de traduction vocale qui ne repose pas sur la génération d’une représentation textuelle intermédiaire. Cette approche s’est avérée plus rapide que le système en cascade traditionnel qui combine des modèles de reconnaissance vocale, de traduction automatique et de synthèse vocale séparés. Grâce à une efficacité améliorée et à une architecture plus simple, la reconnaissance vocale directe pourrait permettre une traduction en temps réel de qualité presque humaine pour les appareils du futur, comme les lunettes de réalité augmentée. Enfin, afin de créer des traductions parlées qui préservent le ton et le caractère du discours de chaque personne, nous nous efforçons de conserver certains aspects de l’audio d’entrée, tels que l’intonation, dans les traductions audio générées.
Mesurer nos performances dans des centaines de langues
Le développement de modèles capables de traduire de nombreuses langues à grande échelle soulève une question importante : comment pouvons-nous déterminer si nous avons développé de meilleures données ou de meilleurs modèles ? L’évaluation des performances d’un modèle multilingue à grande échelle est compliquée, en particulier parce que cela nous oblige à avoir une expertise de terrain dans toutes les langues prises en charge par le modèle. Un défi qui prend du temps, qui demande beaucoup de ressources et qui est souvent très peu pratique.
Nous avons créé FLORES-101, les premiers ensembles de données d’évaluation de la traduction multilingue couvrant 101 langues, ce qui a permis aux équipes de recherche de tester et d’améliorer rapidement les modèles de traduction multilingue. Contrairement aux ensembles de données existants, FLORES-101 permet aux équipes de recherche de quantifier les performances des systèmes pour toutes les combinaisons, pas seulement depuis et vers l’anglais. Pour les millions de personnes dans le monde qui vivent dans des régions où il existe des dizaines de langues officielles, cela permet de créer des systèmes de traduction qui répondent à des besoins importants.
En utilisant FLORES-101, nous avons collaboré avec d’autres leaders de la communauté de recherche en IA pour faire progresser la traduction multilingue à faibles ressources. Lors de la conférence WMT 2021, nous avons mis en place un groupe de travail pour progresser collectivement dans ce domaine. Des équipes de recherche du monde entier y ont participé, une grande partie en se concentrant sur les langues qui les concernaient personnellement. Nous avons hâte de continuer à développer FLORES afin de prendre en charge des centaines de langues.
Et si nous faisons des progrès importants vers la traduction universelle, nous nous efforçons également de le faire de manière responsable. Nous travaillons avec des linguistes pour mieux comprendre les défis liés à la collection d’ensembles de données précises, ainsi qu’avec des réseaux d’évaluation afin de nous assurer que les traductions sont exactes. Nous menons également des études de cas avec des locuteurs et locutrices de plus de 20 langues pour comprendre quelles fonctionnalités de traduction sont importantes pour les personnes d’horizons différents, et comment elles utiliseront les traductions produites par nos modèles d’IA. Le développement responsable de la traduction universelle comporte de nombreux autres aspects, de l’atténuation des préjugés et des dommages potentiels à la préservation des éléments culturels lorsque les informations sont transmises d’une langue à l’autre. Pour atteindre nos objectifs de traduction à long terme, nous aurons non seulement besoin d’une expertise en IA, mais aussi de la contribution durable d’un grand nombre de spécialistes, d’équipes de recherche et d’individus du monde entier.
Et maintenant ?
Si avec les projets No Language Left Behind et Universal Speech Translator et grâce aux efforts de la communauté de recherche en traduction automatique, nous parvenons à créer des technologies de traduction inclusives, les mondes virtuel et réel s’ouvriront d’une façon qui était jusqu’à présent impossible. Nous sommes déjà en train de faire des progrès dans la traduction de langues à faibles ressources, un obstacle important à la traduction universelle pour la majeure partie de la population mondiale. En faisant progresser et en rendant accessibles nos travaux sur la création de corpus, la modélisation multilingue et l’évaluation, nous espérons que d’autres équipes de recherche nous aideront à faire de ces systèmes de traduction une réalité du quotidien.
La communication est l’une des caractéristiques les plus importantes de l’être humain. Les technologies, de la presse écrite à la discussion vidéo, ont souvent transformé notre façon de communiquer et de partager des idées. L’efficacité de ces technologies et d’autres augmentera lorsqu’elles pourront fonctionner de la même manière, et ce pour des milliards de personnes dans le monde, en leur donnant un accès égal à l’information et en leur permettant de communiquer avec une audience beaucoup plus large, quelles que soient les langues qu’elles parlent ou écrivent. Si nous voulons créer un monde plus inclusif et connecté, nous devons tout mettre en œuvre pour supprimer les obstacles à l’information et aux opportunités existants en donnant aux personnes les moyens de s’exprimer dans la langue de leur choix.