
Puntos de interés:
- Meta está comprometida con la IA de código abierto. En este enlace puedes leer una carta de Mark Zuckerberg detallando por qué el código abierto es bueno para los desarrolladores, bueno para Meta y bueno para el mundo.
- Nuestros modelos más recientes expanden la longitud de contexto a 128K, añaden soporte en ocho idiomas e incluyen el Llama 3.1 405B – el primer modelo de IA de código abierto de última generación.
- Llama 3.1 405B es único en su clase, con una flexibilidad y un control inigualables y unas funciones de última generación que rivalizan con los mejores modelos de código cerrado. Nuestro nuevo modelo permitirá a la comunidad habilitar nuevos flujos de trabajo, como la generación de datos sintéticos y la destilación de modelos.
- Seguimos desarrollando Llama para convertirlo en un sistema, proporcionando más componentes que funcionen con el modelo, incluido un sistema de referencia. Queremos empoderar a los desarrolladores con herramientas para crear sus propios agentes personalizados y nuevos tipos de comportamiento de los agentes. Estamos reforzando esto con nuevas herramientas de seguridad, como Llama Guard 3 y Prompt Guard, para ayudar a construir de forma responsable. También estamos lanzando una solicitud de comentarios sobre la API Llama Stack, una interfaz estándar que esperamos facilite a los proyectos de terceros el aprovechamiento de los modelos Llama.
- El ecosistema está configurado y listo para funcionar con más de 25 socios, entre ellos AWS, NVIDIA, Databricks, Groq, Dell, Azure y Google Cloud, que ofrecen servicios desde el primer día.
- Prueba Llama 3.1 405B en Estados Unidos en WhatsApp y meta.ai haciendo una pregunta compleja sobre matemáticas o codificación.
Hasta ahora, los grandes modelos lingüísticos de código abierto han ido casi siempre a la zaga de sus homólogos cerrados en lo que se refiere a capacidades y rendimiento. Ahora, iniciamos una nueva era con el código abierto a la cabeza. Publicamos Meta Llama 3.1 405B, que creemos que es el modelo básico de código abierto más grande y capaz del mundo. Con más de 300 millones de descargas totales de todas las versiones de Llama hasta la fecha, no hemos hecho más que empezar.
Presentamos Llama 3.1
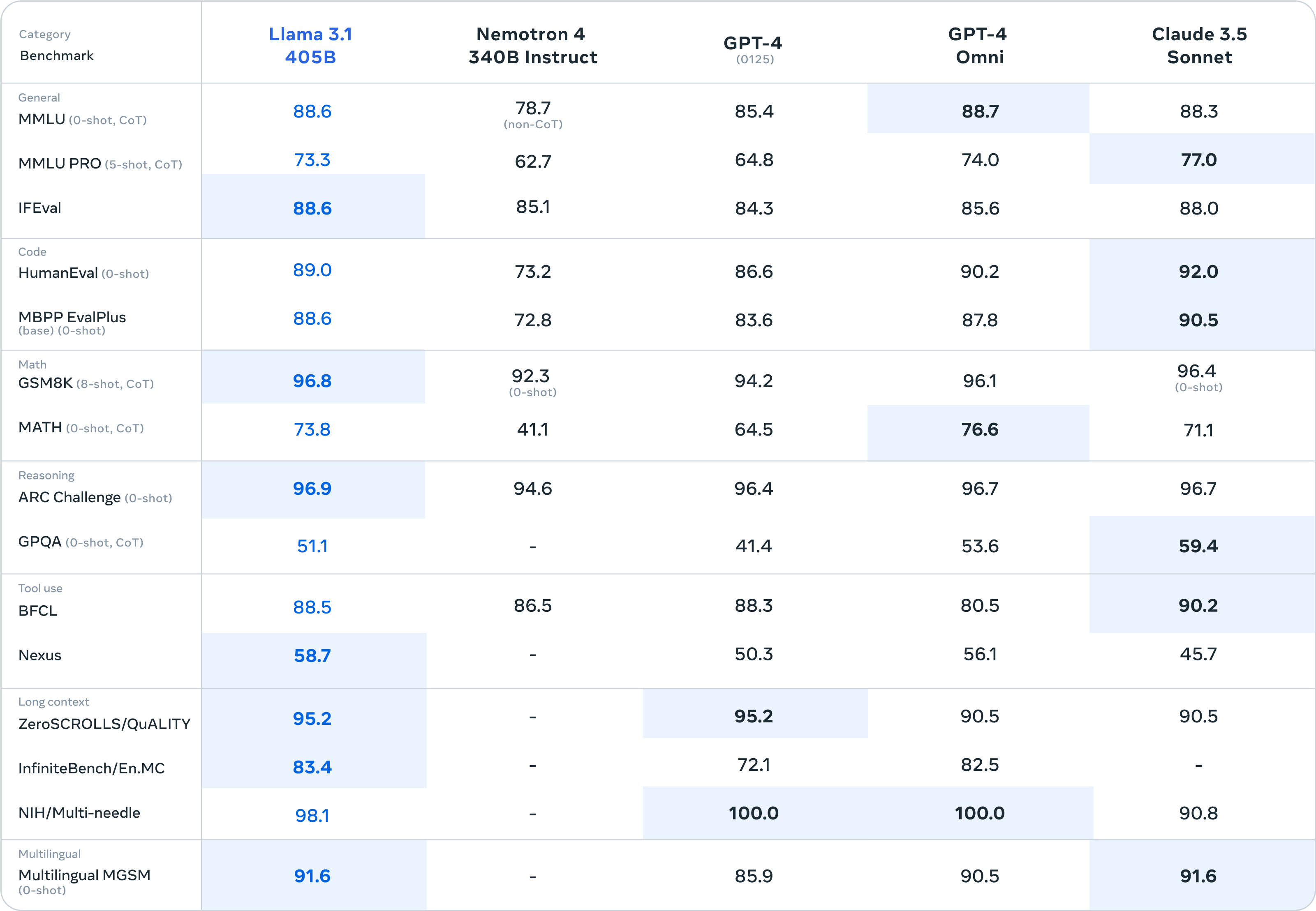
Llama 3.1 405B es el primer modelo de código abierto que compite con los principales modelos de IA en lo que respecta a las funciones más avanzadas de conocimientos generales, capacidad de conducción, matemáticas, uso de herramientas y traducción multilingüe. Con el lanzamiento del modelo 405B, estamos impulsando la innovación, con oportunidades de crecimiento y explotación sin precedentes. Creemos que la última generación de Llama dará rienda suelta a nuevas aplicaciones y paradigmas de modelización, incluida la generación de datos sintéticos para permitir la mejora y el entrenamiento de modelos más pequeños, así como la destilación de modelos, una capacidad que nunca se ha logrado a esta escala en código abierto.
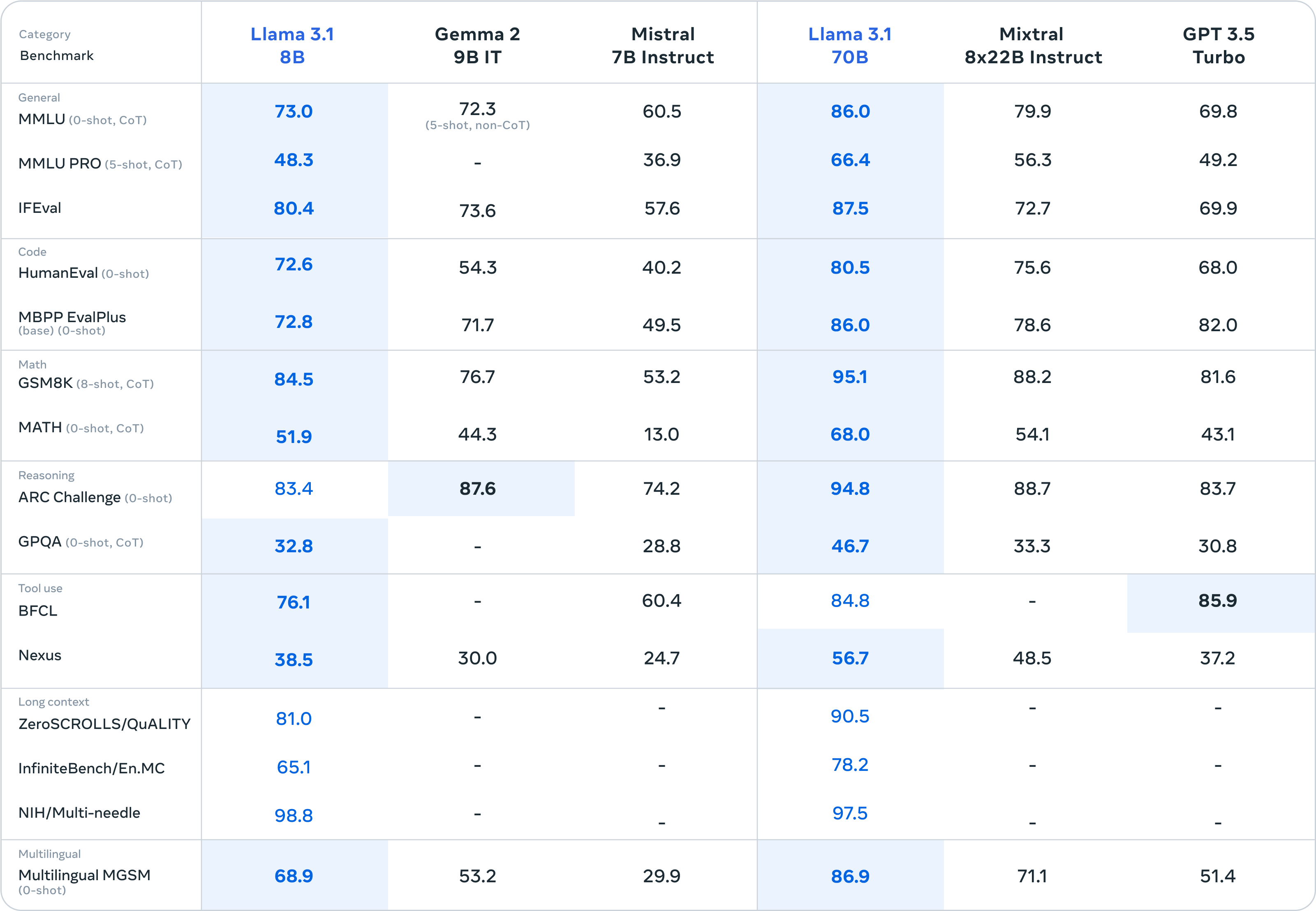
Como parte de este último lanzamiento, presentamos versiones actualizadas de los modelos 8B y 70B. Son multilingües y tienen una longitud de contexto significativamente mayor, de 128K, un uso de herramientas de última generación y capacidades de razonamiento más potentes en general. Esto permite que nuestros últimos modelos sean compatibles con casos de uso avanzados, como el resumen de textos largos, los agentes conversacionales multilingües y los asistentes de codificación. También hemos introducido cambios en nuestra licencia, lo que permite a los desarrolladores utilizar los resultados de los modelos Llama -incluido el 405B- para mejorar otros modelos. Fieles a nuestro compromiso con el código abierto, a partir de hoy ponemos estos modelos a disposición de la comunidad para su descarga en llama.meta.com y Hugging Face, además de estar disponibles para su desarrollo inmediato en nuestro amplio ecosistema de plataformas asociadas.
Evaluación de modelos
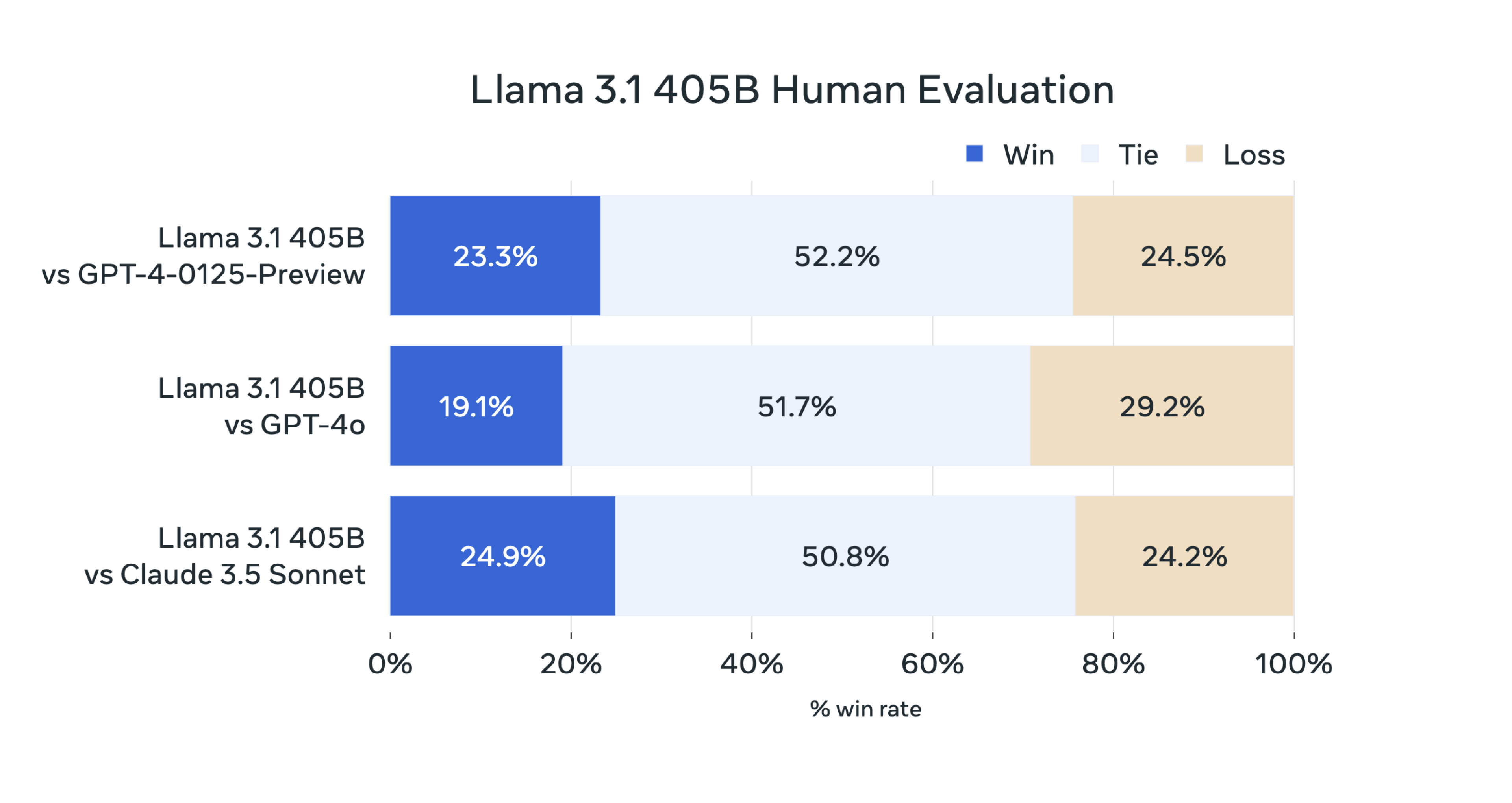
Para esta versión, hemos evaluado el rendimiento en más de 150 conjuntos de datos de referencia que abarcan una amplia variedad de idiomas. Además, hemos llevado a cabo evaluaciones humanas exhaustivas que comparan Llama 3.1 con modelos de la competencia en escenarios reales. Nuestra evaluación experimental sugiere que nuestro modelo básico es competitivo con los principales modelos de base en una serie de tareas, como GPT-4, GPT-4o y Claude 3.5 Sonnet. Además, nuestros modelos más pequeños son competitivos con modelos cerrados y abiertos que tienen un número similar de parámetros.
Arquitectura del modelo
El entrenamiento de Llama 3.1 405B con más de 15 billones de tokens, nuestro mayor modelo hasta la fecha, supuso un gran reto. Para poder entrenar a esta escala y conseguir los resultados que hemos obtenido en un tiempo razonable, hemos optimizado de forma significativa toda nuestra estructura de entrenamiento y hemos aumentado el entrenamiento de nuestro modelo a más de 16.000 GPU H100, lo que convierte a la 405B en el primer modelo Llama entrenado a esta escala.
Para solucionarlo, tomamos decisiones de diseño centradas en mantener el proceso de desarrollo del modelo escalable y sencillo.
- Para maximizar la estabilidad del entrenamiento, optamos por una arquitectura estándar de modelo de transformador con descodificador, con pequeñas adaptaciones, en lugar de un modelo mixto experto.
- Adoptamos un procedimiento iterativo de post-entrenamiento, en el que cada ronda utiliza un ajuste fino supervisado y una optimización directa de las preferencias. Esto nos permitió crear datos sintéticos de la máxima calidad para cada ronda y mejorar el rendimiento de cada capacidad.
En comparación con versiones anteriores de Llama, hemos mejorado la cantidad y la calidad de los datos que utilizamos en el preentrenamiento y el postentrenamiento. Estas mejoras incluyen el desarrollo de procesos de preprocesamiento y curación más cuidadosos para los datos de preentrenamiento y el desarrollo de enfoques de filtrado y control de calidad más rigurosos para los datos de postentrenamiento.
Como esperaban las leyes de escalado de los modelos de lenguaje, nuestro nuevo modelo básico supera a los modelos más pequeños entrenados con el mismo procedimiento. También utilizamos el modelo de parámetros 405B para mejorar la calidad del postentrenamiento de nuestros modelos más pequeños.
Para que un modelo de la escala del 405B pueda realizar inferencias a gran escala, hemos cuantificado nuestros modelos de 16 bits (BF16) a 8 bits (FP8), reduciendo así los requisitos informáticos necesarios y permitiendo que el modelo se ejecute en un único nodo servidor.
Configuración de instrucciones y chat
Con Llama 3.1 405B, nos esforzamos por mejorar la utilidad, la calidad y la capacidad de seguir instrucciones detalladas de los modelos en respuesta a las instrucciones de los usuarios, garantizando al mismo tiempo altos niveles de seguridad. Nuestros mayores retos fueron dar soporte a más funciones, la ventana contextual de 128K y el mayor tamaño de los modelos.
En el postentrenamiento, produjimos modelos de chat finales realizando varias rondas de alineación sobre el modelo preentrenado. Cada ronda implica un ajuste fino supervisado (SFT), un muestreo de rechazo (RS) y una optimización directa de preferencias (DPO). Utilizamos la generación de datos sintéticos para producir la gran mayoría de nuestros ejemplos de SFT, iterando varias veces para producir datos sintéticos cada vez de mayor calidad en todas las características. Además, invertimos en múltiples técnicas de procesamiento de datos para filtrar estos datos sintéticos con la máxima calidad. Esto nos permite escalar la cantidad de datos ajustados entre recursos.
Equilibramos cuidadosamente los datos para producir un modelo de alta calidad en todas las características. Por ejemplo, mantenemos la calidad de nuestro modelo en las pruebas comparativas de contexto corto, incluso cuando ampliamos a 128K de contexto. Del mismo modo, nuestro modelo sigue proporcionando respuestas extremadamente útiles, incluso cuando añadimos mitigaciones de seguridad.
El sistema Llama
Las plantillas Llama siempre han estado pensadas para funcionar como parte de un sistema global que puede orquestar varios componentes, incluida la llamada a herramientas externas. Nuestra visión es ir más allá de las plantillas básicas para dar a los desarrolladores acceso a un sistema más amplio que les proporcione la flexibilidad necesaria para diseñar y crear ofertas personalizadas que se ajusten a su visión. Esta reflexión comenzó el año pasado, cuando introdujimos por primera vez la incorporación de componentes ajenos al núcleo del LLM.
Como parte de nuestros continuos esfuerzos por desarrollar responsablemente la IA más allá de la capa del modelo y ayudar a otros a hacer lo mismo, estamos lanzando un sistema de referencia completo que incluye varias aplicaciones de muestra, así como nuevos componentes como Llama Guard 3, un modelo de seguridad multilingüe, y Prompt Guard, un filtro de inyección inmediata. Estas aplicaciones de muestra son de código abierto y pueden ser desarrolladas por la comunidad.
La implementación de los componentes de esta visión del sistema Llama sigue estando fragmentada. Por eso hemos empezado a trabajar con la industria, las startups y la comunidad en general para ayudar a definir mejor las interfaces de estos componentes. Para apoyar esto, estamos lanzando una solicitud de comentarios en GitHub para lo que llamamos el «Llama Stack». Llama Stack es un conjunto de interfaces estandarizadas y basadas en opiniones sobre cómo construir componentes canónicos del conjunto de herramientas (ajuste fino, generación de datos sintéticos) y aplicaciones de agentes. Esperamos que se adopten en todo el ecosistema para facilitar la interoperabilidad.
Agradeceremos comentarios y formas de mejorar la propuesta. Nos entusiasma la idea de ampliar el ecosistema en torno a Llama y reducir las barreras para desarrolladores y proveedores de plataformas.
La apertura impulsa la innovación
A diferencia de los modelos cerrados, Llama se puede descargar. Los desarrolladores pueden personalizar completamente los modelos según sus necesidades y aplicaciones, entrenarlos con nuevos conjuntos de datos y realizar ajustes adicionales. De este modo, la comunidad de desarrolladores y el resto del mundo pueden aprovechar mejor el potencial de la IA generativa. Los desarrolladores pueden personalizar completamente sus aplicaciones y ejecutarlas en cualquier entorno, ya sea en las instalaciones, en la nube o incluso localmente en un portátil, todo ello sin compartir datos con Meta.
Aunque muchos podrían argumentar que los modelos cerrados son más económicos, los modelos Llama ofrecen uno de los costes por token más bajos del sector, según las pruebas realizadas por Artificial Analysis. Y, como Mark Zuckerberg compartió, el código abierto garantizará que más personas de todo el mundo tengan acceso a los beneficios y oportunidades de la IA, que el poder no se concentre en manos de unos pocos y que la tecnología pueda implantarse de forma más uniforme y segura en toda la sociedad. Por eso seguimos dando pasos en el camino para que la IA de acceso abierto se convierta en la norma del sector.
Hemos visto a la comunidad construir cosas increíbles con modelos anteriores de Llama, incluyendo un «compañero de estudio» creado con Llama e implementado en WhatsApp y Messenger, un modelo de lenguaje del área médica diseñado para ayudar a tomar decisiones clínicas, y una organización sanitaria sin ánimo de lucro en Brasil que organiza y comunica a los pacientes información sobre su hospitalización, todo ello con seguridad de datos. Estamos impacientes por ver lo que la comunidad construirá con nuestros últimos modelos, gracias al poder del código abierto.
Construir con Llama 3.1 405B
Para el desarrollador medio, utilizar un modelo de la escala del 405B es todo un reto. Aunque se trata de un modelo increíblemente potente, somos conscientes de que requiere importantes recursos informáticos y experiencia para trabajar con él. Hablamos con la comunidad y nos dimos cuenta de que el desarrollo de IA generativa es mucho más que modelos de estímulos.
Queremos que todo el mundo pueda sacar el máximo partido del 405B:
- Inferencia en tiempo real y por lotes
- Ajuste fino supervisado
- Evaluación del modelo para su aplicación específica
- Preentrenamiento continuo
- Generación aumentada de recuperación (RAG)
- Llamada a funciones
- Generación de datos sintéticos
Aquí es donde el ecosistema Llama puede ayudar. Desde el primer día, los desarrolladores pueden aprovechar todas las funciones avanzadas del modelo 405B y empezar a construir inmediatamente. Los desarrolladores también pueden explorar flujos de trabajo avanzados como la generación de datos sintéticos fáciles de usar, seguir instrucciones preparadas para la destilación de modelos y habilitar RAG continua con soluciones de socios como AWS, NVIDIA y Databricks. Además, Groq ha optimizado la inferencia de baja latencia para implementaciones en la nube, y Dell ha logrado optimizaciones similares para sistemas locales.
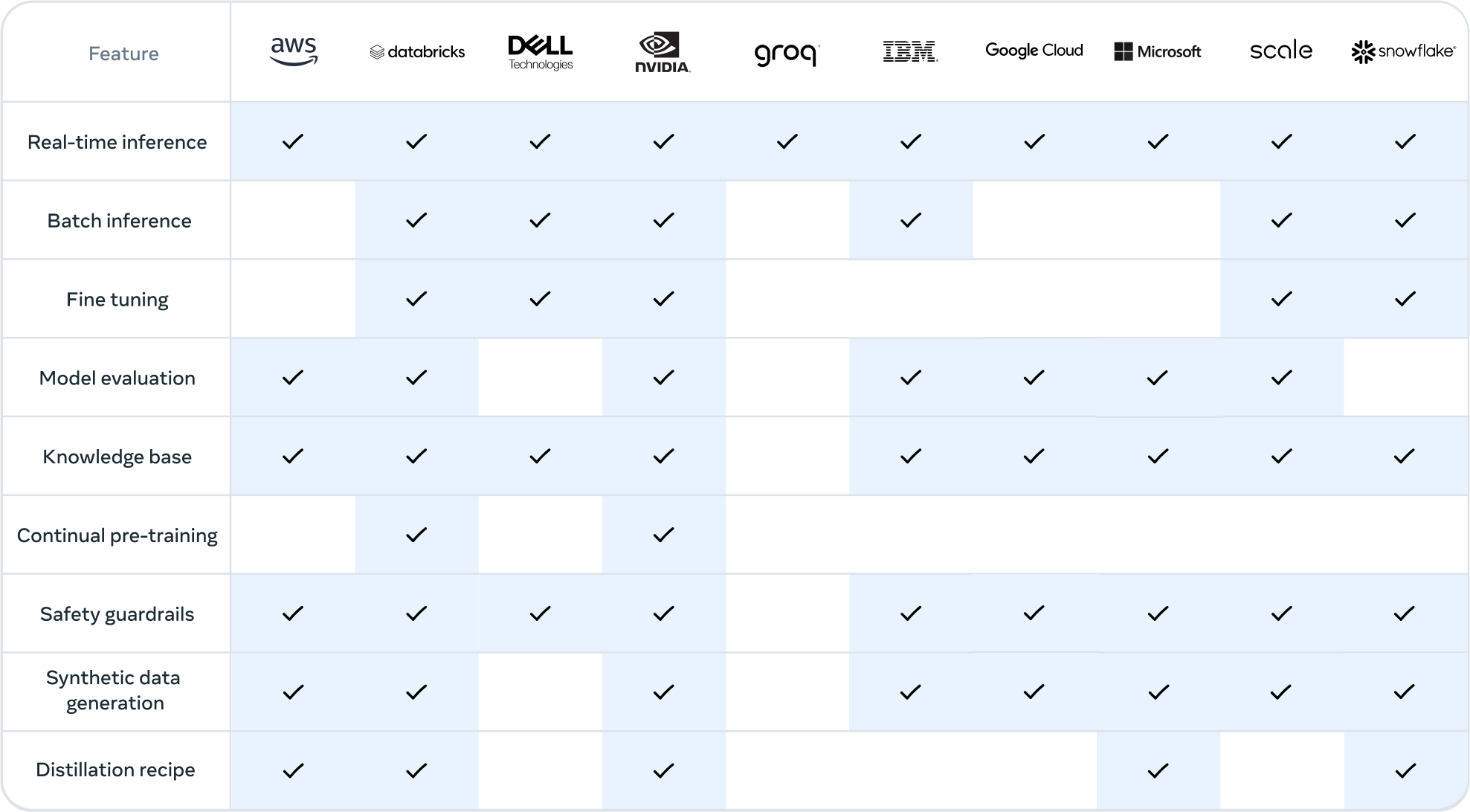
Trabajamos con proyectos clave de la comunidad como vLLM, TensorRT y PyTorch para apoyarlos desde el primer día y garantizar que la comunidad esté preparada para la implementación en producción.
Esperamos que nuestro lanzamiento de 405B también estimule la innovación en toda la comunidad para facilitar la inferencia y el ajuste fino de modelos de esta escala, así como permitir la próxima ola de investigación en destilación de modelos.
Pruebe hoy mismo la colección de modelos Llama 3.1
Estamos emocionados por ver qué hace la comunidad con este trabajo. Hay mucho potencial para crear nuevas experiencias útiles utilizando el multilingüismo y la ampliación del contexto. Con Llama Stack y las nuevas herramientas de seguridad, esperamos seguir construyendo junto con la comunidad de código abierto de forma responsable. Antes de lanzar un modelo, trabajamos para identificar, evaluar y mitigar los riesgos potenciales a través de diversas medidas, entre ellas ejercicios de descubrimiento de riesgos previos a la implantación mediante red teaming y puesta a punto de la seguridad. Por ejemplo, realizamos un amplio red teaming con expertos externos e internos para poner a prueba la resistencia de los modelos y encontrar formas inesperadas de utilizarlos. (Más información sobre cómo estamos ampliando nuestra colección de modelos Llama 3.1 de forma responsable en este blog).
Aunque este es nuestro modelo más grande hasta la fecha, creemos que aún queda mucho terreno por explorar en el futuro, incluidos tamaños más adaptados a los dispositivos, modalidades adicionales y una mayor inversión en la capa de la plataforma de agentes. Como siempre, estamos deseando ver todos los increíbles productos y experiencias que la comunidad creará con estos modelos.
Este trabajo ha contado con el apoyo de nuestros socios de la comunidad de IA. Nos gustaría dar las gracias y reconocer (por orden alfabético) a: Accenture, Amazon Web Services, AMD, Anyscale, CloudFlare, Databricks, Dell, Deloitte, Fireworks.ai, Google Cloud, Groq, Hugging Face, IBM WatsonX, Infosys, Intel , Kaggle, Microsoft Azure, NVIDIA DGX Cloud, OctoAI, Oracle Cloud, PwC, Replicate, Sarvam AI, Scale.AI, SNCF, Snowflake, Together AI y UC Berkeley – vLLM Project.