
Puntos de interés:
- Hoy presentamos Meta Llama 3, la nueva generación de nuestro modelo de lenguaje de gran tamaño de código abierto.
- Los modelos de Llama 3 pronto estarán disponibles en AWS, Databricks, Google Cloud, Hugging Face, Kaggle, IBM WatsonX, Microsoft Azure, NVIDIA NIM y Snowflake. Además, contarán con soporte de plataformas de hardware ofrecidas por AMD, AWS, Dell, Intel, NVIDIA y Qualcomm.
- Estamos comprometidos con el desarrollo responsable de Llama 3 y ofrecemos diversos recursos para ayudar a otros a utilizarlo también de forma responsable. Esto incluye nuevas herramientas de confianza y seguridad como Llama Guard 2, Code Shield y CyberSec Eval 2.
- En los próximos meses, esperamos introducir nuevas funciones, ventanas contextuales más largas, tamaños de plantilla adicionales y un rendimiento mejorado, además de compartir el documento de investigación sobre Llama 3.
Nos complace compartir los dos primeros modelos de la próxima generación de Llama, Meta Llama 3, disponibles para un amplio uso. Esta versión presenta modelos de lenguaje pre-entrenados y ajustados a las instrucciones con parámetros 8B y 70B, que pueden soportar una amplia variedad de casos de uso. Esta nueva generación de Llama demuestra un rendimiento puntero en una amplia gama de parámetros de referencia del sector y ofrece nuevas funciones, como la mejora del razonamiento. Creemos que son los mejores modelos de código abierto de su clase. Además, para respaldar el enfoque de código abierto que mantenemos desde hace tiempo, estamos poniendo Llama 3 en manos de la comunidad. Queremos dar paso a la próxima ola de innovación en IA en todos los ámbitos: desde aplicaciones hasta herramientas para desarrolladores, evaluaciones, optimizaciones de inferencia y mucho más.
Nuestros objetivos con Llama 3
Con Llama 3, nos propusimos construir los mejores modelos abiertos que estuvieran a la altura de los mejores modelos propietarios disponibles en la actualidad. Queríamos tener en cuenta los comentarios de los desarrolladores para aumentar la utilidad general de Llama 3 y lo estamos haciendo sin dejar de desempeñar un papel de liderazgo en el uso y despliegue responsables de los LLM. Adoptamos la ética del código abierto de publicar rápido y con frecuencia para que la comunidad pueda acceder a estos modelos mientras aún están en desarrollo. Los modelos basados en texto que publicamos hoy son los primeros de la colección de modelos Llama 3. Nuestro objetivo en un futuro próximo es hacer que Llama 3 sea multilingüe y multimodal, que tenga un contexto más amplio y que siga mejorando el rendimiento general de las capacidades básicas de LLM, como el razonamiento y la codificación.
Rendimiento de vanguardia
Nuestros nuevos modelos Llama 3 de parámetros 8B y 70B suponen un gran salto con respecto a Llama 2 y establecen un un nuevo estándar para los modelos LLM a esas escalas. Gracias a las mejoras en el pre-entrenamiento y el post-entrenamiento, nuestros modelos pre-entrenados y ajustados a las instrucciones a la escala de parámetros de 8B y 70B son los mejores actualmente. Las optimizaciones en nuestros procedimientos de post-entrenamiento redujeron sustancialmente las tasas de falsos rechazos, mejoraron la alineación y aumentaron la diversidad en las respuestas de los modelos. También hemos observado grandes mejoras en capacidades como el razonamiento, la generación de código y el seguimiento de instrucciones, lo que hace que Llama 3 sea más direccionable.
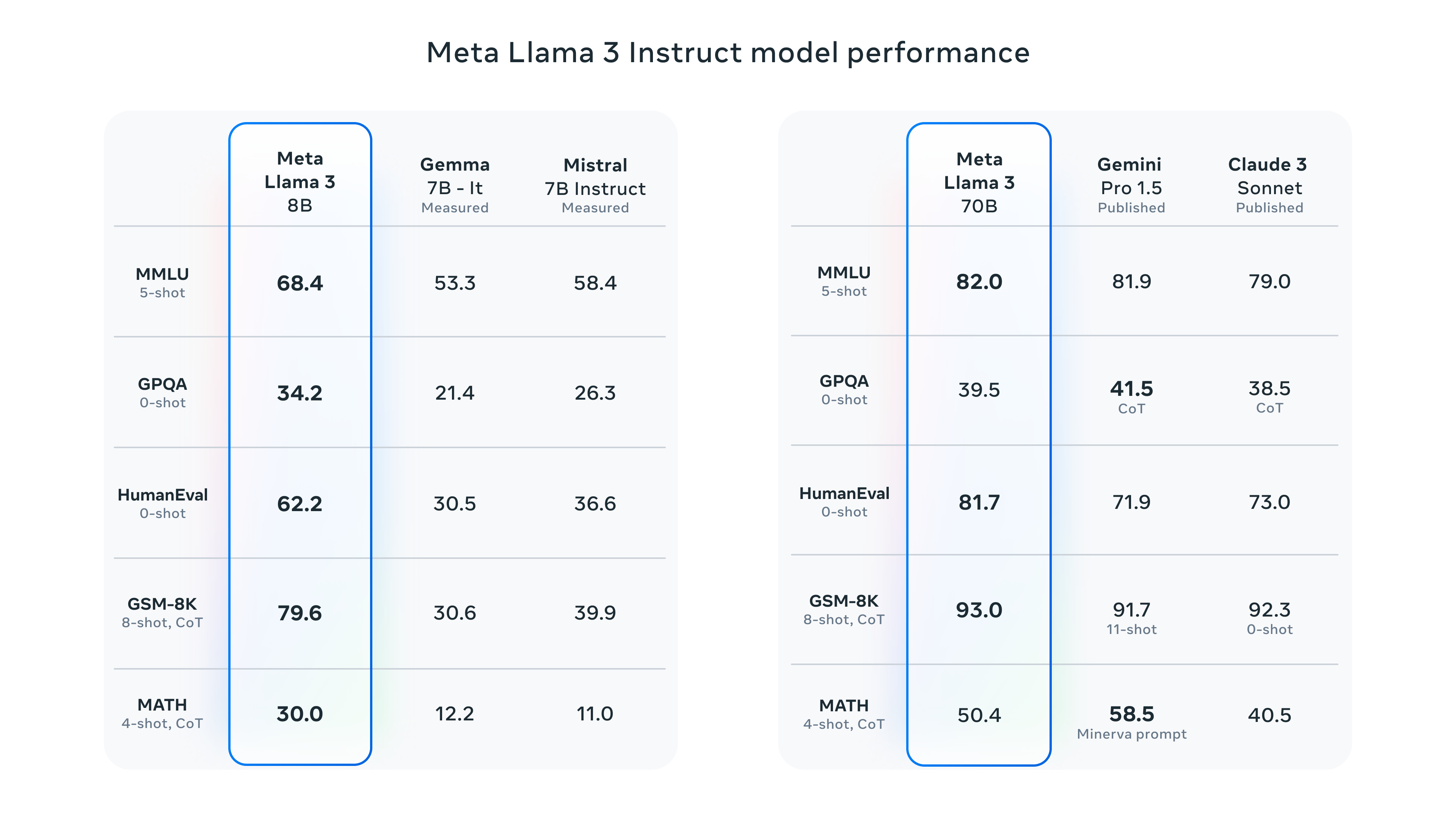
*Por favor, consulta los detalles para conocer la configuración y parámetros con los que se calculan estas evaluaciones.
En el desarrollo de Llama 3, nos fijamos en el rendimiento del modelo en puntos de referencia estándar y también tratamos de optimizar el rendimiento para escenarios del mundo real. Para ello, desarrollamos un nuevo conjunto de evaluación humana de alta calidad. Este conjunto de evaluación contiene 1.800 preguntas que cubren 12 casos de uso clave: pedir consejo, lluvia de ideas, clasificación, respuesta a preguntas cerradas, codificación, escritura creativa, extracción, adopción de un personaje/persona, respuesta a preguntas abiertas, razonamiento, reescritura y resumen. Para evitar el sobreajuste accidental de nuestros modelos en este conjunto de evaluación, ni siquiera nuestros propios equipos de modelización tienen acceso a él. El siguiente gráfico muestra los resultados agregados de nuestras evaluaciones humanas en todas estas categorías e instrucciones con Claude Sonnet, Mistral Medium y GPT-3.5.
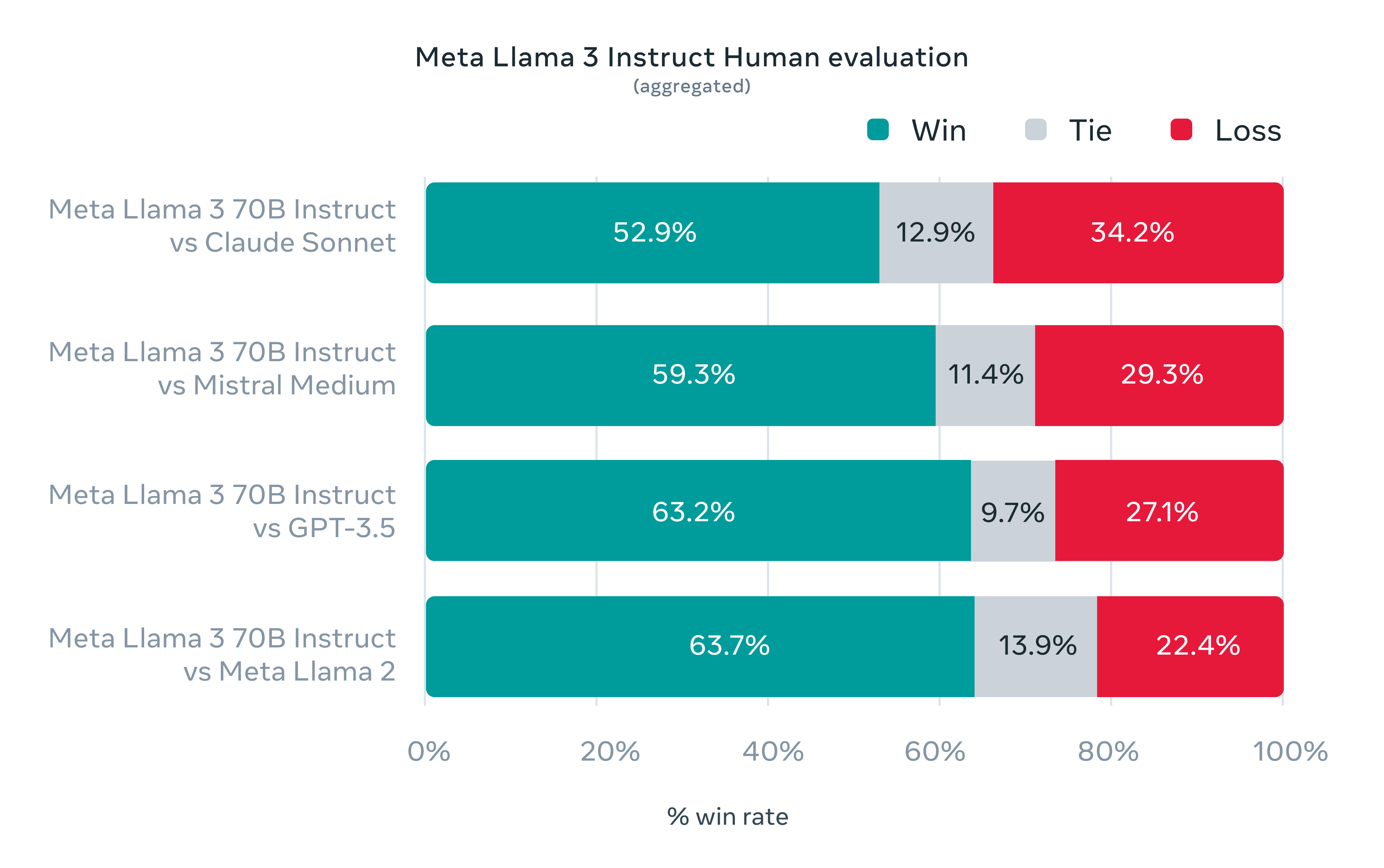
Las clasificaciones de preferencias de los anotadores humanos basadas en este conjunto de evaluaciones ponen de relieve el gran rendimiento de nuestro modelo de seguimiento de instrucciones 70B en comparación con modelos de la competencia de tamaño comparable en escenarios del mundo real.
Nuestro modelo pre-entrenado también establece un nuevo estándar para los modelos LLM a esas escalas.
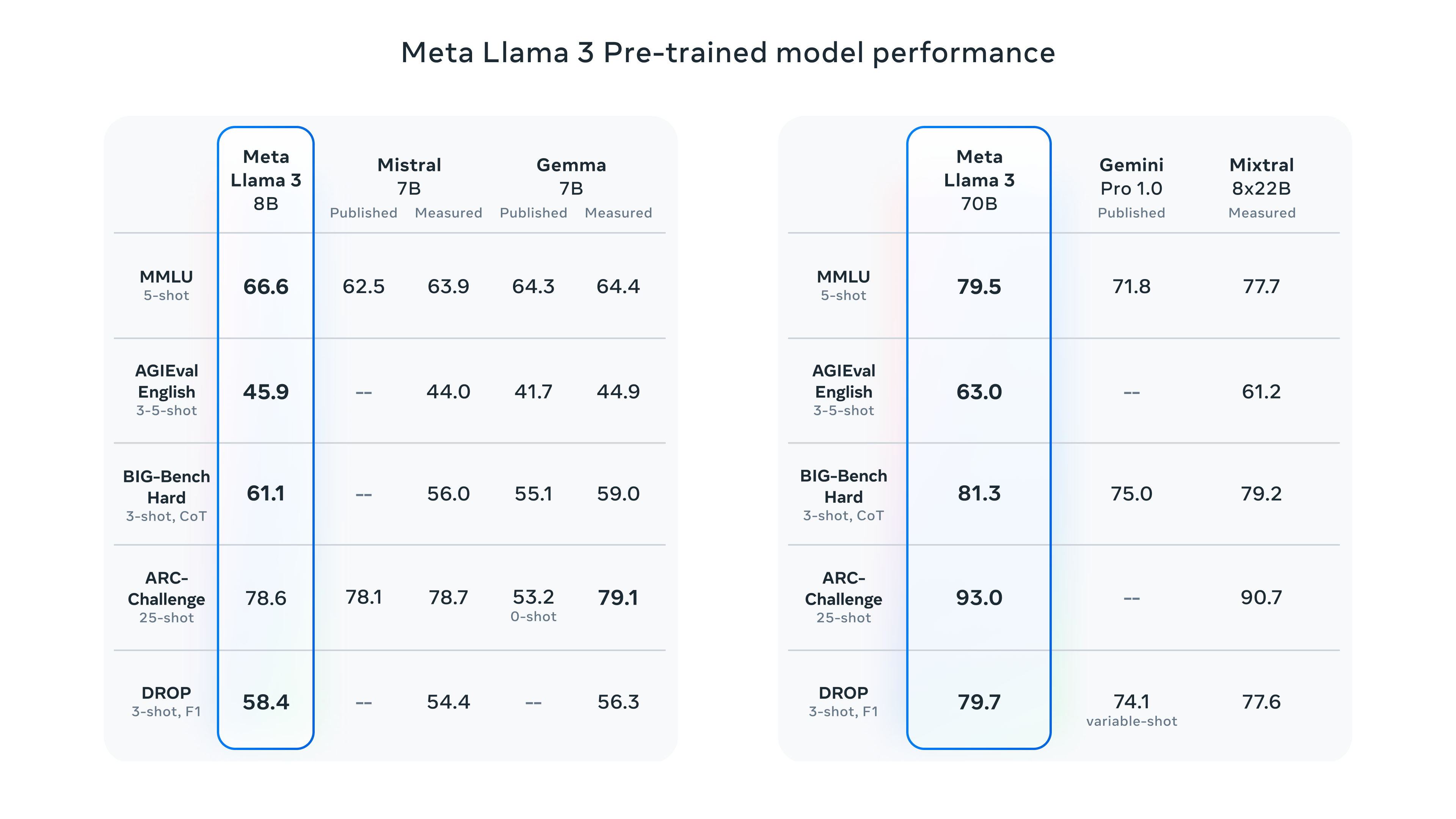
*Por favor, consulta los detalles para conocer la configuración y parámetros con los que se calculan estas evaluaciones.
Para desarrollar un gran modelo lingüístico, creemos que es importante innovar, escalar y optimizar para simplificar. Adoptamos esta filosofía de diseño a lo largo de todo el proyecto Llama 3, centrándonos en cuatro ingredientes clave: la arquitectura del modelo, los datos de pre-entrenamiento, la ampliación del pre-entrenamiento y el fine-tunning de las instrucciones.
Arquitectura del modelo
De acuerdo con nuestra filosofía de diseño, en Llama 3 hemos optado por una arquitectura de transformadores decoder-only relativamente estándar. En comparación con Llama 2, hemos introducido varias mejoras clave, por ejemplo, Llama 3 utiliza un tokenizador con un vocabulario de 128.000 tokens que codifica el lenguaje de forma mucho más eficiente, lo que mejora sustancialmente el rendimiento del modelo. Para mejorar la eficacia de inferencia de los modelos de Llama 3, hemos adoptado la atención a consultas agrupadas (GQA) en los tamaños 8B y 70B. Entrenamos los modelos en secuencias de 8.192 tokens, utilizando una máscara para garantizar que la autoatención no cruce los límites del documento.
Datos de entrenamiento
Para entrenar el mejor modelo lingüístico, es fundamental disponer de un dataset de entrenamiento amplio y de gran calidad. De acuerdo con nuestros principios de diseño, hemos invertido mucho en datos de pre-entrenamiento. Llama 3 está pre-entrenado con más de 15T de tokens recogidos de fuentes públicas. Nuestro dataset de entrenamiento es siete veces mayor que el utilizado para Llama 2 e incluye cuatro veces más código. Para prepararnos para los próximos casos de uso multilingüe, más del 5% del conjunto de datos de pre-entrenamiento de Llama 3 está formado por datos de alta calidad en lengua no inglesa que abarcan más de 30 idiomas. Sin embargo, no esperamos el mismo nivel de rendimiento en estos idiomas que en inglés.
Para asegurarnos de que Llama 3 se entrena con datos de la máxima calidad, hemos desarrollado una serie de procesos de filtrado de datos. Estos filtros incluyen filtros heurísticos, filtros NSFW, enfoques de deduplicación semántica y clasificadores de texto para predecir la calidad de los datos. Descubrimos que las generaciones anteriores de Llama son sorprendentemente buenas a la hora de identificar datos de alta calidad, por lo que utilizamos Llama 2 para generar los datos de entrenamiento de los clasificadores de calidad de texto que se utilizan en Llama 3.
También realizamos experimentos exhaustivos para evaluar las mejores formas de mezclar datos de distintas fuentes en nuestro dataset final de pre-entrenamiento. Estos experimentos nos permitieron seleccionar una combinación de datos que garantiza un buen rendimiento de Llama 3 en distintos casos de uso, como preguntas de trivialidades, STEM, codificación, conocimientos históricos, etc.
Ampliación del pre-entrenamiento
Para aprovechar de forma eficaz nuestros datos de pre-entrenamiento en los modelos de Llama 3, hemos realizado un esfuerzo considerable para ampliar el pre-entrenamiento. En concreto, hemos desarrollado una serie de leyes de escalado detalladas para las evaluaciones de referencia posteriores. Estas leyes de escalado nos permiten seleccionar una combinación óptima de datos y tomar decisiones informadas sobre cómo utilizar mejor nuestro cálculo de entrenamiento. Y lo que es más importante, las leyes de escalado nos permiten predecir el rendimiento de nuestros modelos más grandes en tareas clave (por ejemplo, la generación de código evaluada en la prueba comparativa HumanEval, véase más arriba) antes de entrenar realmente los modelos. Esto nos ayuda a garantizar un buen rendimiento de nuestros modelos finales en una gran variedad de casos de uso y funcionalidades.
Durante el desarrollo de Llama 3 hicimos varias observaciones nuevas sobre el comportamiento de escalado. Por ejemplo, mientras que la cantidad óptima de cálculo de entrenamiento de Chinchilla para un modelo de 8B parámetros corresponde a ~200B tokens, descubrimos que el rendimiento del modelo sigue mejorando incluso después de que el modelo se entrene con dos órdenes de magnitud más de datos. Nuestros modelos de 8B y 70B parámetros siguieron mejorando de forma log-lineal después de entrenarlos con hasta 15T de tokens. Los modelos más grandes pueden igualar el rendimiento de estos modelos más pequeños con menos computación de entrenamiento, pero en general se prefieren los modelos más pequeños porque son mucho más eficientes durante la inferencia.
Para entrenar los modelos más grandes de Llama 3, combinamos tres tipos de paralelización: paralelización de datos, paralelización de modelos y paralelización de canalización. Nuestra implementación más eficiente alcanza una utilización computacional de más de 400 TFLOPS por GPU cuando se entrena en 16.000 GPUs simultáneamente. Realizamos el entrenamiento en dos clusters de 24K GPU creados a medida. Para maximizar el tiempo de actividad de la GPU, hemos desarrollado un nuevo stack de entrenamiento avanzado que automatiza la detección, gestión y mantenimiento de errores. También hemos mejorado enormemente la fiabilidad del hardware y los mecanismos de detección de la corrupción silenciosa de datos, y hemos desarrollado nuevos sistemas de almacenamiento escalables que reducen la sobrecarga de los puntos de control y las reversiones. Estas mejoras se tradujeron en un tiempo de entrenamiento efectivo global de más del 95%. Combinadas, estas mejoras aumentaron la eficiencia del entrenamiento de Llama 3 en ~3x en comparación con Llama 2.
Fine-tuning de instrucciones
Para desbloquear completamente el potencial de nuestros modelos pre-entrenados en casos de uso de chat, también innovamos en nuestro enfoque para el ajuste de instrucciones. Nuestro enfoque para la post-entrenamiento es una combinación de fine-tuning supervisado (SFT), muestreo de rechazo, optimización de políticas proximales (PPO) y optimización de políticas directas (DPO). La calidad de las indicaciones que se utilizan en SFT y los rankings de preferencia que se utilizan en PPO y DPO tienen una influencia desproporcionada en el rendimiento de los modelos alineados. Algunas de nuestras mayores mejoras en la calidad del modelo provinieron de la cuidadosa curación de estos datos y de la realización de múltiples rondas de revisión de la calidad en las anotaciones proporcionadas por los evaluadores humanos.
Aprender de los rankings de preferencia a través de PPO y DPO también mejoró enormemente el rendimiento de Llama 3 en tareas de razonamiento y codificación. Descubrimos que si le haces una pregunta de razonamiento a un modelo con la que lucha para responder, el modelo a veces producirá el rastro de razonamiento correcto: el modelo sabe cómo producir la respuesta correcta, pero no sabe cómo seleccionarla. El entrenamiento en rankings de preferencia permite al modelo aprender cómo seleccionarla.
Construir con Llama 3
Nuestra visión es permitir a los desarrolladores personalizar Llama 3 para que admita casos de uso relevantes y facilite la adopción de mejores prácticas y la mejora del ecosistema abierto. Con esta versión, proporcionamos nuevas herramientas de confianza y seguridad, incluyendo componentes actualizados con Llama Guard 2 y Cybersec Eval 2, y la introducción de Code Shield, una barrera en tiempo de inferencia para filtrar el código inseguro producido por los LLM.
También hemos co-desarrollado Llama 3 con torchtune, la nueva biblioteca nativa de PyTorch para crear, ajustar y experimentar fácilmente con LLMs. torchtune proporciona recetas de entrenamiento eficientes en memoria y modificables escritas completamente en PyTorch. La biblioteca está integrada con plataformas populares como Hugging Face, Weights & Biases y EleutherAI, e incluso es compatible con Executorch para permitir que la inferencia eficiente se ejecute en una amplia variedad de dispositivos móviles y de borde. Para todo, desde la ingeniería rápida hasta el uso de Llama 3 con LangChain, disponemos de una completa guía de inicio que le llevará desde la descarga de Llama 3 hasta el despliegue a escala dentro de su aplicación de IA generativa.
Un enfoque responsable
Hemos diseñado los modelos Llama 3 para que sean lo más útiles posible, garantizando al mismo tiempo un enfoque líder en la industria para su despliegue responsable. Para lograrlo, hemos adoptado un nuevo enfoque a nivel de sistema para el desarrollo y despliegue responsables de Llama. Concebimos los modelos Llama como parte de un sistema más amplio que sitúa al desarrollador en el asiento del conductor. Los modelos Llama servirán como pieza fundamental de un sistema que los desarrolladores diseñarán teniendo en cuenta sus propios objetivos finales.
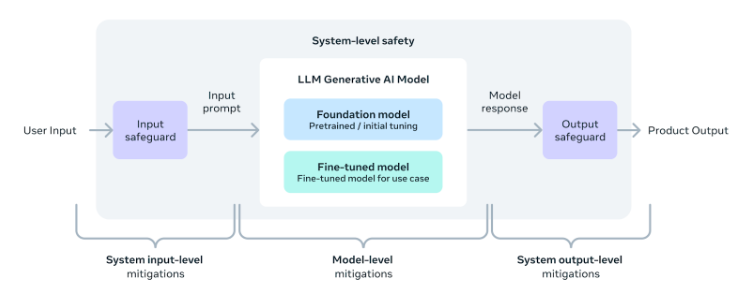
El fine-tuning de las instrucciones también desempeña un papel importante para garantizar la seguridad de nuestros modelos. La seguridad de nuestros modelos ajustados a las instrucciones se ha sometido a pruebas internas y externas. Nuestro enfoque de red teaming combina los expertos humanos y los métodos de automatización para generar mensajes adversos que intentan provocar respuestas problemáticas. Por ejemplo, aplicamos pruebas exhaustivas para evaluar los riesgos de uso indebido relacionados con la seguridad química, biológica, cibernética y otras áreas de riesgo. Todos estos esfuerzos son iterativos y se utilizan para perfeccionar la seguridad de los modelos que se publican. Puedes leer más sobre nuestros avances en la ficha del modelo.
Los modelos de Llama Guard pretenden ser una base para la seguridad rápida y de respuesta, y pueden ajustarse fácilmente para crear una nueva taxonomía en función de las necesidades de la aplicación. Como punto de partida, el nuevo Llama Guard 2 utiliza la taxonomía MLCommons recientemente anunciada, en un gesto de apoyo a la aparición de estándares industriales en esta importante área. Además, CyberSecEval 2 amplía su predecesor añadiendo medidas de la propensión de un LLM a permitir el abuso de su intérprete de código, las capacidades ofensivas de ciberseguridad y la susceptibilidad a los ataques prompt injection (obtén más información en nuestro documento técnico). Por último, presentamos Code Shield, que añade soporte para el filtrado en tiempo de inferencia del código inseguro producido por los LLM. Esto permite mitigar los riesgos relacionados con las sugerencias de código inseguro, la prevención del abuso del intérprete de código y la ejecución segura de comandos.
Con la velocidad a la que se mueve el espacio de la IA generativa, creemos que un enfoque abierto es una forma importante de unir el ecosistema y mitigar estos daños potenciales. Como parte de ello, estamos actualizando nuestra Guía de Uso Responsable (RUG) que proporciona una guía completa para el desarrollo responsable con LLMs. Como indicamos en la RUG, recomendamos que todos los inputs y outputs se comprueben y filtren de acuerdo con las directrices de contenido apropiadas para la aplicación. Además, muchos proveedores de servicios en la nube ofrecen API de moderación de contenidos y otras herramientas para un despliegue responsable, por lo que animamos a los desarrolladores a considerar también el uso de estas opciones.
Despliegue de Llama 3 a gran escala
Llama 3 pronto estará disponible en las principales plataformas, incluidos los proveedores de nube, los proveedores de API de modelos y muchos más. Llama 3 estará en todas partes.
Nuestras pruebas comparativas demuestran que el tokenizador ofrece una eficiencia mejorada de tokens, produciendo hasta un 15% menos de tokens en comparación con Llama 2. Además, ahora también se ha añadido Group Query Attention (GQA) a Llama 3 8B. Como resultado, observamos que a pesar de que el modelo tiene 1B parámetros más en comparación con Llama 2 7B, la eficiencia mejorada del tokenizador y GQA contribuyen a mantener la eficiencia de inferencia a la par con Llama 2 7B.
Para ver ejemplos de cómo aprovechar todas estas capacidades, echa un vistazo a Llama Recipes, que contiene todo nuestro código fuente abierto que se puede aprovechar para todo, desde el fine-tuning hasta el despliegue y la evaluación de modelos.
¿Cuáles son los próximos pasos para Llama 3?
Los modelos Llama 3 8B y 70B marcan el comienzo de lo que tenemos previsto lanzar para Llama 3. Y llegarán muchas más novedades.
Nuestros modelos más grandes superan los parámetros de 400B y, aunque todavía están en fase de formación, nuestro equipo está entusiasmado con su evolución. En los próximos meses, publicaremos varios modelos con nuevas funciones, como la multimodalidad, la capacidad de conversar en varios idiomas, una ventana de contexto mucho más larga y funciones generales más potentes. También publicaremos un artículo de investigación detallado una vez hayamos terminado de entrenar a Llama 3.
Para ilustrar la situación actual de estos modelos mientras siguen entrenándose, hemos pensado en compartir algunas instantáneas de la evolución de nuestro modelo LLM más grande. Ten en cuenta que estos datos se basan en un primer punto de control de Llama 3 que todavía se está entrenando y estas capacidades no son compatibles como parte de los modelos publicados hoy.
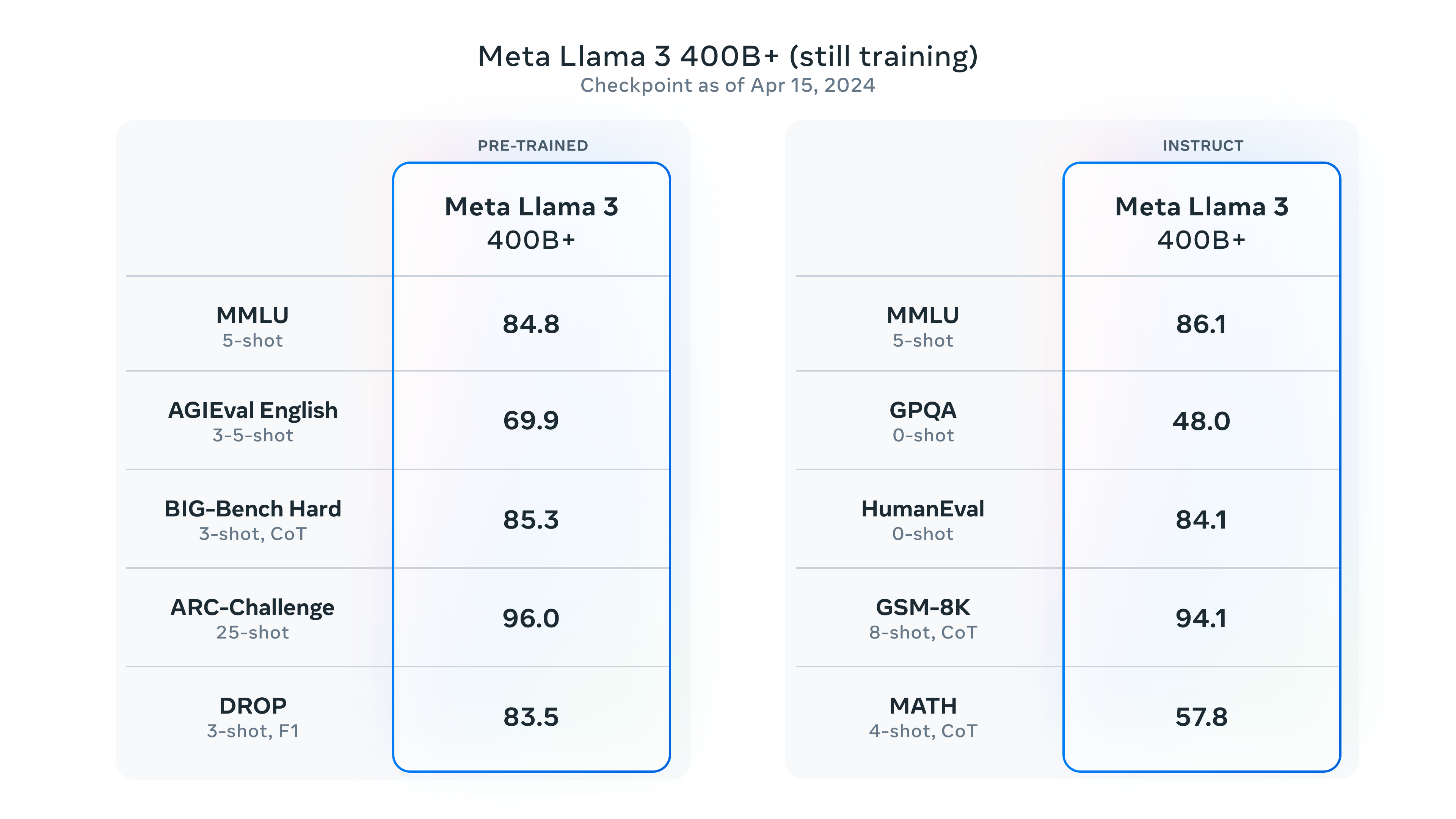
*Por favor, consulta los detalles para conocer la configuración y parámetros con los que se calculan estas evaluaciones.
Estamos comprometidos con el crecimiento y el desarrollo continuos de un ecosistema de IA abierto para liberar nuestros modelos de forma responsable. Llevamos mucho tiempo creyendo que la apertura conduce a productos mejores y más seguros, a una innovación más rápida y, en general, a un mercado global mejor. Esto es bueno para Meta y para la sociedad. Estamos adoptando un enfoque que da prioridad a la comunidad con Llama 3, y a partir de hoy, estos modelos están disponibles en las principales plataformas de nube, alojamiento y hardware, con muchas más por venir.
Meta Llama 3 hoy
Gracias a nuestros últimos avances con Meta Llama 3, también hemos anunciado la expansión internacional de Meta AI, permitiendo que más personas accedan a esta tecnología de forma gratuita a través de Facebook, Instagram, WhatsApp y Messenger en Australia, Canadá, Ghana, Jamaica, Malawi, Nueva Zelanda, Nigeria, Pakistán, Singapur, Sudáfrica, Uganda, Zambia y Zimbabue. ¡Y esto es solo el principio! Puedes leer más sobre la experiencia Meta AI aquí.
Visita la web de Llama 3 para descargar los modelos y consulta la Guía de iniciación para ver la lista actualizada de todas las plataformas disponibles.