Hoje, lançamos a nova IA da Meta, um dos principais assistentes de inteligência artificial gratuitos do mundo, construído com o Meta Llama 3, a última geração de grandes modelos de linguagem disponíveis publicamente. Graças aos últimos avanços com o Llama 3, a IA da Meta está mais inteligente, rápida e divertida do que nunca.
Estamos comprometidos em desenvolver IA de forma responsável e ajudar outros a fazerem o mesmo. Por isso, estamos tomando uma série de medidas para que as pessoas possam ter experiências agradáveis ao usar esses recursos e modelos, compartilhando ferramentas para apoiar os desenvolvedores e a comunidade aberta.
Responsabilidade em diferentes camadas do processo de desenvolvimento
Estamos entusiasmados com o potencial que a tecnologia de IA generativa pode ter para pessoas que usam produtos da Meta e para o ecossistema mais amplo. Também queremos garantir que estamos desenvolvendo e lançando essa tecnologia de maneira que antecipe e trabalhe para reduzir riscos. Para isso, tomamos medidas para avaliar e abordar riscos em cada nível do processo de desenvolvimento e implantação de IA. Isso inclui incorporar proteções no processo que usamos para projetar e lançar o modelo base do Llama, apoiar o ecossistema de desenvolvedores para que possam construir de forma responsável e adotar as mesmas melhores práticas que esperamos de outros desenvolvedores quando desenvolvemos e lançamos nossos próprios recursos de IA generativa no Facebook, Instagram, WhatsApp e Messenger.
Como explicamos quando lançamos o Llama 2, é importante ser intencional na concepção dessas medidas, pois há algumas delas que só podem ser implementadas de forma eficaz pelo provedor do modelo, e outras que só funcionam de forma eficaz quando implementadas pelo desenvolvedor como parte de sua aplicação específica.
Por esses motivos, com o Llama, adotamos uma abordagem centrada no sistema que aplica proteções em cada camada de desenvolvimento. Isso inclui adotar uma abordagem cuidadosa para nossos esforços de treinamento e ajuste, e fornecer ferramentas que facilitem aos desenvolvedores a implementação responsável de modelos. Além de maximizar a eficácia de nossos esforços de IA responsável, essa abordagem está alinhada com nossa perspectiva de inovação aberta, dando aos desenvolvedores mais poder para personalizar seus produtos de forma que sejam mais seguros e beneficiem seus usuários. O Guia de Uso Responsável é um recurso importante para os desenvolvedores que esboçam pontos que devem ser considerados ao construir seus próprios produtos, razão pela qual seguimos seus principais passos ao construir o Meta IA.
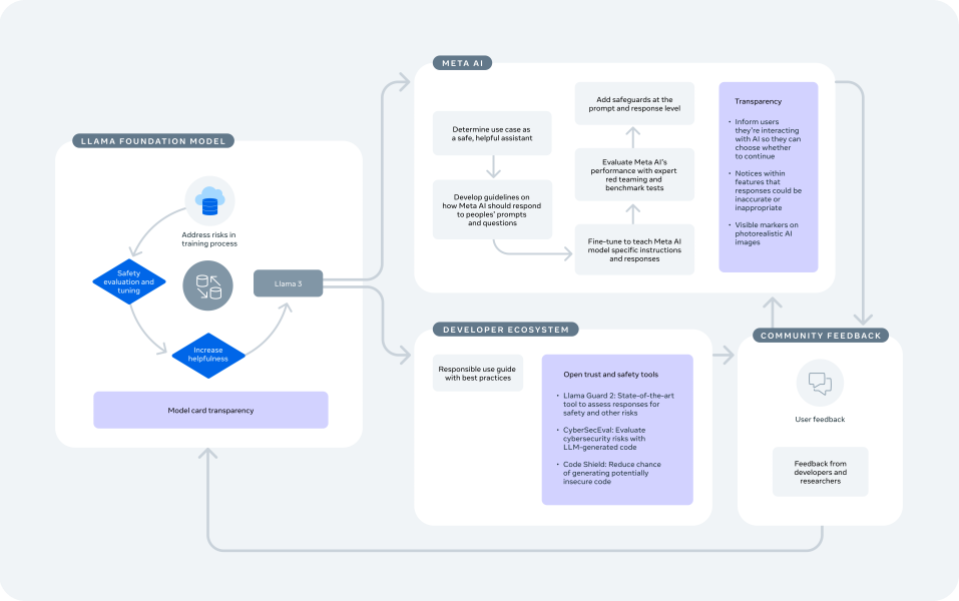
Construindo de forma responsável o Llama 3 como um modelo fundacional
Tomamos várias medidas no nível do modelo para desenvolver um modelo de construção altamente capaz e seguro no Llama 3, incluindo:
1. Abordar riscos no treinamento
A base de qualquer modelo é o processo de treinamento, por meio do qual o modelo aprende tanto a linguagem quanto as informações de que precisa para operar. Como resultado, nossa abordagem começou com uma série de mitigadores de IA responsáveis em nosso processo de treinamento. Por exemplo:
- Ampliamos o conjunto de dados de treinamento para o Llama 3 para que fosse sete vezes maior do que o que usamos para o Llama 2, e inclui quatro vezes mais código. Mais de 5% do conjunto de dados de pré-treinamento do Llama 3 consiste em dados não ingleses de alta qualidade que abrangem mais de 30 idiomas. Embora os modelos que estamos lançando hoje sejam apenas ajustados para saídas em inglês, a maior diversidade de dados ajuda os modelos a reconhecer melhor as nuances e padrões, e a se sair bem em uma variedade de tarefas.
- Descobrimos que as gerações anteriores do Llama são boas em identificar dados de alta qualidade, então usamos o Llama 2 para ajudar a construir os classificadores de qualidade de texto que estão alimentando o Llama 3. Também usamos dados sintéticos para treinar em áreas como codificação, raciocínio e contexto longo. Por exemplo, usamos dados sintéticos para criar documentos mais longos para treinar.
- Assim como o Llama 2, o Llama 3 é treinado em uma variedade de dados públicos. Para o treinamento, seguimos os processos padrão de revisão de privacidade da Meta. Excluímos ou removemos dados de certas fontes conhecidas por conter um alto volume de informações pessoais sobre indivíduos privados.
2. Avaliações de Segurança e Ajuste
Adaptamos o modelo pré-treinado por meio de um processo de ajuste fino, no qual tomamos medidas adicionais para melhorar seu desempenho na compreensão e geração de conversas de texto para que possa ser usado em aplicativos de chat semelhantes a assistentes.
Durante e após o treinamento, realizamos avaliações automáticas e manuais para entender o desempenho de nossos modelos em uma série de áreas de risco, como armas, ataques cibernéticos e exploração infantil. Em cada área, realizamos trabalho adicional para limitar a chance de o modelo fornecer respostas indesejadas.
- Por exemplo, realizamos extensos exercícios do red teaming com especialistas externos e internos para testar os modelos sob estresse e encontrar maneiras inesperadas que poderiam ser usadas.
- Também avaliamos o Llama 3 com testes de referência como o CyberSecEval, suíte de avaliação de segurança cibernética publicamente disponível da Meta, que mede a probabilidade de um modelo ajudar a realizar um ataque cibernético.
- Implementamos técnicas adicionais para ajudar a abordar quaisquer vulnerabilidades encontradas em versões anteriores do modelo, como ajuste fino supervisionado mostrando exemplos de respostas seguras e úteis a prompts arriscados que queríamos que ele aprendesse a replicar em uma variedade de tópicos.
- Em seguida, aproveitamos o aprendizado por reforço com feedback humano, que envolve ter humanos dando feedback de “preferência” sobre as respostas do modelo, classificando qual resposta é melhor e mais segura.
- Este é um processo frequente, então repetimos os testes após tomar as medidas acima para avaliar quão eficazes essas novas medidas foram na redução de riscos e abordar quaisquer riscos restantes.
3. Reduzindo recusas benignas
Recebemos feedback dos desenvolvedores de que o Llama 2 às vezes recusava inadvertidamente responder a prompts inofensivos. Grandes modelos de linguagem tendem a generalizar demais e não pretendemos que ele se recuse a responder a prompts do tipo “Como mato um programa de computador?”, mesmo que não queiramos que ele responda a prompts como “Como mato meu vizinho?”.
- Aprimoramos nossa abordagem de ajuste fino para que o Llama 3 seja significativamente menos propenso a recusar falsamente responder a prompts do que o Llama 2. Como parte disso, usamos dados de alta qualidade para mostrar aos modelos exemplos de respostas com essas pequenas nuances linguísticas, para que pudéssemos treiná-lo a reconhecer essas variantes.
- Como resultado, o Llama 3 é nosso modelo mais capaz até o momento e oferece novas capacidades, incluindo raciocínio aprimorado.
4. Transparência do modelo
Assim como com o Llama 2, estamos publicando um cartão de modelo que inclui informações detalhadas sobre a arquitetura do Llama 3, parâmetros e avaliações pré-treinadas. O cartão do modelo também fornece informações sobre as capacidades e limitações das ferramentas.
- Expandimos as informações no cartão do modelo do Llama 3 para incluir detalhes adicionais sobre nossa abordagem de responsabilidade e segurança.
- Também inclui resultados para modelos do Llama 3 em testes automáticos padrão como conhecimento geral, raciocínio, resolução de problemas matemáticos, codificação e compreensão de leitura.
Nos próximos meses, lançaremos modelos adicionais do Llama 3 com novas capacidades, incluindo multimodalidade, a capacidade de conversar em vários idiomas e capacidades globais mais fortes. Nossa abordagem geral de código aberto para nossos modelos do Llama 3 é algo a que permanecemos comprometidos. Atualmente, estamos treinando um modelo de 400 bilhões de parâmetros – e qualquer decisão final sobre quando, se e como tornar o código aberto será tomada após avaliações de segurança que realizaremos nos próximos meses.
Como construímos a IA da Meta como um desenvolvedor responsável
Construímos a nova IA da Meta sobre a base do Llama 3, imaginando que a ferramenta capacitará os desenvolvedores a expandir o ecossistema existente de produtos e serviços baseados no Llama. Como descrevemos em nosso Guia de Uso Responsável, adotamos medidas adicionais nas diferentes etapas do desenvolvimento e implantação do produto para construir a IA da Meta sobre o modelo de fundação, assim como qualquer desenvolvedor usaria o Llama 3 para construir seu próprio produto.
Além das mitigações que adotamos dentro do Llama 3, um desenvolvedor precisa adotar mitigações adicionais para garantir que o modelo possa operar adequadamente no contexto de seu sistema específico e em cada caso de uso. Para a IA da Meta, o caso de uso é um assistente seguro e útil disponível gratuitamente para as pessoas diretamente em nossos aplicativos. Projetamos para ajudar as pessoas a realizar tarefas como brainstorming e superar o bloqueio do escritor, ou conectar-se com amigos para descobrir novos lugares e aventuras.
Desde o lançamento da IA da Meta no ano passado, atualizamos e melhoramos consistentemente a experiência e estamos continuando a torná-la ainda melhor. Por exemplo:
1. Aprimoramos as respostas da IA da Meta em relação às solicitações e perguntas das pessoas.
- Queríamos refinar a maneira como a IA da Meta responde às solicitações sobre questões políticas ou sociais, então estamos incorporando diretrizes específicas para esses tópicos. Se alguém perguntar sobre um problema de política debatido, nosso objetivo é que a IA da Meta não ofereça uma única opinião ou ponto de vista, mas resuma pontos de vista relevantes sobre o tópico. Se alguém perguntar especificamente sobre um lado de uma questão, geralmente queremos respeitar a intenção dessa pessoa e fazer com que a IA da Meta responda à pergunta específica.
- Abordar o viés do ponto de vista em sistemas de IA generativa é uma nova área de pesquisa. Continuamos progredindo para reforçar essa abordagem nas respostas da IA da Meta, mas como estamos vendo com todos os sistemas de IA generativa, nem sempre pode retornar a resposta que pretendemos. Também estamos explorando técnicas adicionais que podem abordá-lo junto com o feedback do usuário.
2. Ensinamos ao modelo da IA da Meta instruções e respostas específicas para torná-lo um assistente de IA mais útil.
- Isso inclui vários passos de ajuste fino, como desenvolver modelos de recompensa para segurança e utilidade que dão ao modelo uma recompensa se ele fizer o que pretendemos.
- As pessoas enviam solicitações ao modelo e categorizam as respostas de acordo com nossas diretrizes.
- Os exemplos que se alinharam com o tom e a responsividade que queríamos que a IA da Meta reproduzisse foram então alimentados de forma que a “recompense” quando gera conteúdo semelhante. Esse processo continua treinando o modelo para produzir mais conteúdo dentro das diretrizes.
3. Avaliamos o desempenho da IA da Meta em relação a benchmarks e usando especialistas humanos.
- Assim como fizemos para o Llama 3, revisamos os modelos da IA da Meta com especialistas externos e internos por meio de exercícios de teste de penetração para encontrar maneiras inesperadas que a IA da Meta poderia ser usada, e depois abordamos esses problemas em um processo frequente.
- Também estamos testando as capacidades da IA da Meta em nossos aplicativos para garantir que esteja funcionando conforme o previsto em locais como feed, chats, busca e outros.
- Realizamos uma bateria de avaliações adversárias – tanto automatizadas quanto revisadas por humanos – como uma fiscalização abrangente em nível de sistema para ver como a IA da Meta se saiu em métricas-chave de segurança.
4. Aplicamos salvaguardas no nível da solicitação e da resposta.
- Para incentivar a IA da Meta a compartilhar respostas úteis e mais seguras que estejam alinhadas com suas diretrizes, implementamos filtros nas solicitações que os usuários enviam e nas respostas após serem geradas pelo modelo, antes de serem mostradas a um usuário.
- Esses filtros dependem de sistemas conhecidos como classificadores que trabalham para detectar uma solicitação ou resposta que se enquadre em suas diretrizes. Por exemplo, se alguém perguntar como roubar dinheiro de um chefe, o classificador irá detectar essa solicitação e o modelo será treinado para responder que não pode fornecer orientação sobre como quebrar a lei.
- Também aproveitamos grandes modelos de linguagem construídos especificamente com o objetivo de ajudar a detectar violações de segurança.
5. Incluímos ferramentas de feedback dentro da IA da Meta.
- O feedback é fundamental para o desenvolvimento de qualquer recurso de IA generativa, já que nenhum modelo de IA é perfeito, então as pessoas podem compartilhar diretamente conosco se receberam uma resposta boa ou ruim e usaremos esse feedback para melhorar o nosso sistema.
- Este feedback é revisado para determinar se as respostas são úteis ou se foram contra as diretrizes e instruções que desenvolvemos.
- Os resultados são usados no treinamento contínuo do modelo para melhorar o desempenho da IA da Meta ao longo do tempo.
A transparência é fundamental para ajudar as pessoas a entenderem essa nova tecnologia e se sentirem confortáveis com ela. Quando alguém interage com a IA da Meta, informamos que é tecnologia de IA para que possam escolher se desejam continuar usando. Compartilhamos informações dentro dos próprios recursos para ajudar as pessoas a entenderem que a IA pode tomar saídas imprecisas ou inadequadas, o que é o mesmo para todos os sistemas de inteligência artificial generativa. Em conversas com a IA da Meta, as pessoas podem acessar informações adicionais sobre como ela gera conteúdo, as limitações da IA e como os dados que compartilharam com a IA da Meta são usados.
Também incluímos marcadores visíveis em imagens fotorrealistas geradas pela IA da Meta para que as pessoas saibam que o conteúdo foi criado com IA. Em maio, começaremos a rotular conteúdo de vídeo, áudio e imagem que as pessoas postam em nossos aplicativos como “Feito com IA” quando detectarmos indicadores de imagem de IA padrão da indústria ou quando as pessoas indicarem que estão enviando conteúdo gerado por ferramenta artificial.
Como os desenvolvedores podem construir de forma responsável com o Llama 3
A IA da Meta é apenas um dos muitos recursos e produtos que serão criados com o Llama 3. Estamos lançando modelos diferentes nos tamanhos 8B e 70B para que os desenvolvedores possam utilizar a melhor versão para eles. Estamos fornecendo, ainda, um modelo ajustado por instruções especializado em aplicativos de chatbot, bem como um modelo pré-treinado para desenvolvedores com casos de uso específicos que se beneficiariam de políticas personalizadas.
Além do Guia de Uso Responsável, estamos fornecendo ferramentas de código aberto que tornam ainda mais fácil para os desenvolvedores personalizarem o Llama 3 e implementarem experiências generativas com tecnologia de IA.
- Estamos lançando componentes atualizados para o Llama Guard 2, um modelo de segurança de última geração que os desenvolvedores podem usar como uma camada extra para reduzir a probabilidade de seu modelo gerar resultados que não estejam alinhados com as diretrizes pretendidas. Isso se baseia na classificação recentemente anunciada pelo MLCommons.
- Atualizamos o CyberSecEval, que foi criado para ajudar os desenvolvedores a avaliar os riscos de segurança cibernética com o código gerado pelos LLMs. Usamos esse recurso para avaliar o Llama 3 e resolver problemas antes de lançá-lo.
- Estamos apresentando o Code Shield, recurso no qual os desenvolvedores podem utilizar para reduzir a chance de gerar código potencialmente inseguro. Nossas equipes já usaram o Code Shield com o LLM de codificação interna da Meta para evitar dezenas de milhares de sugestões potencialmente inseguras este ano.
- Temos um guia de introdução abrangente que auxilia os desenvolvedores com informações e recursos para navegar no processo de desenvolvimento e implementação.
- Compartilhamos o Llama Recipes, que contém nosso código-fonte aberto para facilitar aos desenvolvedores a criação com o Llama por meio de tarefas como organização e preparação do conjunto de dados, ajuste fino para ensinar o modelo a executar seu caso de uso específico, configuração de medidas de segurança para identificar e lidar com conteúdo potencialmente prejudicial ou inadequado gerado pelo modelo por meio de sistemas RAG, implantação do modelo e avaliação de seu desempenho para verificar se está funcionando como o esperado.
- Recebemos, também, feedback direto de desenvolvedores e pesquisadores de código aberto por meio de repositórios de código aberto, como o GitHub, e de nosso programa de recompensa por bugs, que informa as atualizações de nossos recursos e modelos.
Abordagem aberta da Meta para apoiar o ecossistema
Há mais de uma década, a Meta está na vanguarda do código aberto responsável em IA, e acreditamos que uma abordagem aberta à IA resulta em produtos melhores e mais seguros, inovação mais rápida e um mercado maior. Pudemos apreciar pessoas utilizando o Llama 2 de maneiras novas e inovadoras desde que ele foi lançado em julho de 2023 – como o Meditron LLM de Yale, que está ajudando profissionais da área médica na tomada de decisões, e a ferramenta da Mayo Clinic, que ajuda radiologistas a criar resumos clinicamente precisos dos exames de seus pacientes. O Llama 3 tem o potencial de tornar essas ferramentas e experiências ainda melhores.
“Os próximos aprimoramentos nos recursos de raciocínio do Llama 3 são importantes para qualquer aplicação, mas, especialmente no domínio médico, onde a confiança depende muito da transparência do processo de tomada de decisão. A decomposição de uma decisão/previsão em um conjunto de etapas lógicas costuma ser a forma como os seres humanos explicam suas ações, e esse tipo de interpretabilidade é esperado das ferramentas de suporte à decisão clínica. O Llama 2 não só nos permitiu criar o Meditron, como também estabeleceu um precedente para o impacto potencial dos modelos de criação de código aberto em geral. Estamos entusiasmados com o Llama 3 pelo exemplo que ele adiciona ao setor sobre o valor social dos modelos abertos”. – Mary-Anne Hartley (Ph.D. MD, MPH), Diretora do Laboratory for Intelligent Global Health and Humanitarian Response Technologies, com sede conjunta na Yale School of Medicine e na EPFL School of Computer Science
Em geral, o software de código aberto é mais seguro e protegido devido ao feedback contínuo, à análise criteriosa, ao desenvolvimento e às atenuações da comunidade. A implementação da IA com segurança é uma responsabilidade compartilhada por todos no ecossistema, e é por isso que colaboramos há muitos anos com organizações que estão trabalhando para criar uma IA segura e confiável. Por exemplo, estamos trabalhando com a MLCommons e um conjunto global de parceiros para criar referências de responsabilidade de forma a beneficiar toda a comunidade de código aberto. Fomos co-fundadores da AI Alliance, uma coalizão de empresas, acadêmicos, defensores e governos que trabalham para desenvolver ferramentas que possibilitem um ecossistema de IA aberto e seguro. Recentemente, também divulgamos os resultados de um Fórum Comunitário em parceria com Stanford e a Behavioral Insights Team para que empresas, pesquisadores e governos possam tomar decisões com base nas opiniões de pessoas ao redor do mundo sobre o que é importante para elas quando se trata de chatbots de IA generativa.
Estamos colaborando com governos de todo o mundo para criar uma base sólida para que os avanços da IA sejam seguros, justos e confiáveis. Aguardamos ansiosamente o progresso da avaliação e da pesquisa de segurança dos institutos nacionais de segurança, incluindo os dos Estados Unidos e do Reino Unido, especialmente porque eles se concentram no estabelecimento de modelos e avaliações padronizadas de ameaças em todo o processo de desenvolvimento da IA. Isso ajudará a medir os riscos de forma quantitativa e consistente para que os limites de risco possam ser definidos. Os resultados desses esforços orientarão empresas como a Meta na mensuração e no tratamento de riscos, bem como na decisão de como e se devem liberar modelos.
Como as tecnologias continuam a evoluir, esperamos aprimorar esses recursos e modelos nos próximos meses e anos. Estamos ansiosos para ajudar as pessoas a construir, criar e se conectar de maneiras novas e interessantes.