
O mundo em que vivemos nunca esteve tão interligado – a proliferação global da internet, dispositivos móveis, mídias sociais e plataformas de comunicação dão às pessoas acesso a mais conteúdo multilinguístico do que nunca. Nesse contexto, ter uma maneira de se comunicar e compreender informações em qualquer idioma torna-se cada vez mais importante. Embora tal capacidade seja sonhada há muito tempo na ficção científica, a IA está prestes a transformar isso em realidade técnica.
Hoje, apresentamos o SeamlessM4T, um modelo multilíngue e multitarefa que traduz e transcreve perfeitamente fala e texto. O SeamlessM4T oferece:
- Reconhecimento de fala em quase 100 idiomas
- Tradução de voz para texto para quase 100 idiomas, tanto de entrada e saída
- Tradução de fala para fala, para quase 100 idiomas de entrada e 35 idiomas de saída (+ o inglês)
- Tradução de texto para texto para quase 100 idiomas
- Tradução de texto para fala, com suporte para quase 100 idiomas de entrada e 35 idiomas de saída (+ o inglês)
Mantendo nossa abordagem de ciência aberta, estamos lançando publicamente o SeamlessM4T no CC BY-NC 4.0 permitindo que pesquisadores e desenvolvedores ampliem esse trabalho. Também estamos lançando metadados do SeamlessAlign, o maior conjunto de dados de tradução multimodal aberto até o momento, totalizando 270 mil horas de fala trabalhadas e alinhamentos de texto. Tornamos mais fácil para a comunidade realizar a exploração em seus próprios conjuntos de dados monolíngues com o SONAR, um conjunto completo de codificadores de frases de fala e texto, e “stopes”, nossa biblioteca para processamento de dados multimodais e mineração de dados paralela. Todos os avanços da pesquisa são apoiados pelo fairseq2, nossa biblioteca de modelos sequenciais de última geração.
É desafiador construir um tradutor de linguagem universal, como o fictício Babel Fish em O Guia do Mochileiro das Galáxias, porque os sistemas existentes de fala para fala, e fala para texto cobrem apenas uma pequena parcela dos idiomas do mundo. O SeamlessM4T representa um avanço significativo no campo da conversão de fala para fala, e de fala para texto, pois abrange os desafios da cobertura linguística limitada e da dependência de sistemas separados, que dividem a tarefa de tradução de fala para fala em vários subsistemas. Esses sistemas aproveitam essa grande quantidade de dados e geralmente funcionam bem em uma modalidade. Nosso desafio era criar um modelo multilíngue unificado que pudesse fazer tudo.
Nós acreditamos que o trabalho anunciado hoje é um passo significativo nesta jornada. Nosso modelo é único e oferece traduções sob demanda, permitindo que pessoas que falam diferentes idiomas se comuniquem de maneira mais eficaz. Melhoramos significativamente a performance dos idiomas com poucos e médios recursos que oferecemos suporte. Estas são línguas que têm pegadas linguísticas digitais menores. Também mantemos um forte desempenho em idiomas com muitos recursos, como o inglês, o espanhol e o alemão. O SeamlessM4T reconhece implicitamente os idiomas de origem, sem a necessidade de um modelo de identificação de idioma separado.
Este trabalho baseia-se nos avanços que a Meta e outras pessoas fizeram ao longo dos anos na busca por criar um tradutor universal. No ano passado, lançamos No Language Left Behind (NLLB), um modelo de tradução automática de texto para texto que suporta 200 idiomas e desde então foi integrado à Wikipédia como um de seus fornecedores de tradução. Alguns meses depois, compartilhamos uma demonstração do Universal Speech Translator, nosso primeiro sistema de tradução direta de fala para fala para Hokkien, um idioma sem um sistema de escrita amplamente utilizado. Com isso, desenvolvemos o SpeechMatrix, primeiro conjunto de dados de tradução de fala para fala multilíngue em grande escala, derivado do SpeechLASER, um avanço no aprendizado supervisionado de representação. No início deste ano, também compartilhamos o Massively Multilingual Speech, que fornece reconhecimento de fala, identificação de idioma e tecnologia de síntese de fala em mais de 1.100 idiomas. O SeamlessM4T baseia-se nas descobertas de todos esses projetos, permitindo uma experiência de tradução multilíngue e multimodal resultante de um modelo único, construído em uma ampla variedade de fontes de dados faladas e com resultados de última geração.
Nossa abordagem
Construir um modelo unificado requer um kit de ferramentas de modelagem de sequência que seja leve e facilmente combinável com outras bibliotecas modernas do ecossistema PyTorch. Nós redesenhamos o Fairseq, nosso kit de ferramentas original de modelagem de sequência e com APIs de modelagem e carregador de dados mais eficientes, o fairseq2 ajuda a potencializar a modelagem por trás do SeamlessM4T.
Para o modelo, utilizamos a arquitetura do modelo multitarefa UnitY, que é capaz de gerar diretamente texto e fala traduzidos. Esta nova arquitetura também suporta reconhecimento automático de fala, conversão de texto em texto, conversão de texto em fala, conversão de fala em texto e traduções de fala em fala que já fazem parte do modelo básico UnitY. O modelo UnitY multitarefa consiste em três componentes sequenciais principais. Os codificadores de texto e fala têm a tarefa de reconhecer entradas de fala em quase 100 idiomas. O decodificador de texto então transfere esse significado para quase 100 idiomas de texto, seguido por um modelo de texto para decodificar em unidades acústicas discretas para 36 idiomas de fala. Cada um desses componentes no UnitY multitarefa é pré-treinado por um modelo de componente para uma subtarefa de texto para texto, fala para texto e fala para fala. As unidades discretas decodificadas são então convertidas em fala usando um vocoder de unidade HiFi-GAN multilíngue.
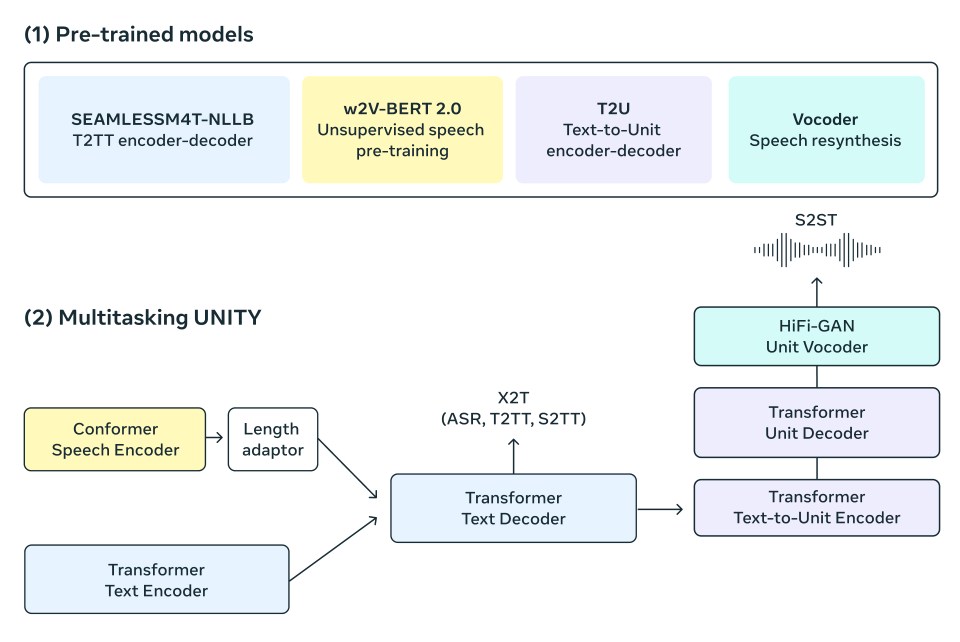
Como o codificador processa a fala
Nosso codificador de fala auto supervisionado, w2v-BERT 2.0 – que é uma versão aprimorada do w2v-BERT, melhora sua estabilidade de treinamento e qualidade de representação, aprende a encontrar estrutura e significado na fala analisando milhões de horas de fala multilíngue. O codificador pega o sinal de áudio, divide-o em partes menores e constrói uma representação interna do que está sendo dito. Como as palavras faladas são compostas por muitos desses sons e caracteres, usamos um adaptador de comprimento para mapeá-las em palavras reais.
Como o codificador processa o texto
Da mesma forma, temos um codificador de texto baseado no modelo NLLB, que foi treinado para compreender textos em quase 100 idiomas e produzir representações úteis para tradução.
Produzindo texto
Nosso decodificador de texto é treinado para receber representações de fala codificadas ou representações de texto. Isso pode ser aplicado a tarefas no mesmo idioma, como reconhecimento de fala e tarefas de uma tradução multilíngue. Por exemplo, alguém pode dizer a palavra “bonjour” em francês e esperar que o texto traduzido em suaíli seja “habari”. Com o treinamento multitarefa, aproveitamos os pontos fortes de um forte modelo de tradução de texto para texto (NLLB) para orientar nosso modelo de tradução de fala para texto por meio da destilação de conhecimento em nível de token.
Produzindo falas
Usamos unidades acústicas para representar a fala, o componente texto para unidade (T2U) no modelo UnitY gera essas unidades de fala discretas com base na saída de texto e é pré-treinado em dados ASR antes do ajuste fino da UnitY. Um vocoder de unidade HiFi-GAN multilíngue é então usado para converter essas unidades discretas em formas de onda de áudio.
Dimensionamento de dados
Os modelos baseados em dados como o SeamlessM4T geralmente se beneficiam de grandes quantidades de alta qualidade, ou seja, dados de fala para texto e de fala para fala. Depender apenas da fala humana transcrita e traduzida não é suficiente para enfrentar a desafiadora tarefa de tradução de fala para 100 idiomas. Então, nos baseamos no nosso trabalho pioneiro de mineração de texto para texto, usando uma medida de similaridade em um espaço de incorporação conjunta e no trabalho inicial na mineração de fala para criar recursos adicionais e treinar o modelo SeamlessM4T.
Primeiramente, construímos um novo espaço de incorporação de texto massivamente multilíngue e modal para 200 idiomas, denominado SONAR (Sentence-level mOdality- and laNganguage-Agnostic Representations), que supera substancialmente as abordagens existentes como LASER3 ou LaBSE na pesquisa de similaridade multilíngue. Em seguida, aplicamos uma abordagem professor-aluno para estender esse espaço de incorporação à modalidade de fala, atualmente abrangemos 36 idiomas. A mineração é realizada em dados de repositórios públicos de dados da web (dezenas de bilhões de frases) e de fala (4 milhões de horas). No total, conseguimos alinhar automaticamente mais de 443 mil horas de fala com textos e criar cerca de 29 mil horas de alinhamentos de fala para fala. Este conjunto, denominado SeamlessAlign, é o maior conjunto aberto de fala/fala e fala/texto paralelo em termos de volume total e cobertura linguística até o momento.
Resultados
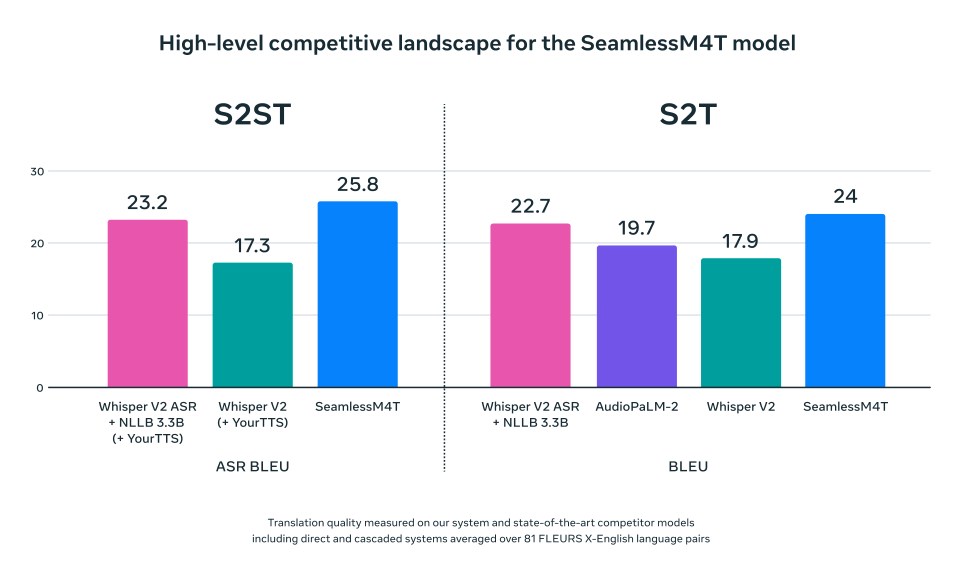
Para essas tarefas e idiomas, o SeamlessM4T alcança resultados de última geração para quase 100 idiomas e também oferece suporte multitarefa em reconhecimento automático de fala, fala para texto, fala para fala, texto para fala e texto para tradução de texto – tudo em um único modelo. Também melhoramos significativamente o desempenho para idiomas com recursos baixos e médios suportados e mantemos um forte desempenho em idiomas com recursos altos.
Para avaliar o sistema com mais precisão, sem depender de métricas baseadas em texto, estendemos nossa métrica sem texto para o BLASER 2.0, que agora permite avaliação em unidades de fala e texto com precisão semelhante em comparação com seu antecessor. Quando testado, em relação a robustez, nosso sistema tem melhor desempenho contra ruídos de fundo e variações de locutor em tarefas de fala para texto (melhorias médias de 37% e 48%, respectivamente) em comparação com o modelo atual de última geração.
O SeamlessM4T também supera concorrentes de última geração anteriores.
Como construímos o SeamlessM4T de forma responsável
É importante que os sistemas de tradução sejam precisos, mas, assim como acontece com todos os sistemas de IA, existem riscos inerentes de que o modelo possa transcrever incorretamente o que uma pessoa quer dizer ou gerar resultados tóxicos ou imprecisos.
Na Meta, nossa pesquisa e desenvolvimento de IA segue uma estrutura responsável que é guiada pelos nossos cinco pilares de IA Responsável. Em linha com o nosso compromisso com a IA responsável, conduzimos pesquisas sobre toxicidade e preconceito para nos ajudar a compreender quais áreas do modelo podem ser sensíveis. Para toxicidade, expandimos nosso classificador de toxicidade altamente multilíngue à fala, assim conseguimos identificar palavras tóxicas a partir de entradas e saídas de fala. Também filtramos a toxicidade nos dados de treinamento, pois se a entrada ou saída tivesse diferentes quantidades de toxicidade, conseguimos remover essa sequência de treinamento.
A demonstração que anunciamos hoje mostra os recursos do SeamlessM4T e é uma parte importante da pesquisa. Detectamos toxicidade tanto na entrada quanto na saída da demonstração. Caso a toxicidade for detectada apenas na saída, significa que ela foi adicionada. Neste caso, incluímos um aviso e não mostramos a saída. Ao comparar nossos modelos de última geração, reduzimos significativamente a toxicidade adicional na tradução de fala para fala e de fala para texto.
O viés de gênero, em que os resultados favorecem injustamente um deles e por vezes recorrem a estereótipos, é outra área que estamos começando a avaliar nas línguas em grande escala. No que diz respeito ao viés, investimos esforços para avaliar o viés de gênero nas línguas em grande escala. Agora somos capazes de quantificar o viés de gênero em dezenas de direções de tradução de fala, por meio do nosso conjunto de dados Multilingual HolisticBias, previamente projetado para a fala.
Nosso trabalho em torno da segurança e proteção é um esforço contínuo. Continuaremos pesquisando e tomando medidas nesta área para melhorar continuamente o SeamlessM4T e reduzir quaisquer casos de toxicidade que vemos no modelo.
Fornecendo acesso à nossa tecnologia
Com resultados de última geração, acreditamos que o SeamlessM4T é um avanço importante na busca da comunidade de IA para criar sistemas multitarefa universais. Mantendo nossa abordagem à ciência aberta, estamos animados para compartilhar publicamente nosso modelo e permitir que pesquisadores e desenvolvedores explorem essa tecnologia.
Este é apenas o passo mais recente em nosso esforço contínuo para criar uma tecnologia baseada em IA que ajude a conectar pessoas em vários idiomas. No futuro, queremos explorar como este modelo fundamental pode permitir novas capacidades de comunicação, nos aproximando de um mundo onde todos podem ser compreendidos.