Quando as pessoas navegam por seu Feed de Notícias no Facebook, elas encontram diversos tipos de conteúdo — artigos, comentários de amigos, convites para eventos e, claro, fotos. A maioria das pessoas consegue ver instantaneamente o que está nessas imagens, seja o registro de seu novo neto, um barco em um rio ou a imagem granulada de uma banda no palco. Mas muitos usuários com deficiência visual também podem experienciar essas imagens, desde que sejam marcadas devidamente com texto alternativo (ou “texto alt.”). Um leitor de tela pode descrever o conteúdo dessas imagens usando uma voz sintética e permitir que as pessoas com deficiência visual entendam as imagens em seu Feed do Facebook.
Infelizmente, muitas fotos são postadas sem texto alternativo, então, em 2016, introduzimos uma nova tecnologia chamada Texto Alternativo Automático (AAT, na sigla em inglês). O AAT — que foi reconhecido em 2018 com o prêmio Helen Keller Achievement da American Foundation for the Blind — utiliza reconhecimento de objetos para gerar descrições de fotos sob demanda, para que pessoas cegas ou com deficiência visual possam aproveitar mais plenamente seu Feed de Notícias. Temos melhorado desde então e estamos ansiosos para revelar a próxima geração de AAT.
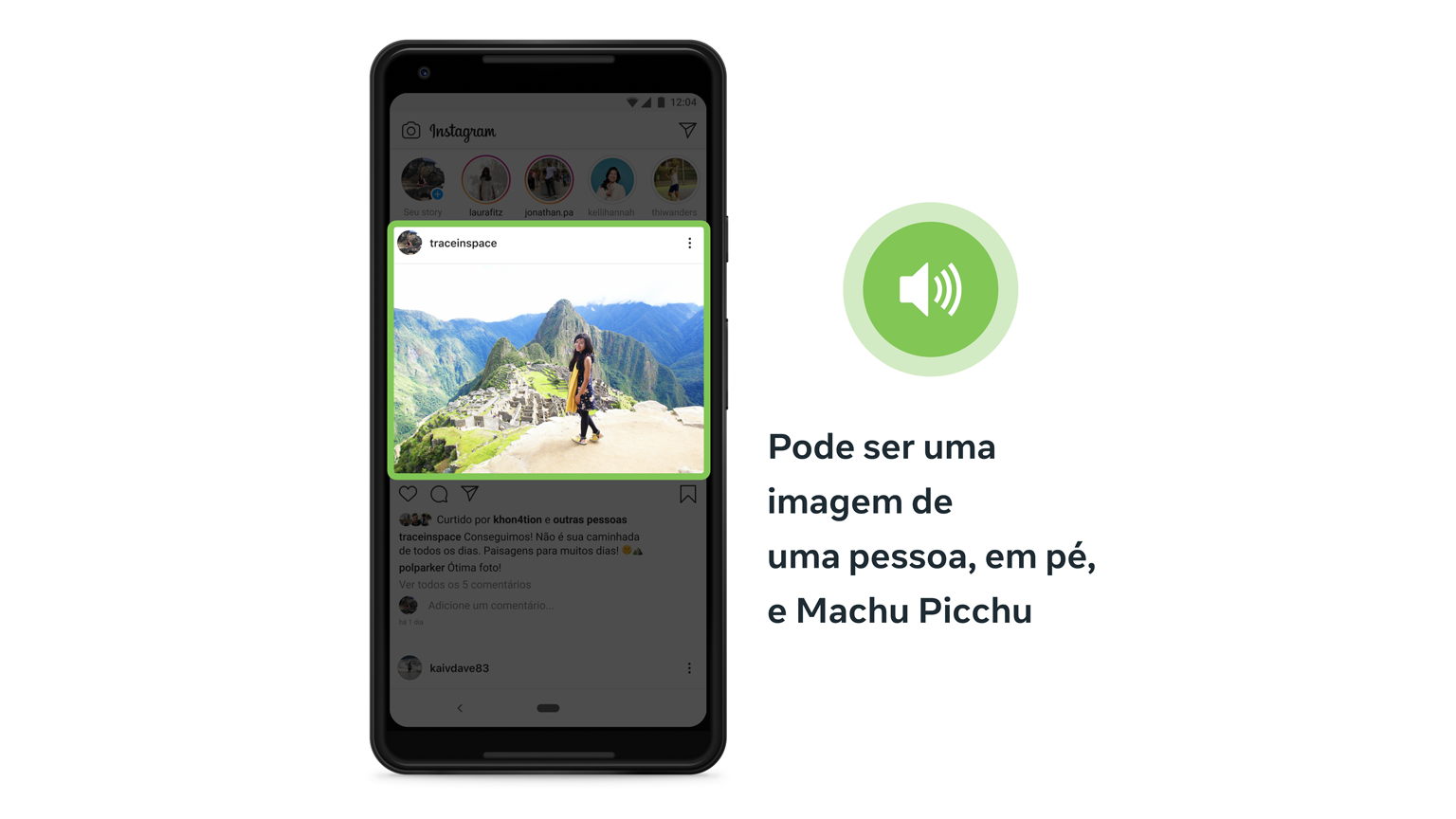
A nova versão do AAT representa vários avanços tecnológicos que aprimoram a experiência em fotos de nossos usuários. Em primeiro lugar, expandimos em mais de 10 vezes o número de objetos que o AAT pode detectar e identificar de forma confiável em uma foto, o que significa menos fotos sem uma descrição. As descrições também são mais detalhadas, com a capacidade de identificar atividades, pontos de referência, tipos de animais e assim por diante — por exemplo: “Pode ser uma selfie de 2 pessoas, ao ar livre, na Torre de Pisa”.
E alcançamos o primeiro lugar no setor ao possibilitar a inclusão de informações sobre a localização posicional e o tamanho relativo dos elementos em uma foto. Portanto, em vez de descrever o conteúdo de uma foto como “Pode ser uma imagem de 5 pessoas”, podemos especificar que há duas pessoas no centro da foto e outras três espalhadas nas bordas, o que implicaria que as duas no centro são o foco. Ou em vez de simplesmente descrever uma bela paisagem com “Pode ser uma casa e uma montanha”, podemos destacar que a montanha é o objeto principal em uma cena, com base em quão grande ela parece comparada à casa em sua base.
Juntos, esses avanços ajudam os usuários com deficiência visual a entender melhor o que há nas fotos publicadas por familiares e amigos — e em suas próprias fotos — fornecendo mais (e mais detalhadas) informações.
Onde começamos
O conceito de “texto alternativo” remonta aos primórdios da Internet, quando conexões dial-up lentas tinham uma alternativa de texto para download de imagens que exigiam muita largura de banda. Naturalmente, o texto alternativo também ajudou as pessoas com deficiência visual a navegar na internet, uma vez que pode ser usado por um software leitor de tela para gerar descrições de imagens faladas. Infelizmente, as velocidades mais rápidas de Internet tornaram o texto alternativo uma prioridade menor para muitos usuários. E como essas descrições precisavam ser adicionadas manualmente por quem carregou uma imagem, muitas fotos começaram a não apresentar nenhum texto alternativo — sem recurso para as pessoas que contavam com ele.
Há cerca de cinco anos, aproveitamos a expertise em visão computacional do Facebook para ajudar a resolver esse problema. A primeira versão do AAT foi desenvolvida usando dados rotulados por humanos, com os quais treinamos uma rede neural convolucional profunda usando milhões de exemplos de forma supervisionada. Nosso modelo AAT concluído poderia reconhecer 100 conceitos comuns, como “árvore”, “montanha” e “ao ar livre”. E como os usuários do Facebook costumam compartilhar fotos de amigos e familiares, nossas descrições de AAT usavam modelos de reconhecimento facial que identificavam pessoas (contanto que essas pessoas dessem consentimento explicitamente). Para os usuários com deficiência visual, este foi um grande avanço.
Enxergando mais do mundo
Mas sabíamos que o AAT poderia fazer mais, e o próximo passo lógico era expandir o número de objetos reconhecíveis e refinar como os descrevemos.
Para alcançar isso, abandonamos o aprendizado totalmente supervisionado com dados rotulados por humanos. Embora esse método forneça precisão, o tempo e o esforço envolvidos na rotulagem de dados são extremamente altos — e por que nosso modelo AAT original reconhecia apenas 100 objetos de forma confiável. Reconhecendo que essa abordagem não seria escalável, precisávamos de um novo caminho a seguir.
Para a versão mais atualizada do AAT, maximizamos um modelo treinado em dados parcialmente supervisionados na forma de bilhões de imagens públicas do Instagram e suas hashtags. Para fazer nossos modelos funcionarem melhor para todos, nós os ajustamos para que os dados se tornassem amostras a partir de imagens em todas as geografias, e usando traduções de hashtags em muitos idiomas. Também avaliamos nossos conceitos sobre gênero, tom de pele e idade. Os modelos resultantes são mais precisos, além de cultural e demograficamente inclusivos — por exemplo, eles podem identificar casamentos em todo o mundo com base (em parte) em trajes tradicionais, em vez de rotular apenas fotos com vestidos de noiva brancos.
Isso também nos deu a capacidade de reaproveitar mais prontamente os modelos de aprendizado de máquina como o ponto de partida para o treinamento em novas tarefas – um processo conhecido como aprendizado por transferência. Isso nos permitiu criar modelos que identificaram conceitos como monumentos nacionais, tipos de comida (como arroz frito e batatas fritas) e selfies. Todo esse processo não teria sido possível no passado.
Para obter informações mais ricas como posição e contagens, também treinamos um detector de objetos de dois estágios, o Faster R-CNN, usando Detectron2, uma plataforma de código aberto para detecção e segmentação de objetos desenvolvida pelo Facebook AI Research. Treinamos os modelos para prever localizações e rótulos semânticos dos objetos em uma imagem. Técnicas de treinamento com múltiplos rótulos/conjuntos de dados múltiplos ajudaram a tornar nosso modelo mais confiável com o espaço de rótulo maior.
A versão melhorada do AAT reconhece de forma confiável mais de 1.200 conceitos — 10 vezes mais que a versão original que lançamos em 2016. Conforme consultamos os usuários de leitores de tela sobre o AAT e como melhor aprimorá-lo, eles deixaram claro que a precisão é primordial. Para isso, incluímos apenas conceitos em que poderíamos garantir modelos bem treinados que atendessem a um certo alto patamar de precisão. Embora haja uma margem de erro, e por isso começamos todas as descrições com “Pode ser”, elevamos a régua e omitimos intencionalmente conceitos que não podíamos identificar de forma confiável.
Queremos dar aos nossos usuários cegos e com deficiência visual o máximo de informações possível sobre o conteúdo de uma foto — mas informações corretas.
Entregando detalhes
Tendo aumentado o número de objetos reconhecidos, mantendo um alto nível de precisão, voltamos nossa atenção para descobrir a melhor forma de descrever o que encontramos em uma foto.
Perguntamos aos usuários que dependem de leitores de tela quantas informações eles queriam ouvir e quando eles queriam ouvi-las. Eles queriam mais informações quando uma imagem era de amigos ou familiares, e menos quando não era. Projetamos o novo AAT para fornecer uma descrição sucinta para todas as fotos por padrão, mas oferecer uma maneira fácil de solicitar mais detalhes em fotos de interesse específico.
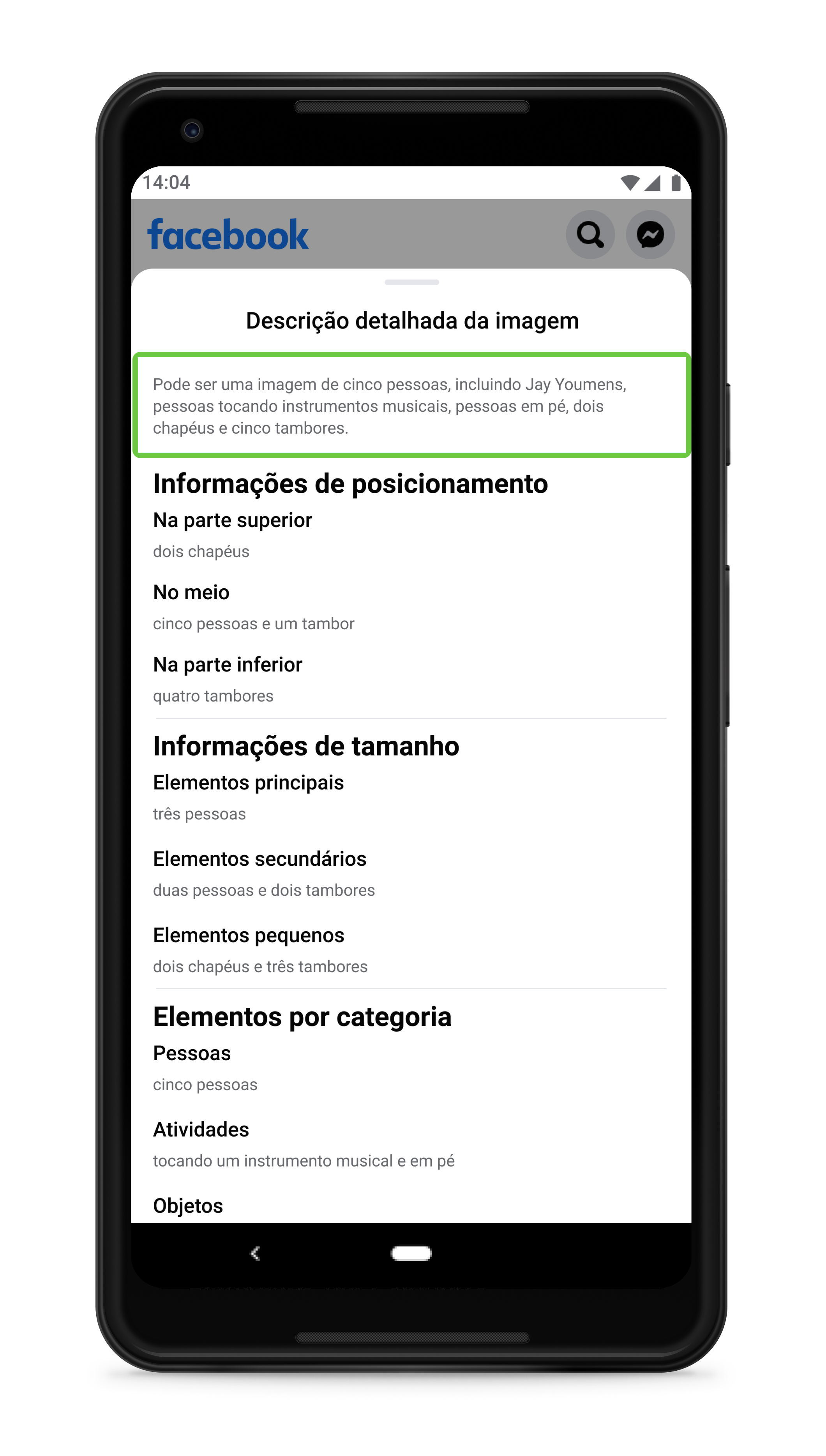 Quando os usuários selecionam essa última opção, é apresentado um painel que fornece uma descrição mais abrangente do conteúdo de uma foto, incluindo uma contagem dos elementos na foto, alguns dos quais podem não ter sido mencionados na descrição padrão. Descrições detalhadas também incluem informações posicionais simples — superior/no meio/inferior ou esquerda/centro/direita — e uma comparação da proeminência relativa dos objetos, descrita como “primários”, “secundários” ou “minoritário”. Essas palavras foram especificamente escolhidas para minimizar a ambiguidade. Feedbacks sobre a ferramenta durante o desenvolvimento mostraram que usar uma palavra como “grande” para descrever um objeto pode ser confuso porque não está claro se a referência é ao seu tamanho real ou em relação a outros objetos em uma imagem. Até um chihuahua parece grande se for fotografado de perto!
Quando os usuários selecionam essa última opção, é apresentado um painel que fornece uma descrição mais abrangente do conteúdo de uma foto, incluindo uma contagem dos elementos na foto, alguns dos quais podem não ter sido mencionados na descrição padrão. Descrições detalhadas também incluem informações posicionais simples — superior/no meio/inferior ou esquerda/centro/direita — e uma comparação da proeminência relativa dos objetos, descrita como “primários”, “secundários” ou “minoritário”. Essas palavras foram especificamente escolhidas para minimizar a ambiguidade. Feedbacks sobre a ferramenta durante o desenvolvimento mostraram que usar uma palavra como “grande” para descrever um objeto pode ser confuso porque não está claro se a referência é ao seu tamanho real ou em relação a outros objetos em uma imagem. Até um chihuahua parece grande se for fotografado de perto!
O AAT usa frases simples para a descrição padrão, em vez de uma frase longa e fluida. Não é poético, mas é altamente funcional. Nossos usuários podem obter a descrição de maneira ágil — e isso nos permite traduzir fácil e rapidamente nossas descrições de texto alternativo em 45 idiomas diferentes, incluindo em português, garantindo que o AAT seja útil para pessoas em todo o mundo.
O Facebook é para todo mundo
Todos os dias, nossos usuários compartilham bilhões de fotos. A onipresença de câmeras acessíveis em telefones celulares, conexões sem fio rápidas e mídias sociais como Instagram e Facebook tornaram mais fácil capturar e compartilhar fotografias, sendo uma das formas mais populares para se comunicar — inclusive para pessoas cegas e com deficiência visual. Embora desejemos que todos que publiquem uma foto incluam uma descrição em texto alternativo, reconhecemos que isso geralmente não acontece. Construímos o AAT para preencher essa lacuna, e o impacto que isso tem sobre aqueles que precisam é incomensurável. A IA promete avanços extraordinários e estamos entusiasmados com a oportunidade de levar esses avanços às comunidades que, muitas vezes, são mal atendidas.